AI驱动TDSQL-C Serverless 数据库技术实战营-10分钟做一个旅游攻略分析小助手
心有余悸777 2024-10-25 14:01:01 阅读 62
目录
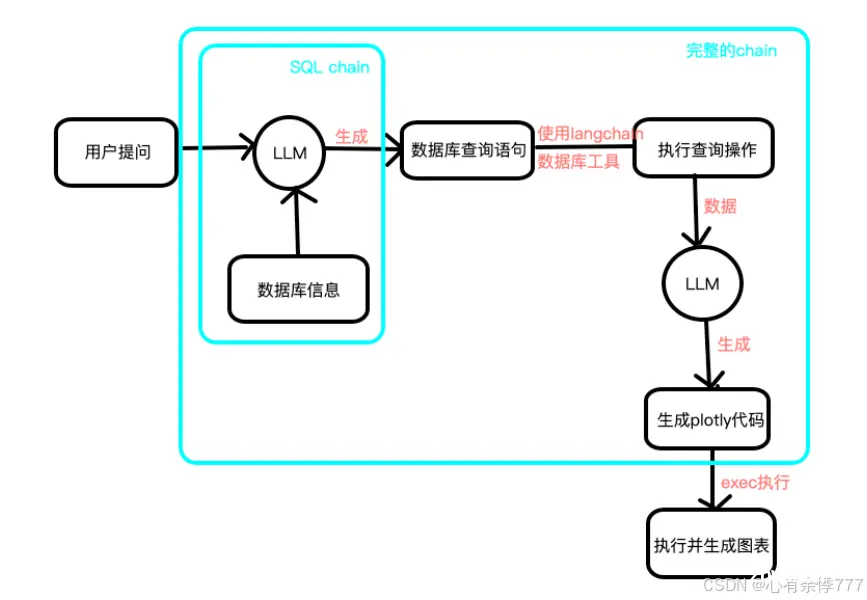
一、背景介绍
二、效果展示
三、程序流程图
四、环境搭建
购买 TDSQL-C Mysql Serverless 实例
部署HAI高算力服务器
云端python环境搭建
应用开发
五、清理资源
删除TDSQL-C Serverless
删除 HAI 算力
六、体验感受
一、背景介绍
许多人已经习惯了通过AI交互来完成更多的日常任务,苹果的Siri、小米的小爱同学、华为的小艺,AI助手们利用自然语言处理技术,通过指令帮助用户查询天气、设置闹钟、发送短信等。所以就导致这次国庆原本期待的悠闲度假变成了在人海中的艰难穿梭,毕竟AI提供的旅行规划,往往是基于大数据搜索总结出的大多数人的推荐。一些小众或新奇的体验,由于信息过少,AI很难把它们作为“标准答案”提供出来。当所有人都按照 AI 的规划走时,就会出现网红景点变成了人挤人的 ‘打卡’,一些同样美不胜收的小众景点却无人问津。
没办法,数据源太少,因为极少的App会把自身的API接口开放给别人使用,导致现有的App各自为政,像是一座座孤岛,尽管每个APP都有其独特的优势和功能,但它们之间缺乏有效的联动和整合。针对AI本身存在的技术缺陷,我会带大家用10分钟搭建一个数据库是用AI驱动的旅游攻略小助手,帮助大家在下一次假期来临之前避坑。
本文我会详细指导大家如何利用腾讯云的高性能应用服务 <code>HAI 和TDSQL-C MySQL Serverless 版构建 AI旅游数据分析系统。HAI作为一个面向AI和科学计算的GPU应用服务产品,提供了强大的计算能力,使得复杂AI模型如LLM的快速部署和运行成为可能,进而支持自然语言处理和图像生成等高级任务。与此同时,TDSQL-C MySQL版作为一款云原生关系型数据库,其100%的MySQL兼容性,以及极致的弹性、高性能和高可用性,使其成为处理海量数据存储和查询的理想选择。
本文将通过 Python 编程语言和基于 Langchain 的框架,逐步引导开发者完成系统的构建和部署。
二、效果展示



三、程序流程图
四、环境搭建
购买 TDSQL-C Mysql Serverless 实例
如果没有使用过腾讯的云原生数据库的小伙伴可以先看一下链接介绍
TDSQL-C MySQL 版-文档中心-腾讯云 (tencent.com)
点击链接如果不喜欢看文字介绍的话可以看一个2分钟的介绍视频,看完之后不会操作的没关系,可以直接跟着我的操作走就行。
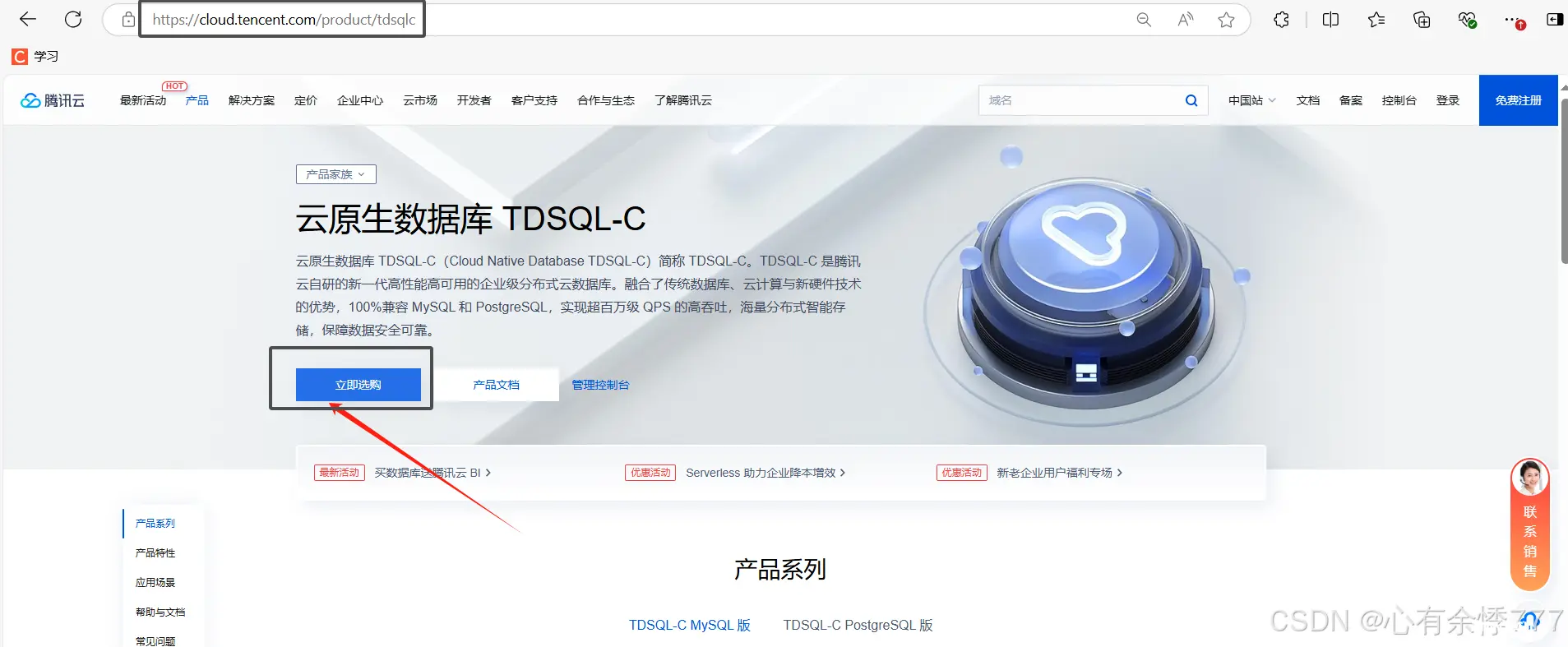
1.访问腾讯云官网申请 <code>TDSQL-C Mysql 服务器
链接:https://cloud.tencent.com/product/tdsqlc

2.根据图表选择选定服务器
选定的服务器为 <code>serverless 的服务器

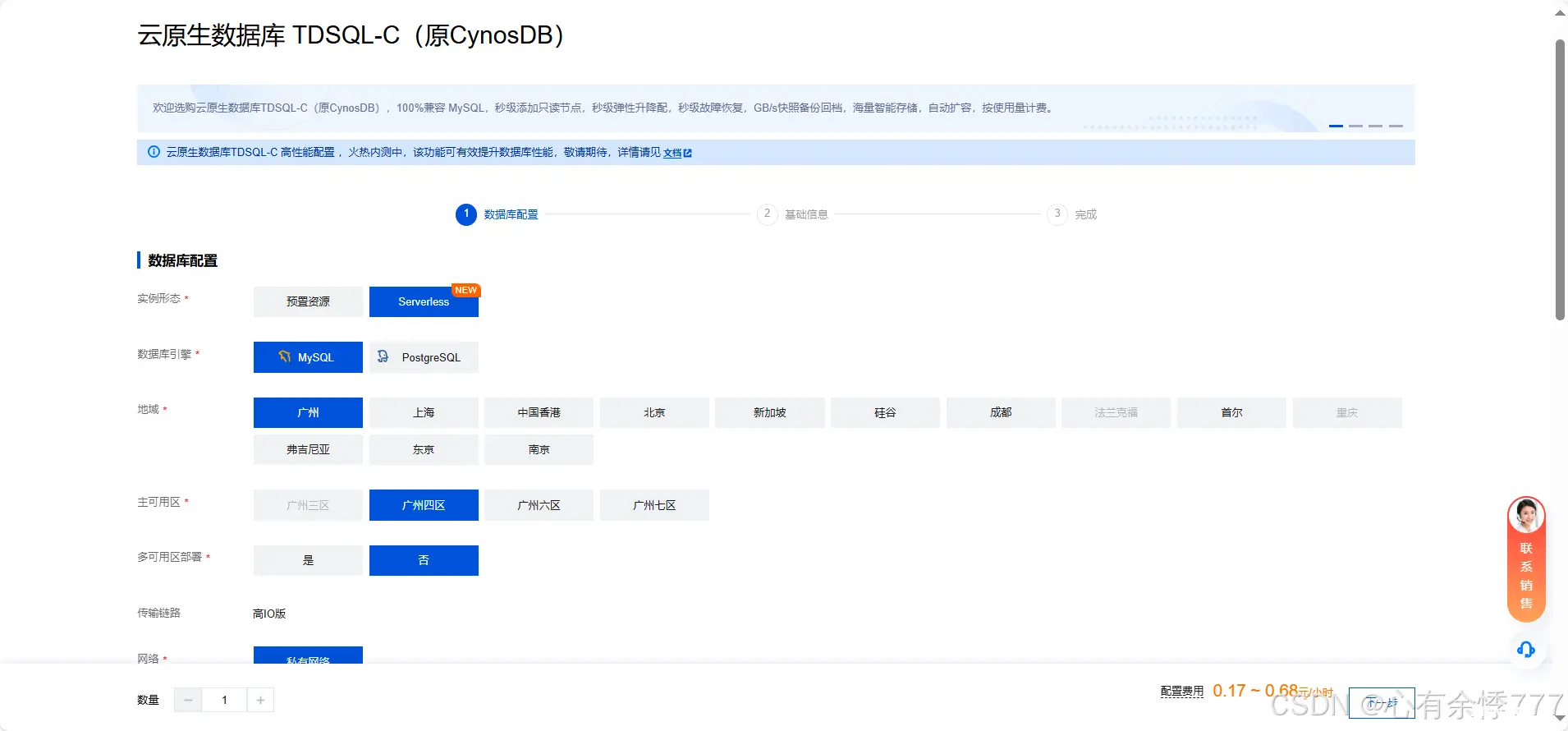
3.设置数据库密码与配置信息
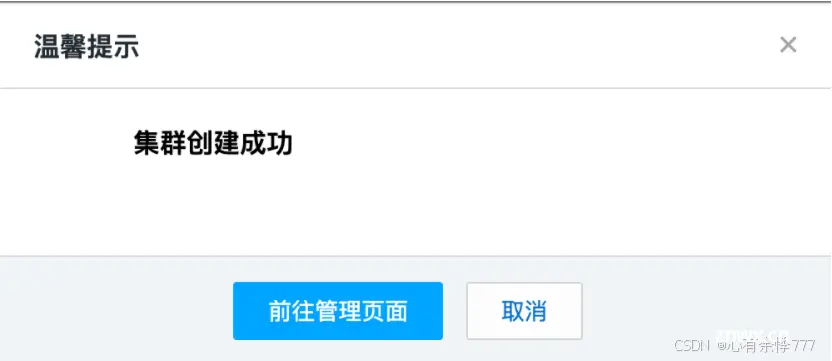
最后点击购买之后会显示集群创建成功,点击前往管理页面即可
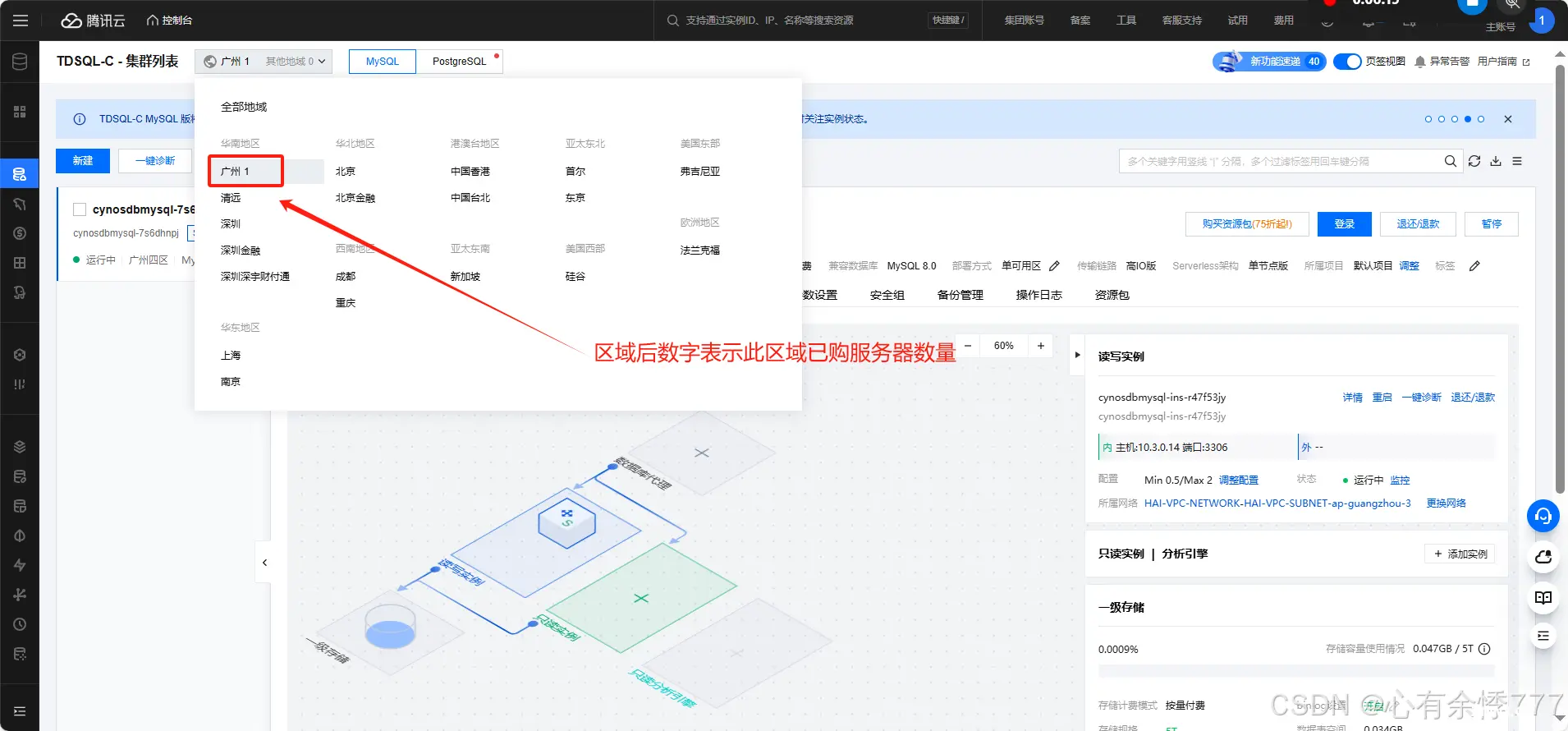
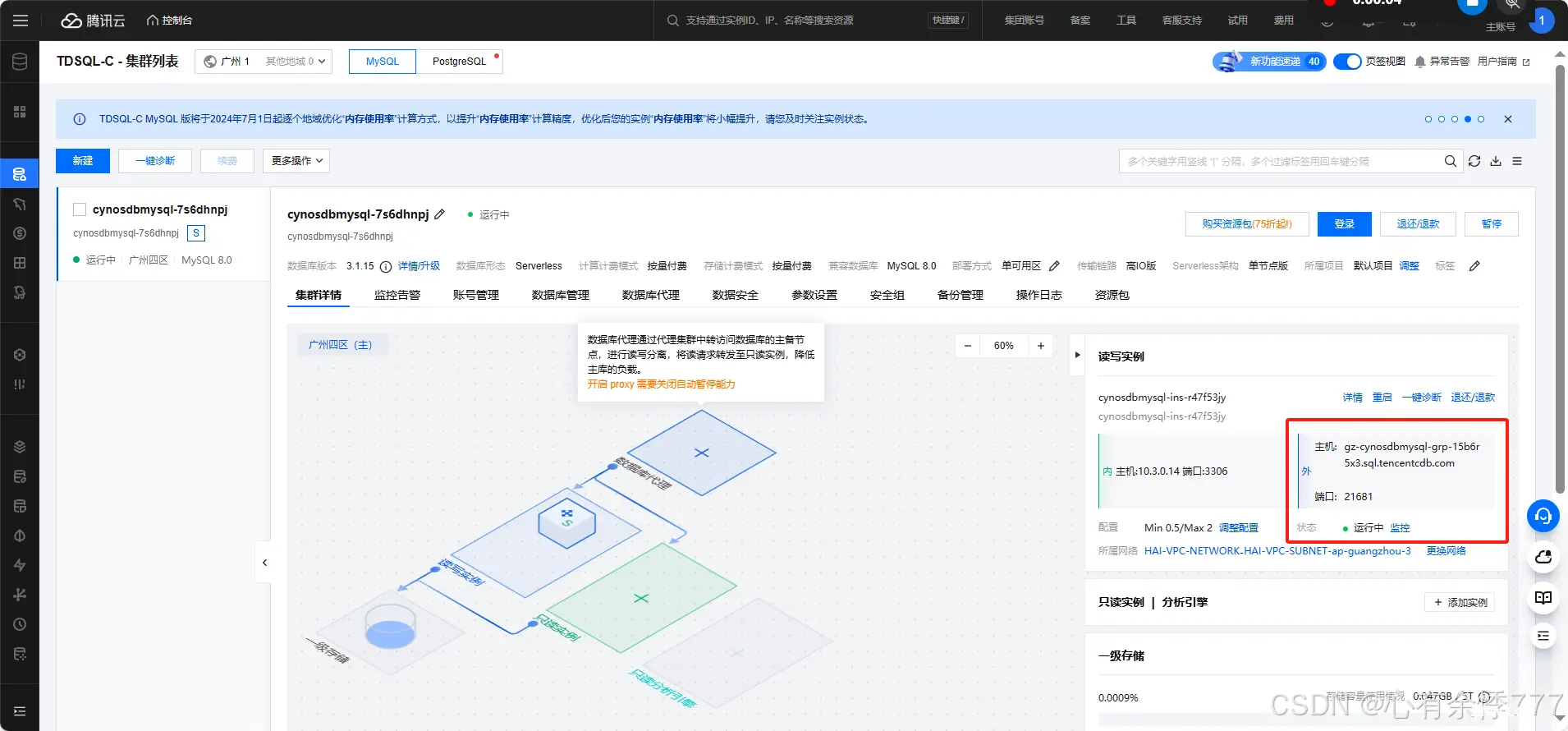
4.管理页面中选择指定区域的 <code>TDSQL-C Mysql 服务器(我选的是广州)
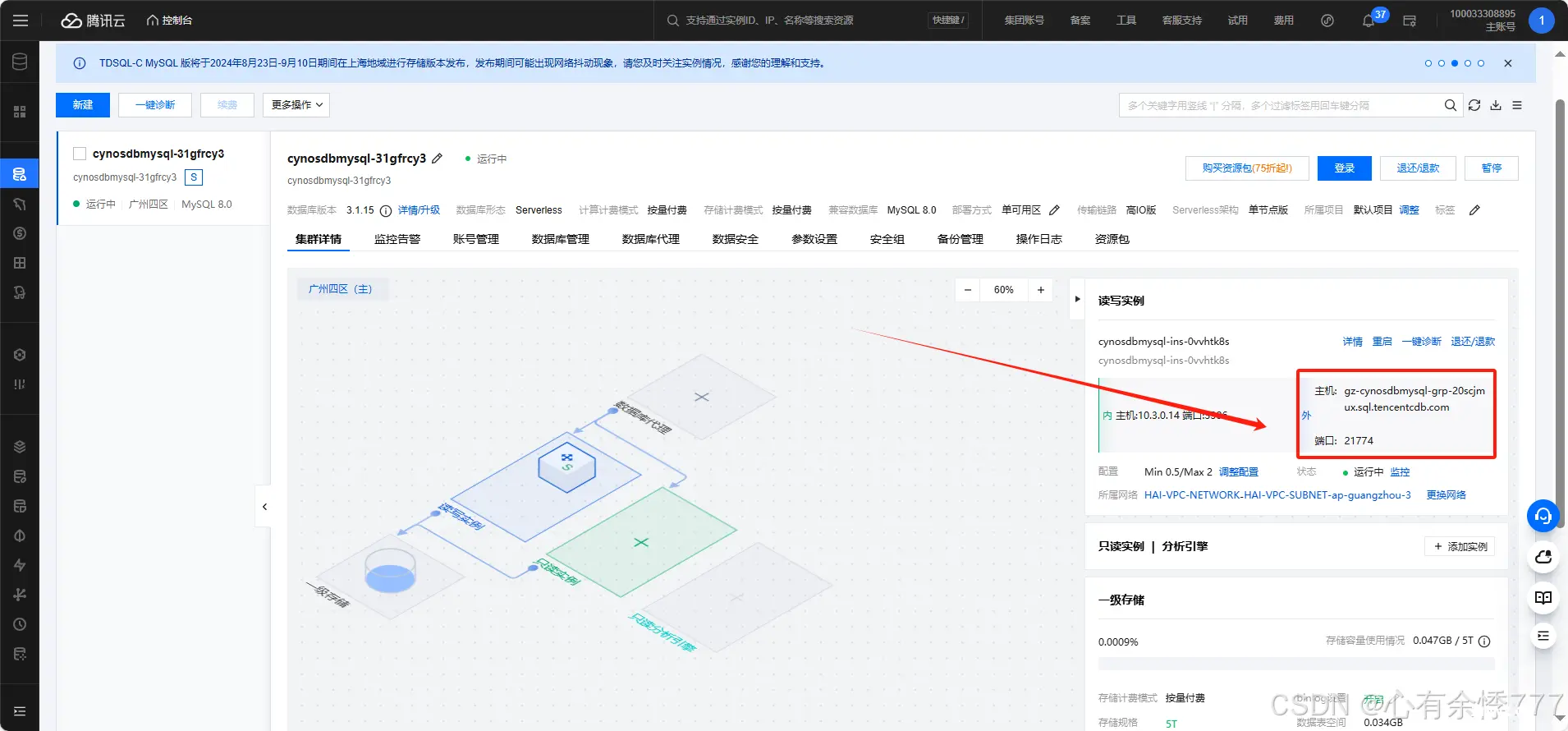
5.开启实例公网访问
6.登录在线数据库管理平台

7.创建数据库travel
8.导入数据表
这个数据表不一定非得用我的,大家可以自己去网上找一些数据源照样是能被AI识别的,如果需要的话评论区留言。
部署HAI高算力服务器
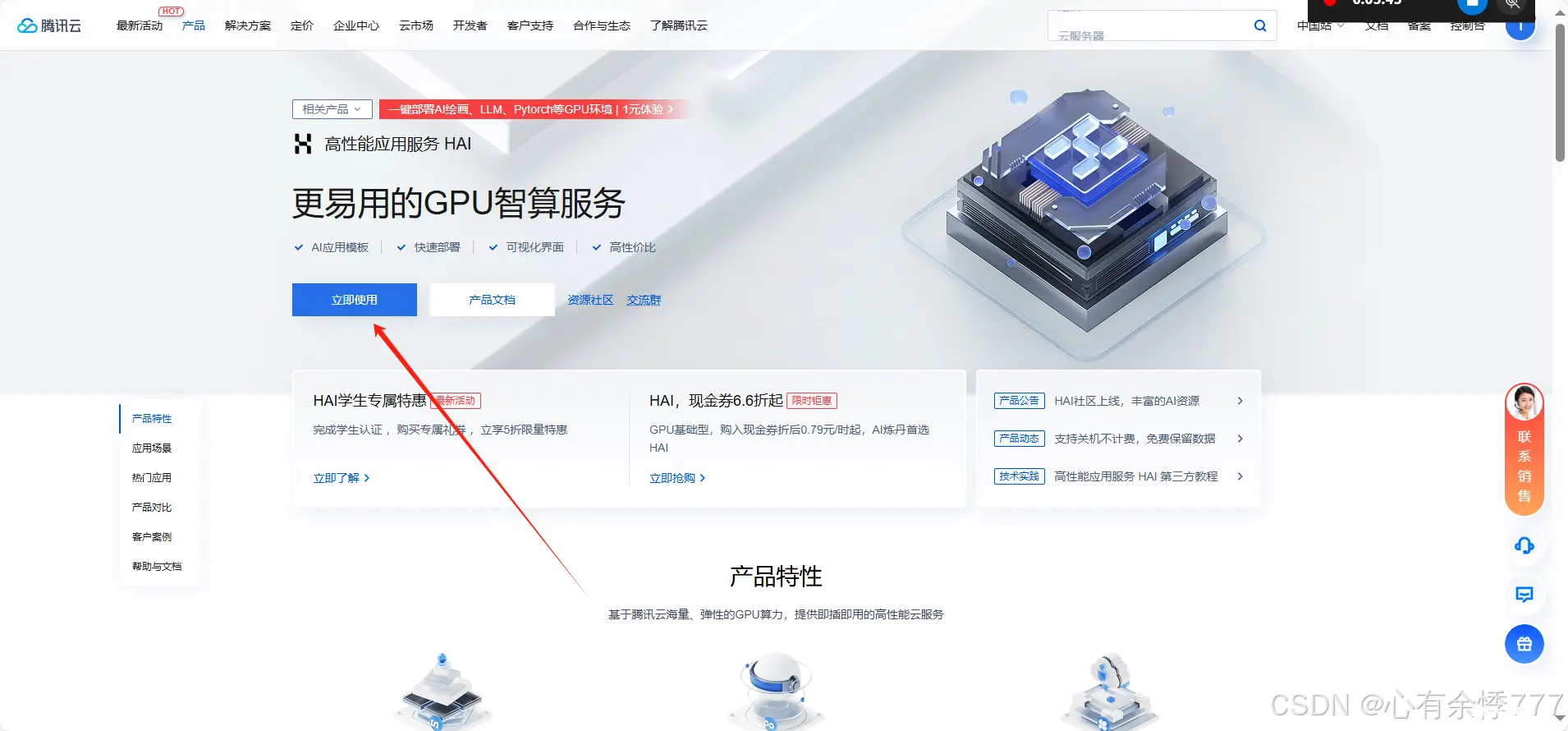
官网地址:https://cloud.tencent.com/product/hai
点击立即使用
2.点击新建根据需求配置服务器

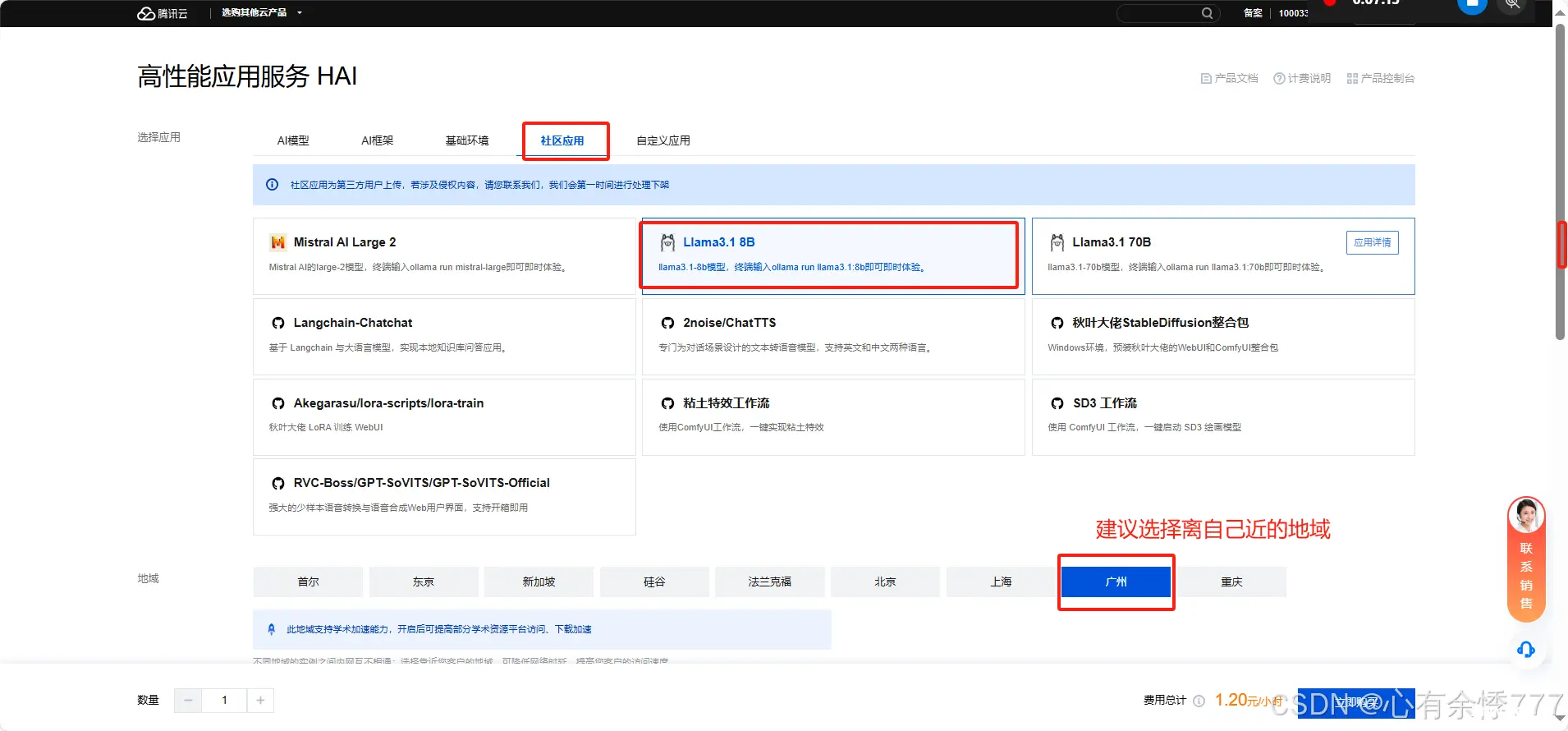
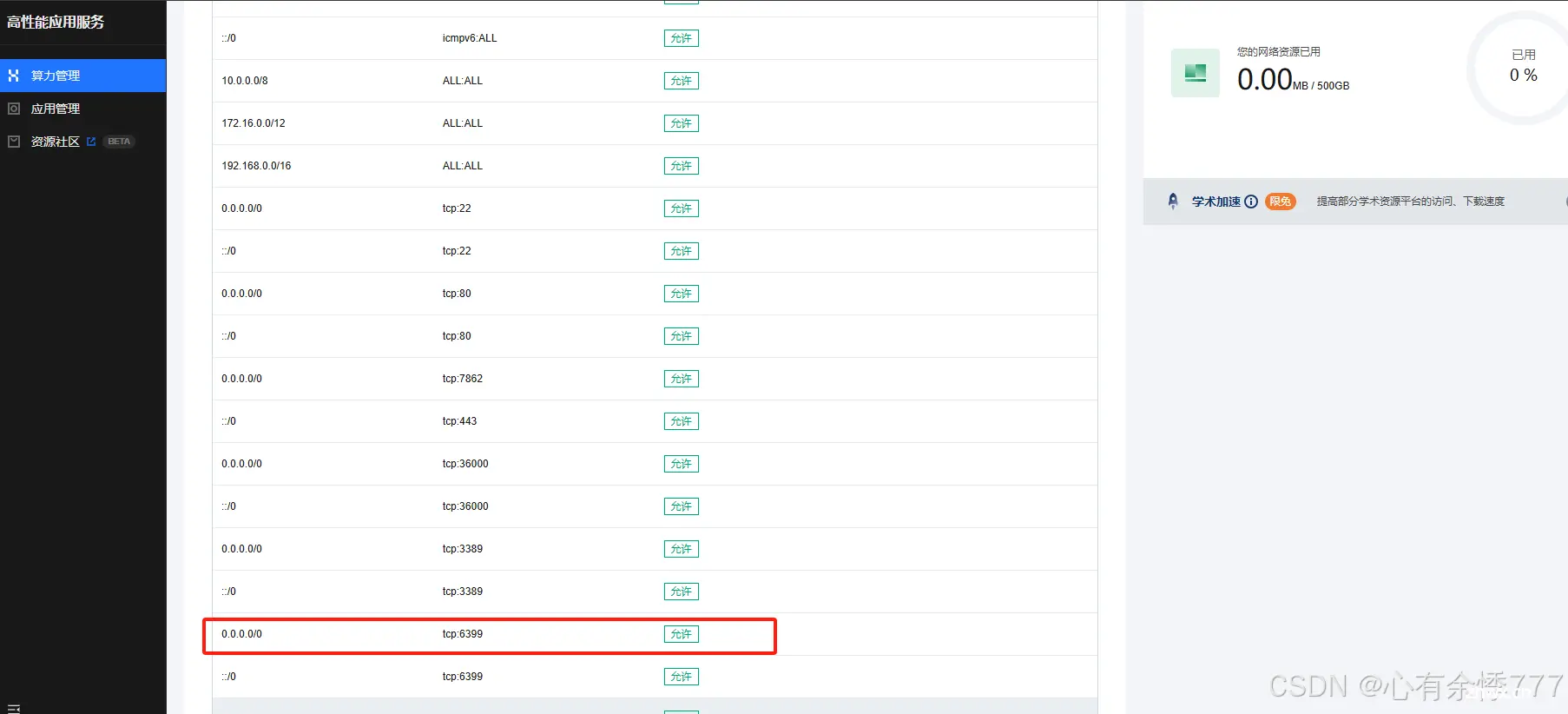
检查是否已经默认开放 6399端口,如下状态即是开放
<code>llama 大模型服务准备完毕!
云端python环境搭建
虽然使用本地python环境搭建也可以,但是对比腾讯的云端 IDE就比较落伍了。
大家用过的都觉得高效便捷,快速构建开发环境,直接就是宝宝级别的开发辅助啊!
云端IDE里面各种开发语言模板和AI模板可以让大家节约不少搭建开发环境的时间。

跟着我的步骤来,如下图所示你会发现一分钟内搭建环境不算是啥新鲜事,更不会觉得我开头的10分钟打造一个AI小助手项目是吹牛了。
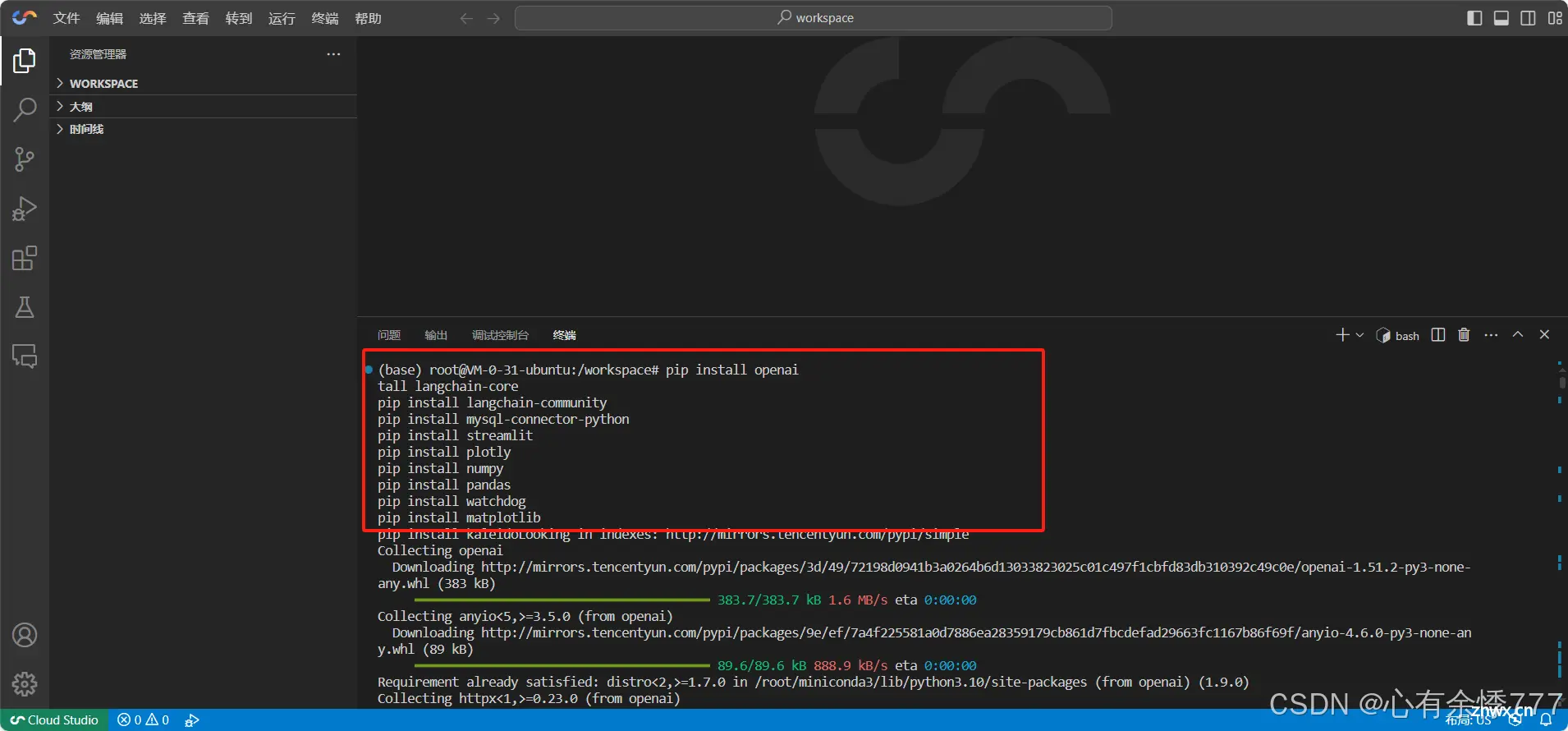
安装依赖包
<code>pip install openai
pip install langchain
pip install langchain-core
pip install langchain-community
pip install mysql-connector-python
pip install streamlit
pip install plotly
pip install numpy
pip install pandas
pip install watchdog
pip install matplotlib
pip install kaleido
大致估计依赖包的安装就使用了1分钟左右,如果是本地搭建安装依赖包的话至少也得10分钟吧。如果用的不是国内镜像恐怕就可能是30分钟左右,那环境搭建好了心都累了,谁还写项目?
回到正题:
新建名为 <code>workspace 文件夹进行保存项目代码在项目文件夹(workspace)中新建配置文件 config.yaml在项目文件夹(workspace)中新建应用主文件 text2sql2plotly.py
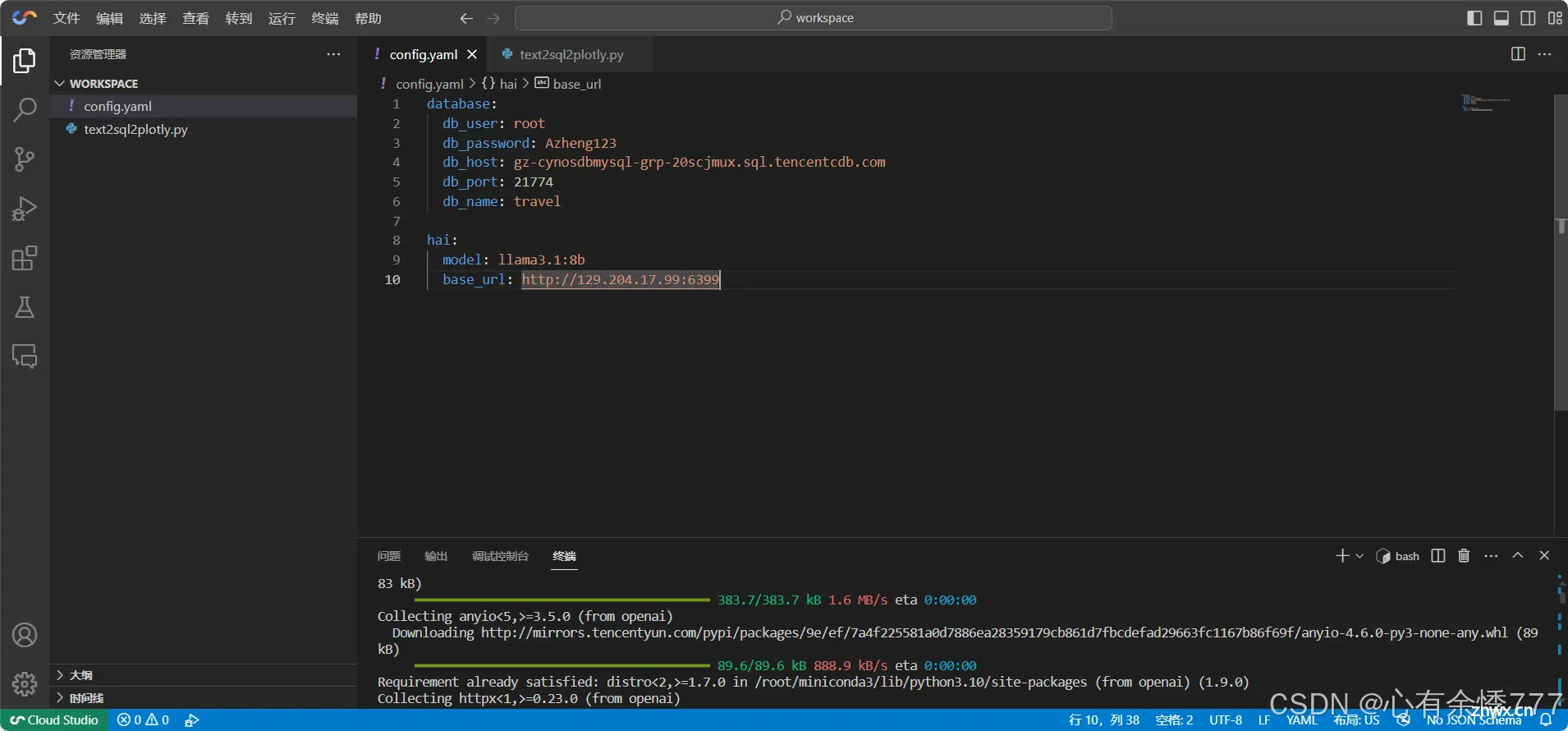
需要注意的是配置文件中的信息需要和服务器一一对应

其实主要就是服务器的公网ip和端口号对了 基本上就不会有问题

应用开发
将以下程序代码复制并保存到 <code>text2sql2plotly.py 文件中
from langchain_community.utilities import SQLDatabase
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import yaml
import mysql.connector
from decimal import Decimal
import plotly.graph_objects as go
import plotly
import pkg_resources
import matplotlib
yaml_file_path = 'config.yaml'
with open(yaml_file_path, 'r') as file:
config_data = yaml.safe_load(file)
# 获取所有的已安装的pip包
def get_piplist(p):
return [d.project_name for d in pkg_resources.working_set]
# 获取llm用于提供AI交互
ollama = ChatOllama(model=config_data['hai']['model'], base_url=config_data['hai']['base_url'])
db_user = config_data['database']['db_user']
db_password = config_data['database']['db_password']
db_host = config_data['database']['db_host']
db_port = config_data['database']['db_port']
db_name = config_data['database']['db_name']
# 获得schema
def get_schema(db):
schema = mysql_db.get_table_info()
return schema
def getResult(content):
global mysql_db
# 数据库连接
mysql_db = SQLDatabase.from_uri(f"mysql+mysqlconnector://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
# 获得 数据库中表的信息
# mysql_db_schema = mysql_db.get_table_info()
# print(mysql_db_schema)
template = """基于下面提供的数据库schema, 根据用户提供的要求编写sql查询语句,要求尽量使用最优sql,每次查询都是独立的问题,不要收到其他查询的干扰:
{schema}
Question: {question}
只返回sql语句,不要任何其他多余的字符,例如markdown的格式字符等:
如果有异常抛出不要显示出来
"""
prompt = ChatPromptTemplate.from_template(template)
text_2_sql_chain = (
RunnablePassthrough.assign(schema=get_schema)
| prompt
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
sql = text_2_sql_chain.invoke({"question": content})
print(sql)
# 连接数据库进行数据的获取
# 配置连接信息
conn = mysql.connector.connect(
host=db_host,
port=db_port,
user=db_user,
password=db_password,
database=db_name
)
# 创建游标对象
cursor = conn.cursor()
# 查询数据
cursor.execute(sql.strip("```").strip("```sql"))
info = cursor.fetchall()
# 打印结果
# for row in info:
# print(row)
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 根据数据生成对应的图表
print(info)
template2 = """
以下提供当前python环境已经安装的pip包集合:
{installed_packages};
请根据data提供的信息,生成是一个适合展示数据的plotly的图表的可执行代码,要求如下:
1.不要导入没有安装的pip包代码
2.如果存在多个数据类别,尽量使用柱状图,循环生成时图表中对不同数据请使用不同颜色区分,
3.图表要生成图片格式,保存在当前文件夹下即可,名称固定为:图表.png,
4.我需要您生成的代码是没有 Markdown 标记的,纯粹的编程语言代码。
5.生成的代码请注意将所有依赖包提前导入,
6.不要使用iplot等需要特定环境的代码
7.请注意数据之间是否可以转换,使用正确的代码
8.不需要生成注释
data:{data}
这是查询的sql语句与文本:
sql:{sql}
question:{question}
返回数据要求:
仅仅返回python代码,不要有额外的字符
"""
prompt2 = ChatPromptTemplate.from_template(template2)
data_2_code_chain = (
RunnablePassthrough.assign(installed_packages=get_piplist)
| prompt2
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
code = data_2_code_chain.invoke({"data": info, "sql": sql, 'question': content})
# 删除数据两端可能存在的markdown格式
print(code.strip("```").strip("```python"))
exec(code.strip("```").strip("```python"))
return {"code": code, "SQL": sql, "Query": info}
# 构建展示页面
import streamlit
# 设置页面标题
streamlit.title('AI联动数据库TDSQL-C 打造的旅游攻略分析小助手')
# 设置对话框
content = streamlit.text_area('请输入想查询的信息', value='', max_chars=None)code>
# 提问按钮 # 设置点击操作
if streamlit.button('提问'):
# 开始ai及langchain操作
if content:
# 进行结果获取
result = getResult(content)
# 显示操作结果
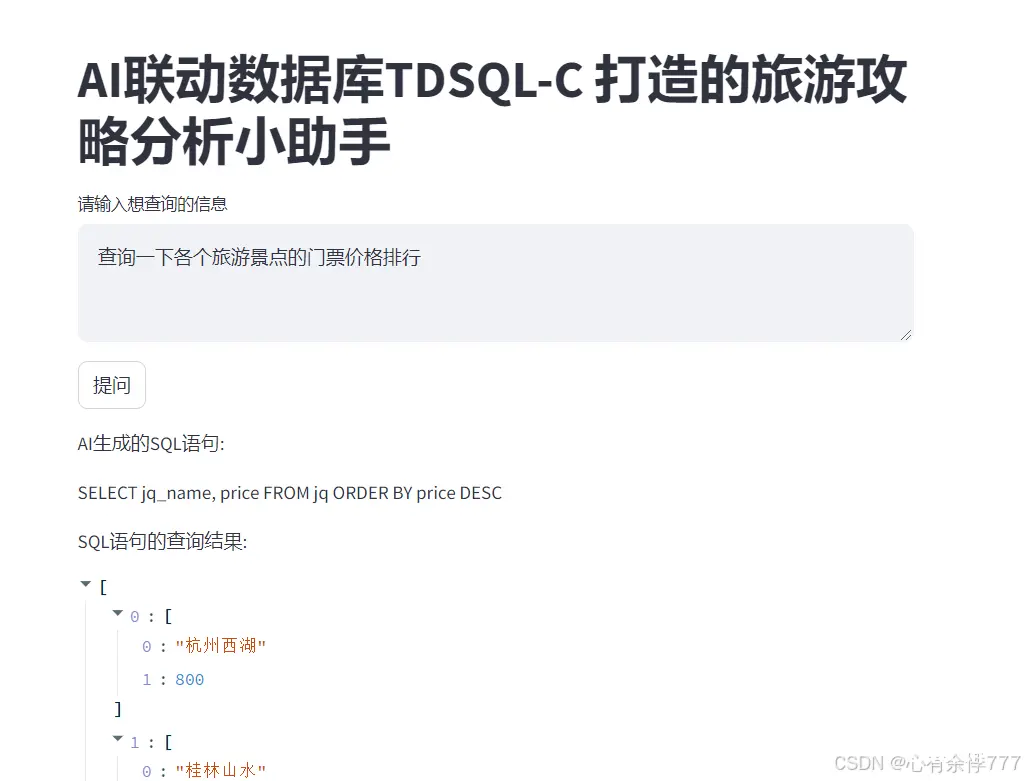
streamlit.write('AI生成的SQL语句:')
streamlit.write(result['SQL'])
streamlit.write('SQL语句的查询结果:')
streamlit.write(result['Query'])
streamlit.write('plotly图表代码:')
streamlit.write(result['code'])
# 显示图表内容(生成在getResult中)
streamlit.image('./图表.png', width=800)
打开终端执行以下命令
<code>streamlit run text2sql2plotly.py
命令运行后在浏览器中打开UI界面输入你想查询的信息,如下图所示
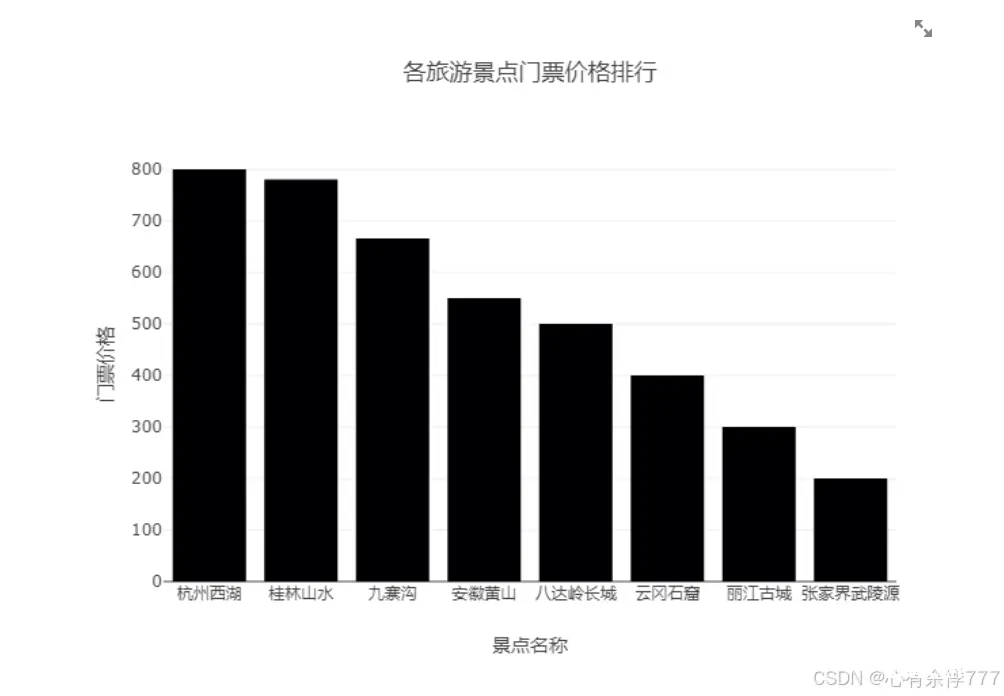
到这里大家已经成功打造了一个AI旅游攻略分析小助手,建议大家可以把自己觉得靠谱的数据导入到数据库。以后过节旅游可以直接通过小助手查询一下哪些景区的游客数量多或者评分低,帮助大家避开人挤人的情况,享受一个温馨惬意的旅程。
五、清理资源
删除TDSQL-C Serverless
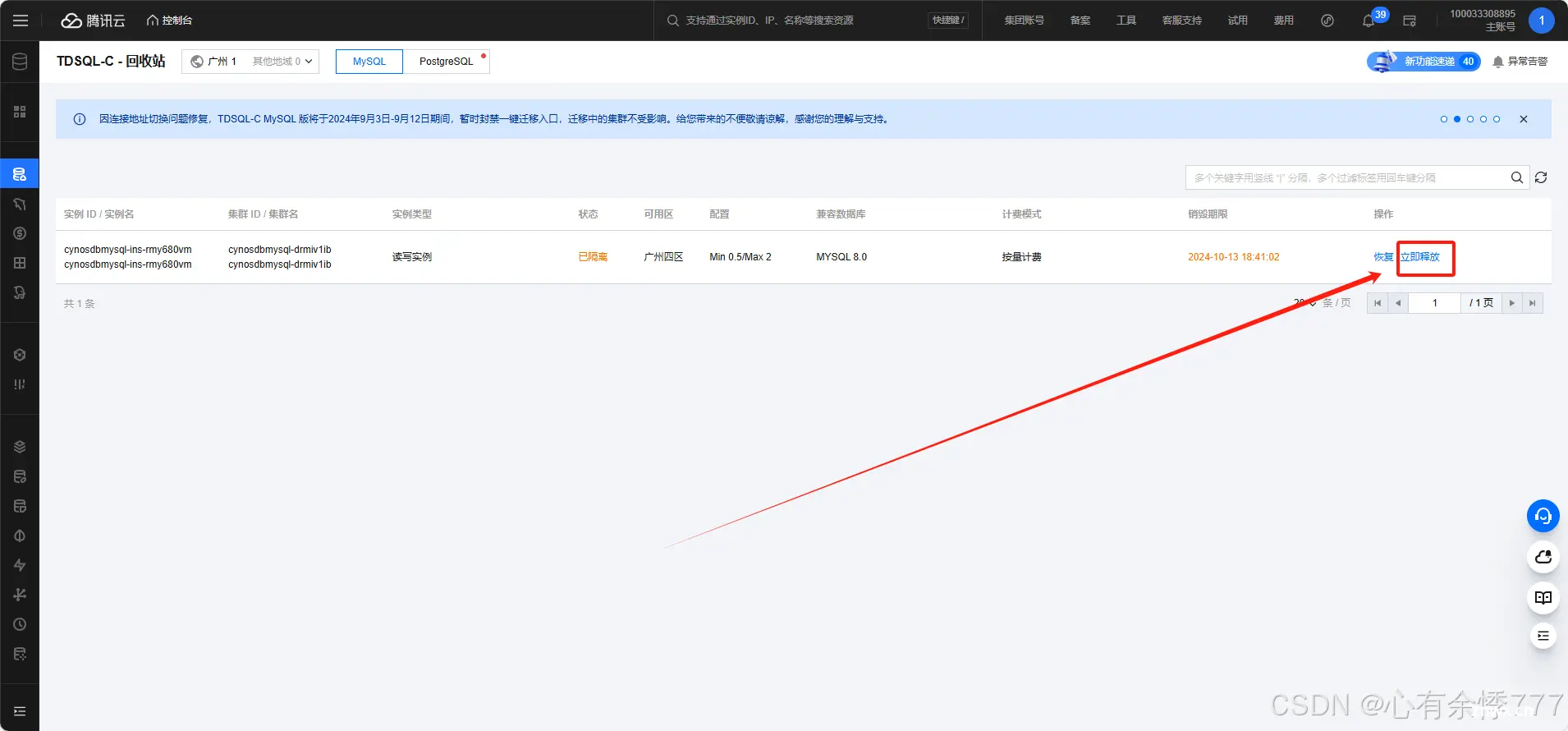
点击退还实例,退还后实例会在回收站中
点击回收站即可看到已被退还的实例,为了数据安全,实例默认会在回收站中保留3天,如不需要可以进行立即释放
删除 HAI 算力

六、体验感受
我们使用腾讯云的 <code>TDSQL-C MySQL Serverless 和高性能应用服务HAI,构建了一个高效、可扩展的AI旅游数据分析系统。以下是我的感受和收获:
TDSQL-C MySQL优势:通过使用TDSQL-C MySQL Serverless,我体验到云原生数据库在处理各种复杂的旅游相关数据时的弹性和高性能,这对于大家搜索旅游攻略的时效性和可靠性特别有帮助,完全可以满足用户的体验。
腾讯云的AI模型:HAI提供的GPU加速能力显著提升了AI模型的训练和推理速度,使得系统能够快速分析和处理各种复杂多变的旅游数据和用户需求。
价值:通过本文的分享,大家不仅理解了理论知识,还通过实际操作加深了对TDSQL-C MySQL Serverless和HAI的使用方法。
拓展空间:文中我也指出了AI存在的缺陷和改进空间,希望大家持续学习最新的技术和方法,以不断优化和改进AI小助手。
在这个AI普及大众的时代,我期待在未来的时间里大家能找到解决AI缺陷和创新的可能性,大家一起来探索 TDSQL-C Serverless + AI 更多的场景,共同打造一个属于大家的联动并能整合的AI应用生态圈!这里强烈推荐腾讯云的HAI,本项目一共消费5块钱,大家可以尝试一下,物美价廉。
上一篇: 微软AI人工智能认证有哪些?
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。