【AI 大模型】RAG 检索增强生成 ① ( 大模型的相关问题描述 - 幻觉、时效性、数据安全 | RAG 检索增强生成 | RAG 关键组件 | LLM + RAG 的运行流程 )
CSDN 2024-08-08 14:31:01 阅读 77
文章目录
一、大模型的相关问题描述1、大模型 " 幻觉 " 问题描述2、大模型 " 时效性 " 问题描述3、大模型 " 数据安全 " 问题描述
二、RAG 检索增强生成1、RAG 引入2、RAG 关键组件3、LLM + RAG 的运行流程

一、大模型的相关问题描述
1、大模型 " 幻觉 " 问题描述
AI 大模型 不知道 ① 实时性的信息 或 ② 特定领域的私有信息 , 如果在私有场景中向 大模型 提问 相关问题 , 大模型训练时没有接触过这些知识 , 就会随机生成错误输出 ;
ChatGPT 产生 " 幻觉 " 的 案例 ,
目前 ChatGPT 免费版本 使用的是 ChatGPT 4o mini 模型 , 其 训练数据时 2022 年初收集的 , 之后的实时信息是没有的 , 向 ChatGPT 大模型 提问 " Meta 发布的 Llama3 怎么样 " , 大模型时回答不上来的 , 因为 Llama3 是最近刚发布的 ;
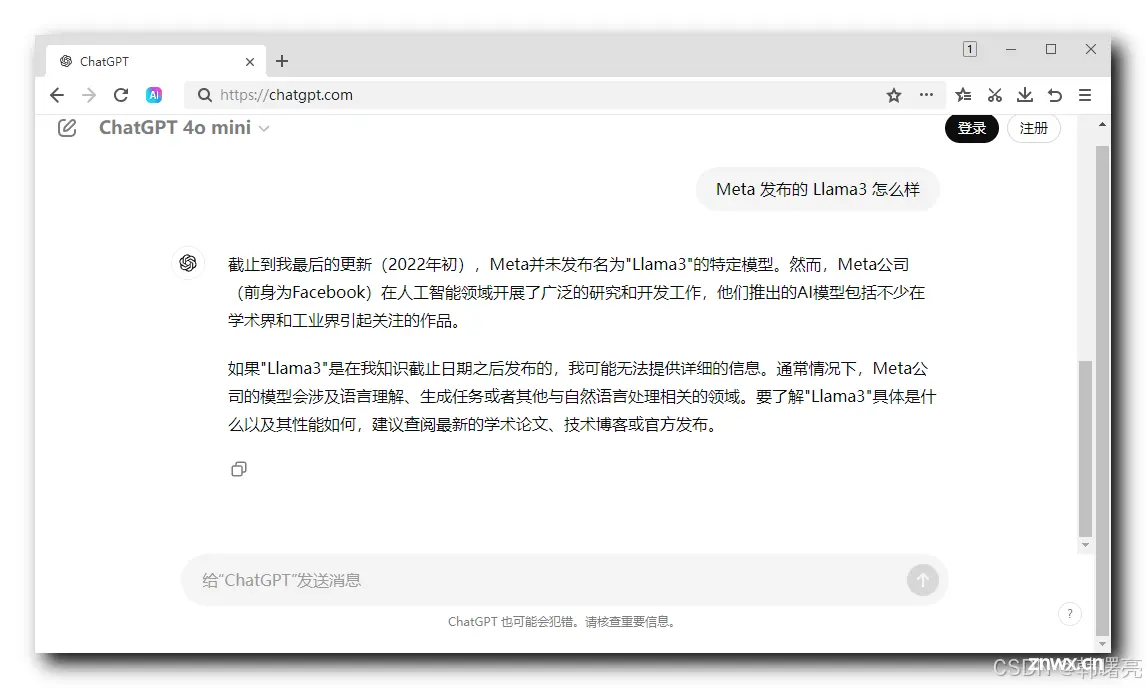
再问 ChatGPT 一次 , 第二次 在 ChatGPT 输入框中输入 " Meta 发布的 Llama3 怎么样 " , 结果得到了新的答案 ;

ChatGPT 你是知道 还是 不知道 , 出现了幻觉 , 这就是 LLM 随机生成文本 造成的 " 幻觉 " 问题 , 对于不知道的知识 , 无法生成准确的答案 , 基本都是胡说八道 ;
为了解决上述问题 , 通过 检索 的手段将大模型不知道的知识或信息 , 动态的补充到大模型中 , 具体操作就是 将 这些知识或信息 存放到 向量数据库 ( 知识库 ) 中 ;
大模型 如果 遇到 不知道的知识 , 就回到 知识库 中去查询 , 然后再生成输出文本 ;
这套机制就是 RAG , 事实上 GPT 大模型内置了 RAG 功能 ;
2、大模型 " 时效性 " 问题描述
大语言模型 的 数据更新经常是滞后的 , LLM 的 训练数据 通常是基于过去的信息 ,
如 : GPT3.5 的 数据 截止到 2022 年 1 月 , 收集数据完成后 , 训练半年 , 在 2022 年 7 月推出 该模型 ,
这导致 LLM 大语言模型 总是无法实时 地反映当前的事件和信息 ;
哪怕是 OpenAI 最新的 GPT 大模型 GPT-4o , 这是 OpenAI 在2024 年发布的旗舰模型 , 其 训练数据 截止时间是 2023 年 10 月 , 到现在 2024 年 8 月 , 将近 10 个月的最新信息 , GPT-4o 模型 是不知道的 ;
大语言模型 的 实时需求难以满足 , 对于需要及时更新的任务 , 如 : 最新的新闻、市场变化或实时事件的分析 , 大型模型可能无法提供即时和精确的答案 , 因为它们的训练数据不包含最新的信息 ;
3、大模型 " 数据安全 " 问题描述
大语言 需要大量的 训练数据 , 这些数据可能包含 个人身份信息、商业敏感数据等 ;
如果 这些 隐私数据 未经适当保护地上传到云端或公共服务器 , 存在泄露和滥用的风险 ;
在一些国家和行业中 , 将敏感数据上传到 外部的云端服务 可能 违反法律或行业规定 , 特别是涉及医疗健康、金融或个人隐私的数据 ;
大语言模型 训练时 , 不能使用 个人隐私数据、商业敏感信息、保密信息 等数据 , 因此 在 进行提问时 , 大模型 可能无法 回答出上述问题 ;
通过 本地部署的 RAG , 可以解决上述问题 , 将 个人隐私数据、商业敏感信息、保密信息 等数据 保存在本地 , 然后 将 本地检索出的 数据 + 用户问题 组合成提示词 , 传递给在本地部署的大模型 , 就可以解决 大模型的 数据安全 问题 ;
二、RAG 检索增强生成
1、RAG 引入
RAG 的 英文全称 " Retrieval Augmented Generation " , 检索增强生成 ;
RAG 通过 检索模型 从 外部数据源 中检索相关信息 , 同时将这些信息作为 上下文 提供给生成模型 , 以生成 更加准确 的回答 ;
RAG 模型 能够 有效缓解 LLM ( Large Language Models , 大预言模型 ) 在 处理 知识密集型 任务 时可能出现的 " 幻觉 " 问题 ,
" 幻觉 " 指的是 生成的 文本 看似合理 , 但实际上错误百出 , 这是基于概率生成的文本 , 同时提高生成内容的透明度和可靠性
RAG 是一种结合了 检索 和 生成 的 人工智能模型架构 , 其解决 生成模型 在生成文本任务中可能遇到的 信息获取 和 内容准确性 的问题 ;
2、RAG 关键组件
RAG 模型 有 两个关键组件 :
检索器 Retriever : 这是 专门用于 从 大型知识库 中 检索相关信息的组件 , 检索器可以使用 各种技术 来快速地找到 与当前生成任务相关的文本片段 或 文档 ;
倒排索引 : 是一种数据结构 , 用于存储在文本数据中 词项 与其 出现位置之间的 映射关系 , 是现代搜索引擎中最基础、最核心的技术之一 ;BM25 ( Best Matching 25 ) : 是一种评分函数 , 用于衡量查询与文档之间匹配程度的算法 , 也是信息检索领域中常用的一种评分模型 ; 生成器 Generator : 就是 GPT 大模型 ; 生成器 的作用是 根据 检索器 提供的 信息 + 原来的提问 组合成新的 提示词 , 输入到大模型中 来生成最终的文本输出 ;
RAG 模型 在工作时 , 先试用 检索器 进行检索 , 然后试用 生成器 生成文本 ;
检索阶段 : 检索器 根据 当前任务 和 上下文 , 从 知识库 中找到最相关的几篇文章或文本段落 ;生成阶段 : 生成器 使用 检索器 提供的信息 , 结合上下文和任务要求 , 生成最终的文本输出 ;
3、LLM + RAG 的运行流程
LLM + RAG 的运行流程 :
预处理阶段 : 用户 向 LLM 大语言模型 问出了一个问题 ;
如果 LLM 直到答案 , 直接输出 ;知识库检索 : 如果 LLM 不知道答案 , 那么就去查询 RAG 知识库 , 从 知识库 中 检索相关的 知识 ; 生成 Prompt 提示词 : 将 用户的 初始问题 和 知识库 检索出来的信息 , 拼接成一个 Prompt 提示词 , 然后 再 提交给 LLM 大预言模型 ;生成文本 : LLM 接收 提示词 , 输出 正确的 文本 ;

LLM 大语言模型 不知道 用户 提出的问题答案 , 从 本地知识库 中 找到了 相关的知识信息 , 可以在一定程度上抑制 LLM 的 " 幻觉 " , 不会随机生成错误文本 ;
参考资料 :
大模型系列——解读RAG大模型+RAG,全面介绍!纯干货全面解读AI框架RAGAI大模型:RAG入门及实践带你全面了解 RAG,深入探讨其核心范式、关键技术及未来趋势!一文读懂:大模型RAG(检索增强生成)大模型RAG入门及实践
上一篇: 快手「可灵」爆火:海外AI圈巨震,中国版Sora一号难求
下一篇: 探索腾讯云AI代码助手的效能与实用性
本文标签
【AI 大模型】RAG 检索增强生成 ① ( 大模型的相关问题描述 - 幻觉、时效性、数据安全 | RAG 检索增强生成 | RAG 关键组件 | LLM + RAG 的运行流程 )
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。