828华为云征文|Flexus X实例ultralytics模型yolov10深度学习AI部署与应用
爱吃香蕉的阿豪 2024-09-15 14:01:01 阅读 77
目录
前言:
环境准备
购买服务器配置
连接服务器
安装Python
安装Pytorch
部署YOLOv10
拉取YOLOv10代码并安装相关依赖
数据集准备
Detect目标检测模型训练
训练数据集的配置文件
训练命令
识别命令
前言:
🔍 深度学习新纪元,828 B2B企业节Flexus X实例特惠!想要高效训练YOLOv10模型,实现精准图像识别?Flexus X以卓越算力,助您轻松驾驭大规模数据集,加速模型迭代,让AI智能触手可及。把握此刻,让创新不再受限!
🐳本实验演示从0到1部署YOLOv10深度学习AI大模型的环境搭建、模型训练、权重使用,以及各项指标解读。实验环境为Flexus云服务器X实例 服务器,配置:4vCPUs | 12GiB
环境准备
购买服务器配置
本次实验使用的是 Flexus云服务器X实例 服务器。
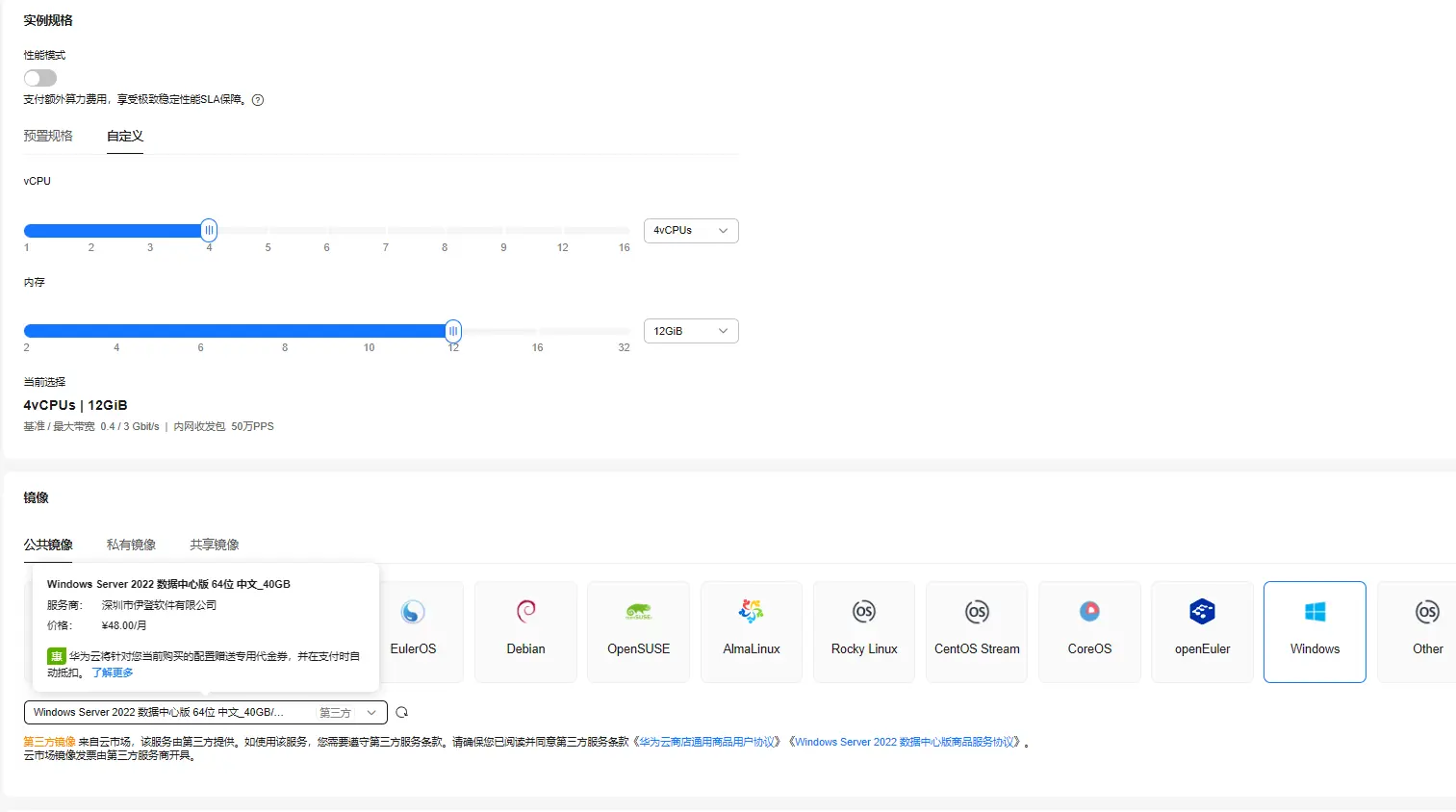
在性能设置中我选择了自定义模式,使用了4vCPUs | 12GiB,因为本次要实验的是yolov10的部署与应用,Windows操作系统具有更加直观的用户界面和强大的图形支持,我选择了公共镜像Windows Server 2022 数据中心版。以上配置仅供参考,并非硬性要求!
连接服务器
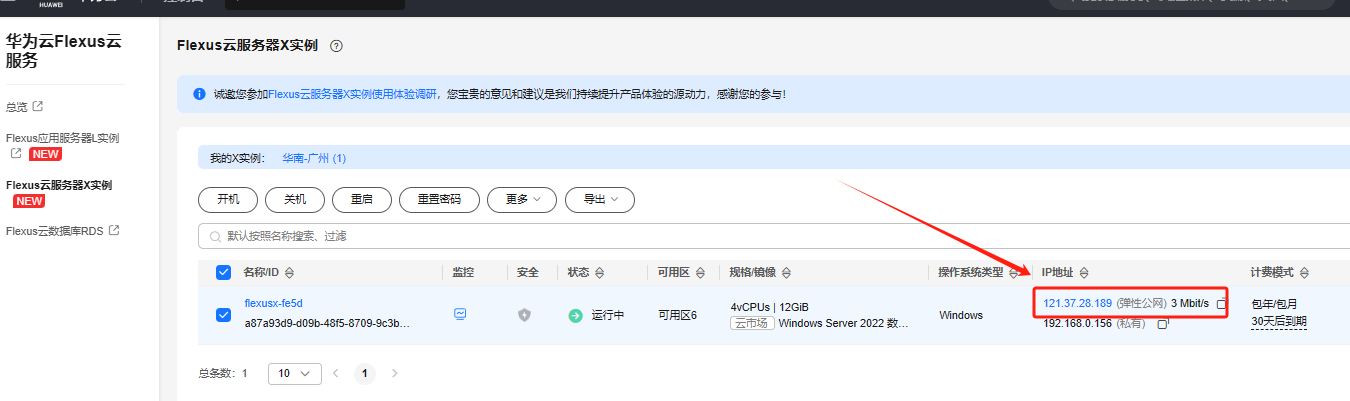
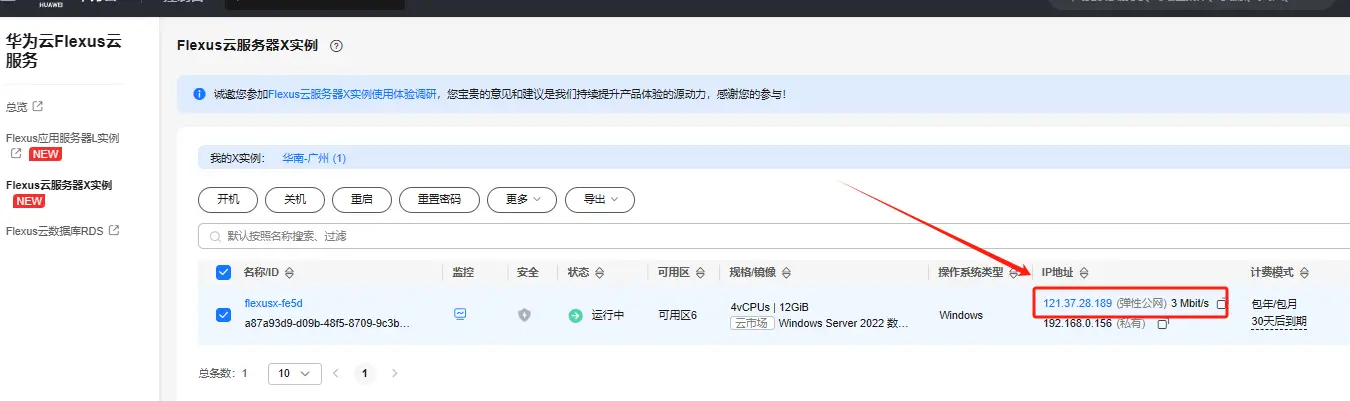
在华为云服务器控制台中找到我们刚刚购买的服务器,将弹性公网IP地址复制下来。
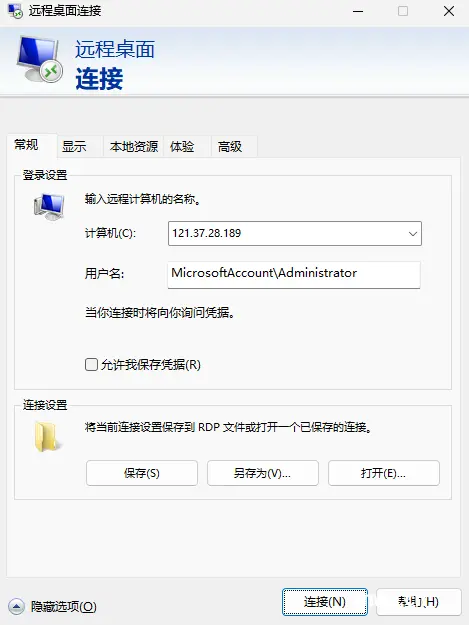
快捷键Windows + R 打开运行窗口,输入mstsc,回车!
输入计算机:弹性公网IP地址;用户名:MicrosoftAccount\Administrator,单击“确定”。
然后输入密码,就成功的连接到我们的服务器了。
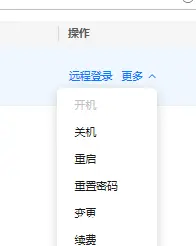
如果忘记密码了,可以在操作列中点击重置密码,重新设置我们的服务器密码。
安装Python
我们先来安装python3,打开官网地址
Download Python | Python.org
在官网下一个大于大于3.8的python安装包(官方建议使用3.9的版本),选择amd64的exe版本
安装的时候勾选最底下的帮我们添加环境变量
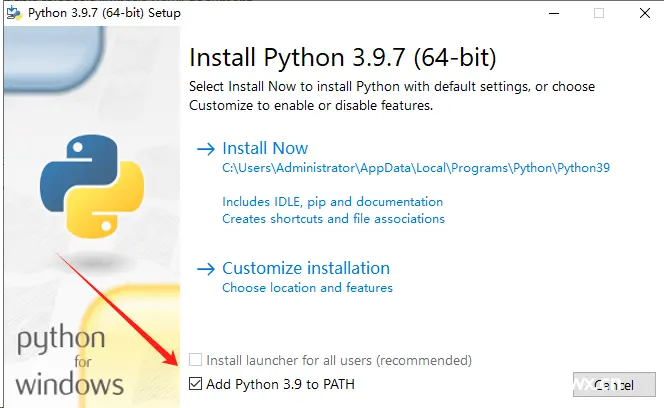
等待片刻,出现下面这个界面就是安装成功了。
CMD打开控制台小黑窗,执行 python -V 和 pip -V 查看python版本与pip版本,看看我们的环境变量是否设置成功。
安装Pytorch
到官网安装Pytorch
Start Locally | PyTorch
在安装之前看看自己买的服务器是否有GPU,可以使用命令来查看
查看CPU型号:cat /proc/cpuinfo | grep "model name"
查看GPU型号(Nvidia GPU):nvidia-smi --query-gpu=gpu_name --format=csv
查看GPU型号(AMD Radeon GPU):sudo lshw -C display
因为我这台是只有CPU的,因此在官网中选择Stable(稳定版),系统Linux,用pip来安装吧,然后Compute Platform选择CPU,然后把Run this Command:中的命令👇cmd打开黑窗口执行。
我这里执行的是
<code>pip3 install torch torchvision torchaudio
直接执行可能会很慢,我在后面加上指定镜像源,切换为国内镜像
pip3 install torch torchvision torchaudio -i https://pypi.mirrors.ustc.edu.cn/simple/
出现如下画面即是成功下载完成。
部署YOLOv10
YOLOv10是YOLO(You Only Look Once)系列的最新版本,由清华大学的研究人员开发,旨在进一步提高实时目标检测的效率和准确性。以下是对YOLOv10的详细介绍:
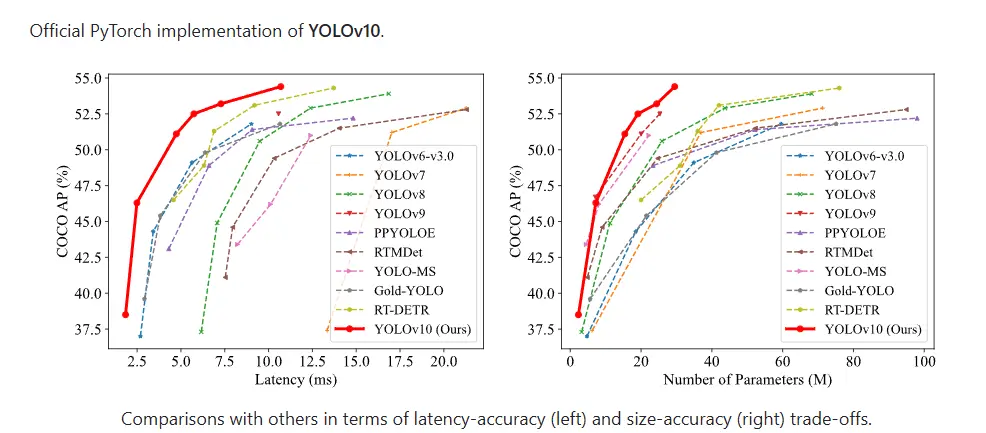
之前的YOLO版本在后处理和模型架构方面仍存在不足,特别是依赖于非最大抑制(NMS)进行后处理,这限制了模型的端到端部署并增加了推理延迟。YOLOv10通过消除NMS和优化模型组件,旨在解决这些问题,实现更高的性能和效率。
拉取YOLOv10代码并安装相关依赖
打开YOLOV0的GItHub代码库,将源码下载到本地,解压。
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
解压完成后,打开命令行窗口,cd到源码的工作目录,执行下面两个命令。
<code>//升级pip
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install ultralytics
pip install yolo
pip install -e .
速度慢的话换国内镜像,在命令后面加上-i 镜像源
以下是常用的国内镜像源
清华大学:https://pypi.tuna.tsinghua.edu.cn/simpl
阿里云:https://mirrors.aliyun.com/pypi/simple/
豆瓣:https://pypi.douban.com/simple/
腾讯云:https://mirrors.cloud.tencent.com/pypi/simple/
华为云:https://mirrors.huaweicloud.com/repository/pypi/simple/
中国科学技术大学:https://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
浙江大学:https://mirrors.zju.edu.cn/pypi/web/simple
北京外国语大学:https://mirrors.bfsu.edu.cn/pypi/web/simple
上海交通大学:https://mirrors.sjtug.sjtu.edu.cn/pypi/web/simple
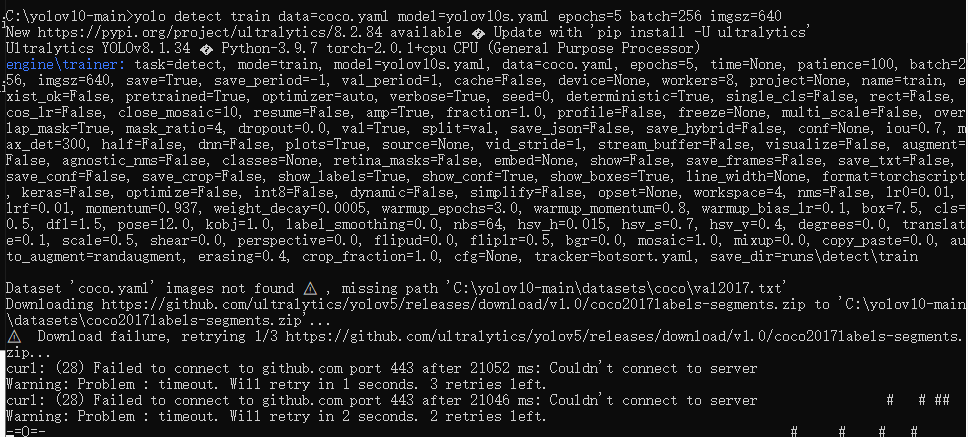
当以上相关依赖都安装完毕后,执行以下训练命令测试我们的环境(此步骤可跳过)。
yolo detect train data=coco.yaml model=yolov10s.yaml epochs=5 batch=256 imgsz=640
第一次执行会自动下载官方提供的训练案例文件,需要等待较长时间。
数据集准备
YOLOv10作为实时目标检测模型,理论上支持多种类型的数据集,只要这些数据集符合YOLOv10的输入格式和标注要求。具体来说,YOLOv10可以支持的数据集包括但不限于以下几种类型:
通用目标检测数据集:如COCO(Common Objects in Context)数据集,这是一个大型、丰富的图像数据集,用于目标检测、分割、关键点检测等多种任务。YOLOv10在COCO数据集上取得了显著的性能提升,展现出优异的精度-效率平衡能力。特定领域数据集:YOLOv10也可以应用于特定领域的数据集,如交通标志检测数据集、人脸检测数据集、车辆检测数据集等。这些数据集通常针对特定场景或任务进行收集和标注,以满足特定领域的需求。自定义数据集:用户还可以根据自己的需求创建自定义数据集,并使用YOLOv10进行训练和测试。自定义数据集需要按照YOLOv10的输入格式进行标注和组织,包括图像文件、标签文件以及可能的数据集配置文件等。
通常来说,我们需要将标注结果与原图按比例分配到三个文件夹中
如你有100张标注了的图片,大约 70 张图片用于训练数据,约 20 张图片用于验证数据,约 10 张图片用于测试数据
train 路径用于训练模型,val 路径用于验证模型,test 路径用于测试模型。在训练和验证期间,模型将在不同的数据集上进行训练和验证,以便评估模型的性能。在测试期间,模型将使用整个数据集进行测试,以确定其性能指标
需要注意的是:训练过的图片通常不能用于验证数据。这是因为在训练期间,模型已经对这些图片进行了训练,并学会了识别这些图片中的对象和场景类别。
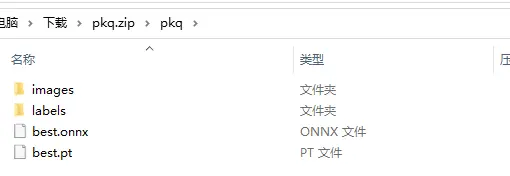
因为数据标注要花费大量的时间,这里直接拿出我最爱的皮卡丘标注数据
400多张“皮卡丘”原图与标注结果以及yolov8的训练结果best.pt权重和ONNX格式文件_yolov8权重转onnx资源-CSDN文库
在这个压缩包中有皮卡丘图片与标注信息,还有yolov8的训练好的权重文件,我们只留下images和labels用来训练yolov10版本的权重。
因为我比较懒,能用代码解决的事就用代码,下面我们使用python对数据集进行随机分配。
修改下面代码中66-67行中的
src_data_folder = '数据集路径' target_data_folder = '处理后的数据集'
<code># 工具类
import os
import random
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.2):
'''
读取源数据文件夹,生成划分好的文件夹,分为train、val两个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.makedirs(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.makedirs(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
train_stop_flag = current_data_length * train_scale
current_idx = 0
train_num = 0
val_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
train_num = train_num + 1
else:
copy2(src_img_path, val_folder)
val_num = val_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print("{}类按照{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
if __name__ == '__main__':
src_data_folder = 'datasets/dwsb'
target_data_folder = 'datasets/dwsb2'
data_set_split(src_data_folder, target_data_folder, 0.8, 0.2)
因为在yolo训练中,我们并不需要将图片和标注结果分开存放,因此我们将train和val中的images和labels里的文件都全部移出来,然后将这两个文件夹删掉即可。

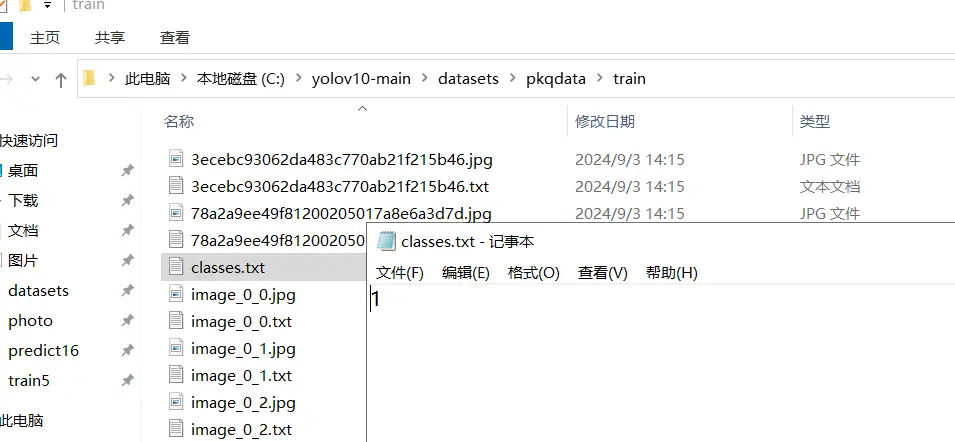
要注意的是,不管是train还是val都需要检查是否包含这么一个classes.txt文件,如果没有的话需要自己手动补上,因为我这里的素材只有一个皮卡丘目标,并且标注为1了,所以只写了一个1。

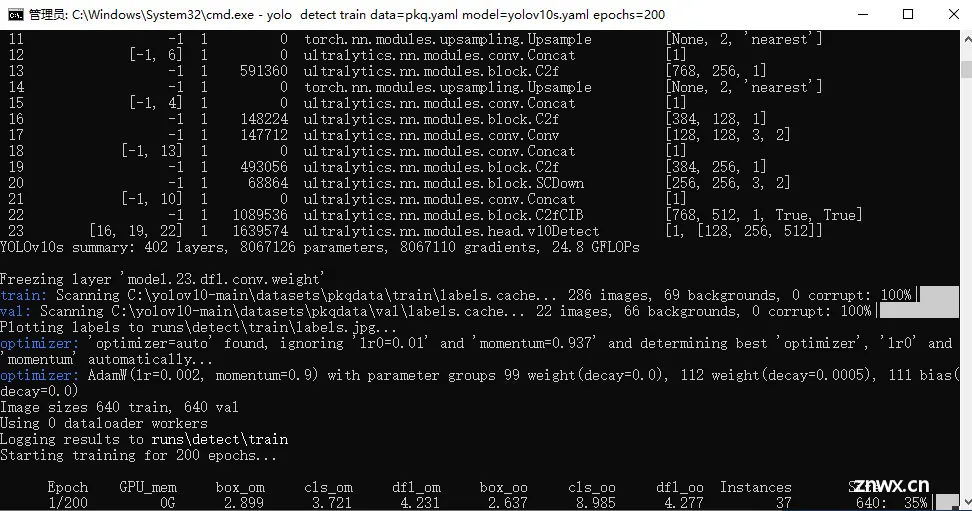
Detect目标检测模型训练
训练数据集的配置文件
参考路径C:\yolov10-main\ultralytics\cfg\datasets 找到voc.yaml,复制一份,自定义一个名字
对里面的代码进行调整,path 是我们的刚刚准备好的数据集目录路径(就是刚刚的data,我改了个名字),train和val就是训练集和验证集的文件夹名称。
names: 标注时的数值和他的别名(这里需要根据照数据集的标注类别来定义,如果用的是我的数据集,直接按照我的设置就好了)
<code># Ultralytics YOLO 🚀, AGPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
# Documentation: # Documentation: https://docs.ultralytics.com/datasets/detect/voc/
# Example usage: yolo train data=VOC.yaml
# parent
# ├── ultralytics
# └── datasets
# └── VOC ← downloads here (2.8 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: C:/yolov10-main/datasets/pkqdata
train: train
val: val
test: # test images (optional)
- images/test2007
# Classes
names:
0: pkq
# Download script/URL (optional) ---------------------------------------------------------------------------------------
download: |
import xml.etree.ElementTree as ET
from tqdm import tqdm
from ultralytics.utils.downloads import download
from pathlib import Path
def convert_label(path, lb_path, year, image_id):
def convert_box(size, box):
dw, dh = 1. / size[0], 1. / size[1]
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
return x * dw, y * dh, w * dw, h * dh
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
out_file = open(lb_path, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
names = list(yaml['names'].values()) # names list
for obj in root.iter('object'):
cls = obj.find('name').text
if cls in names and int(obj.find('difficult').text) != 1:
xmlbox = obj.find('bndbox')
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
cls_id = names.index(cls) # class id
out_file.write(" ".join(str(a) for a in (cls_id, *bb)) + '\n')
# Download
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
download(urls, dir=dir / 'images', curl=True, threads=3, exist_ok=True) # download and unzip over existing paths (required)
# Convert
path = dir / 'images/VOCdevkit'
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
imgs_path = dir / 'images' / f'{image_set}{year}'
lbs_path = dir / 'labels' / f'{image_set}{year}'
imgs_path.mkdir(exist_ok=True, parents=True)
lbs_path.mkdir(exist_ok=True, parents=True)
with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
image_ids = f.read().strip().split()
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
f.rename(imgs_path / f.name) # move image
convert_label(path, lb_path, year, id) # convert labels to YOLO format
训练命令
执行下面命令开始训练我们的模型
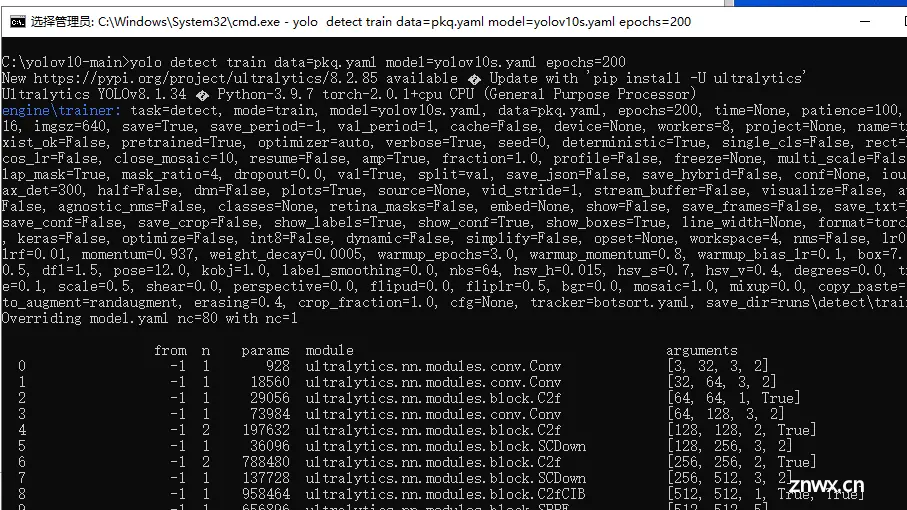
yolo detect train data=coco.yaml model=yolov10n/s/m/b/l/x.yaml epochs=500 batch=256 imgsz=640 device=0,1,2,3,4,5,6,7
关于命令的内容,我们来进行解读:
data=coco.yaml: 指定了训练数据集的配置文件,coco.yaml是一个YAML格式的文件,它包含了训练YOLO模型所需的数据集信息,如图片路径、标注文件路径、类别名称等。数据集遵循COCO(Common Objects in Context)的格式model=yolov10n/s/m/b/l/x.yaml: 指定了模型的配置文件。这里使用了yolov10n/s/m/b/l/x.yaml作为占位符,实际上应该选择一个具体的模型配置,如yolov10n.yaml、yolov10s.yaml等
YOLOv10-N:适用于资源极其有限的环境YOLOv10-S:兼顾速度与精度YOLOv10-M:一般用途YOLOv10-B:宽度增加,精度更高YOLOv10-L:以计算资源为代价实现高精度YOLOv10-X:最高精度和性能epochs=500: 指定了训练过程中的迭代次数(epoch)。一个epoch意味着整个训练数据集被遍历了一次。这里设置为500,意味着整个数据集将被用于训练500次。batch=256: 设置了每个batch中的图片数量。Batch size是一个重要的超参数,它影响模型的训练速度和稳定性。较大的batch size可以加速训练,但也可能需要更多的内存。imgsz=640: 指定了输入图片的大小。在这个例子中,所有输入图片都将被调整(或裁剪)到640x640像素。调整输入图片大小是YOLO等目标检测模型训练前的常见步骤。device=0,1,2,3,4,5,6,7: 指定了用于训练的GPU设备ID。在这个例子中,它使用了8个GPU(从0到7编号)来加速训练过程。这通常是在具有多个GPU的服务器上进行的,可以显著减少训练时间。
执行完命令后出现以下窗口意味着正在训练中,接下来就是漫长的等待~~~

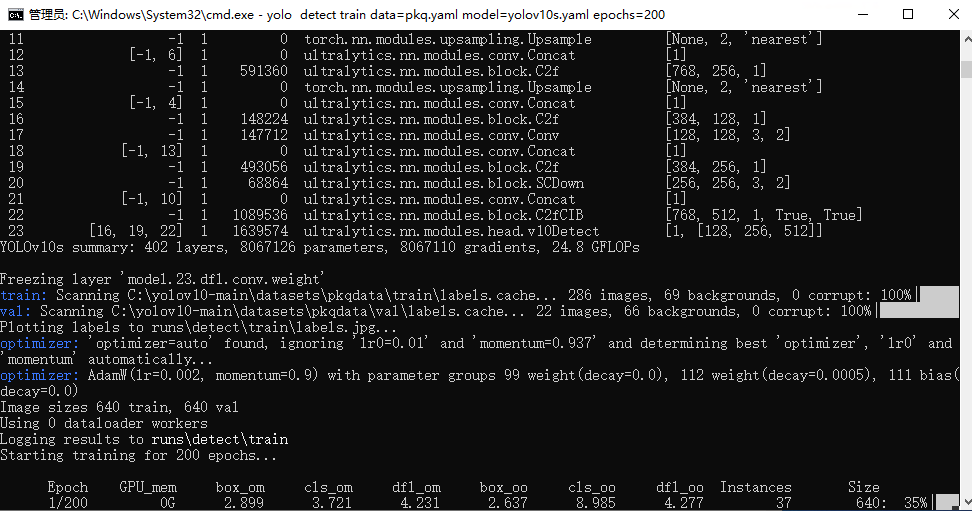
打开任务管理器看一下性能,CPU的利用率还是很可观的,4vCPUs | 12GiB的配置训练yolov10s的模型绰绰有余!
训练完成后
weights下有两个.pt文件,这是我们的训练结果权重文件
best.pt文件保存的是在验证集上表现最好的模型权重。在训练过程中,每个epoch结束后都会对验证集进行一次评估,并记录下表现最好的模型的权重。这个文件通常用于推理和部署阶段,因为它包含了在验证集上表现最好的模型的权重,可以获得最佳的性能。last.pt文件则保存的是最后一次训练迭代结束后的模型权重。这个文件通常用于继续训练模型,因为它包含了最后一次训练迭代结束时的模型权重,可以继续从上一次训练结束的地方继续训练模型。
因此部署的话使用best,下次继续追加训练就用last
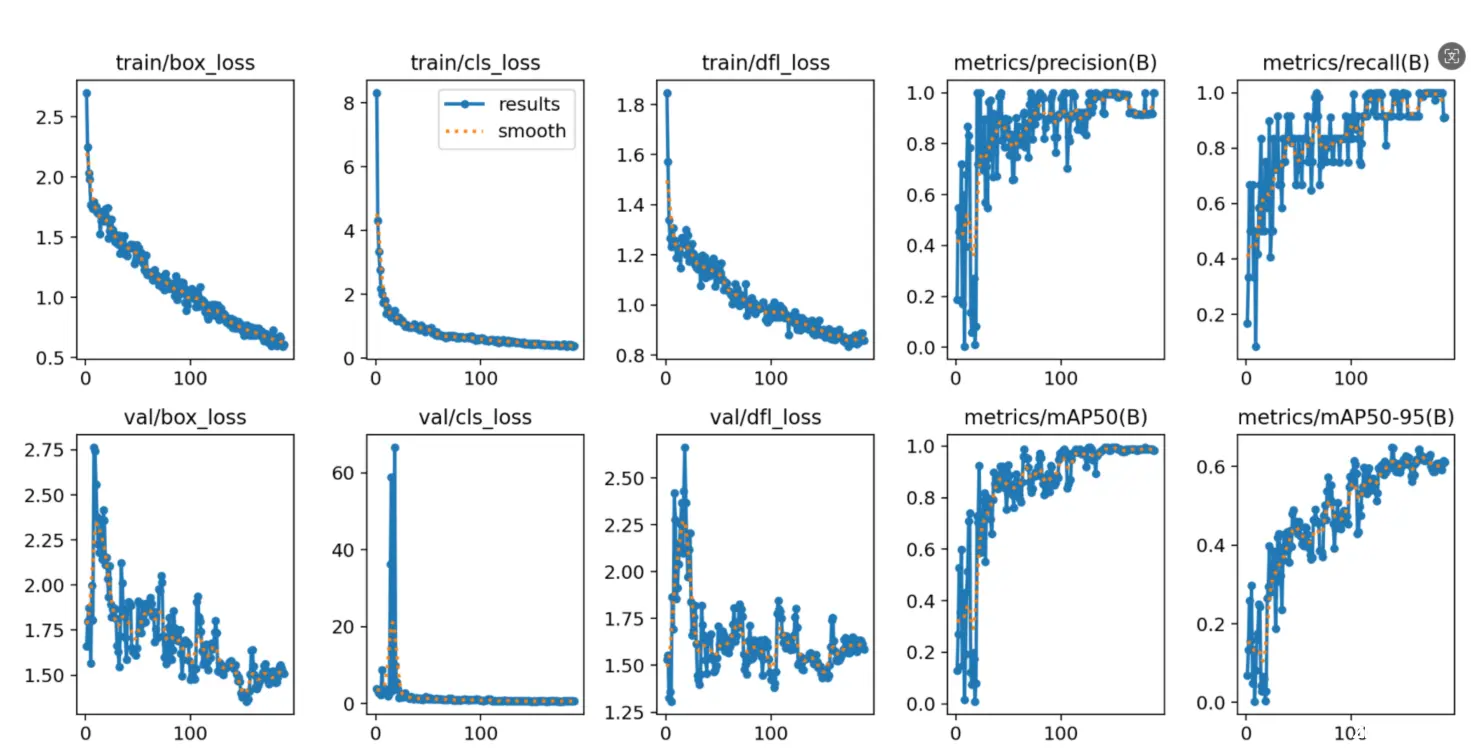
除了权重文件,我们发现还有一些训练结果可视化分析图,下面我们对其中几张进行查看!
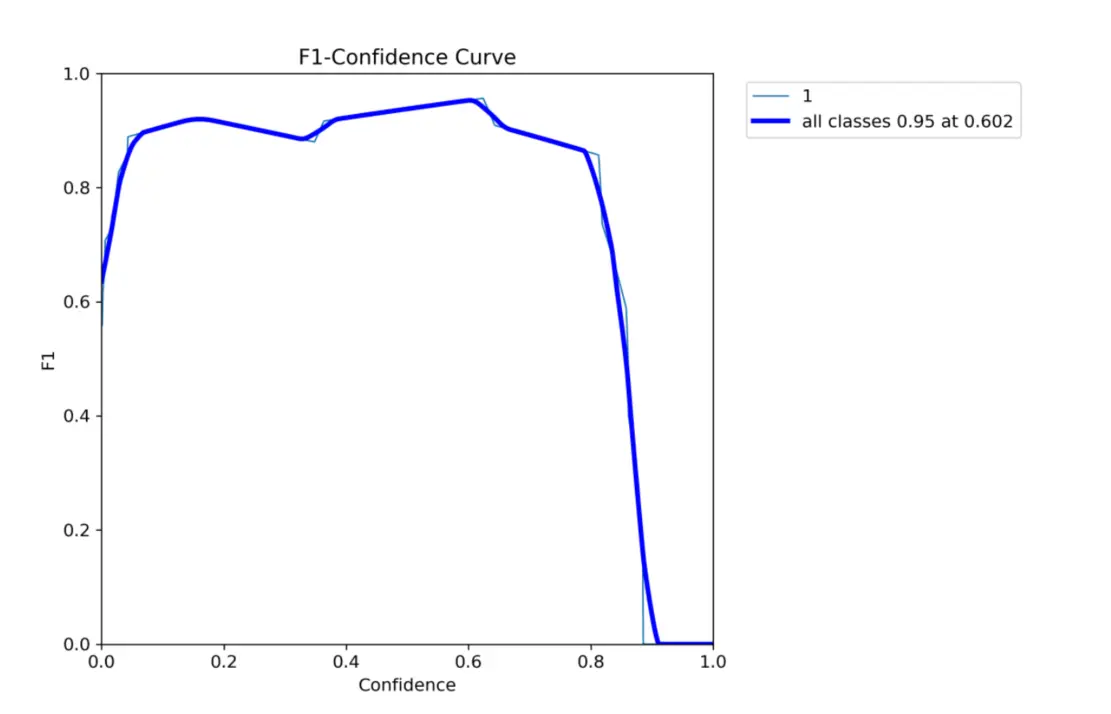
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值的取值范围是0到1,其中1表示最佳性能(即精确率和召回率都为1),而0表示最差性能(即精确率和召回率都为0)由上图可见模型在平衡精确率和召回率方面的表现都比较理想。
在目标检测中,损失函数扮演着至关重要的角色。它的主要作用是衡量模型预测结果与真实标签之间的差异或误差,并通过最小化这个差异来优化模型的参数,从而提高模型的预测准确性。
IoU系列损失函数简介
IoU(Intersection over Union):最基本的目标检测损失函数之一,计算预测框与真实框的交集与并集之比。然而,当预测框与真实框不相交时,IoU值为0,导致损失函数没有梯度。GIoU(Generalized Intersection over Union):针对IoU的缺点进行改进,引入了最小封闭形状C(可以包含预测框和真实框)的概念,并计算C中未覆盖预测框和真实框的面积占C总面积的比值,最后用IoU减去这个比值得到GIoU。GIoU能够在预测框与真实框不重叠时提供梯度信息。DIoU(Distance-IoU):进一步考虑了预测框与真实框中心点之间的距离信息,使损失函数在重叠时仍能为边界框提供移动方向。CIOU(Complete IoU):在DIoU的基础上增加了长宽比的一致性项,使损失函数更加全面和鲁棒。
识别命令
使用yolo predict来进行识别,model就是我们刚刚训练好的模型,source是你要拿来识别的图片文件夹路径。同时后面可以设置一些参数来调整你想要的识别结果。
yolo predict model=模型路径 source= 图片路径 conf=0.5 识别阈值
更多其他参数可参考下表 :
| Key
| Value
| Description
|
| <code>source
|
| source directory for images or videos
|
|
|
| object confidence threshold for detection
|
|
|
| intersection over union (IoU) threshold for NMS
|
|
|
| image size as scalar or (h, w) list, i.e. (640, 480)
|
|
|
| use half precision (FP16)
|
|
|
| device to run on, i.e. cuda device=0/1/2/3 or device=cpu
|
|
|
| show results if possible
|
|
|
| save images with results
|
|
|
| save results as .txt file
|
|
|
| save results with confidence scores
|
|
|
| save cropped images with results
|
|
|
| hide labels
|
|
|
| hide confidence scores
|
|
|
| maximum number of detections per image
|
|
|
| video frame-rate stride
|
|
|
| The line width of the bounding boxes. If None, it is scaled to the image size.
|
|
|
| visualize model features
|
|
|
| apply image augmentation to prediction sources
|
|
|
| class-agnostic NMS
|
|
|
| use high-resolution segmentation masks
|
|
|
| filter results by class, i.e. class=0, or class=[0,2,3]
|
|
|
| Show boxes in segmentation predictions
|
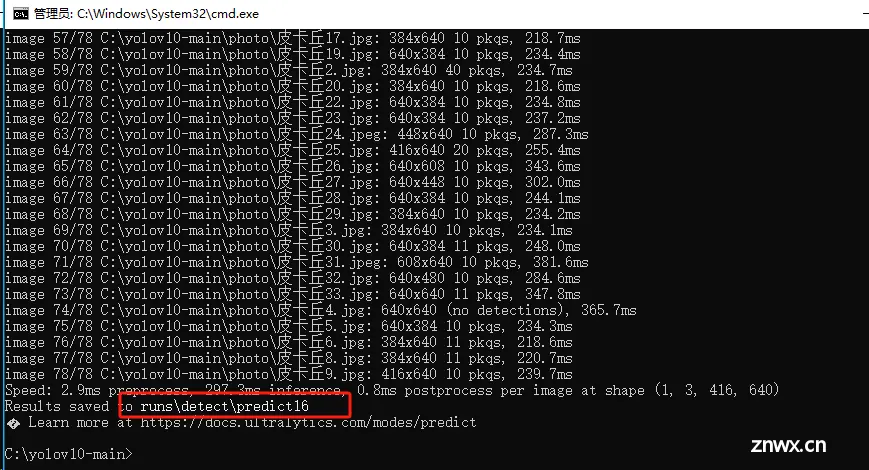
执行完识别命令后,可在输出信息中看到识别结果文件所在位置,detect\predict(数字会自动叠加)
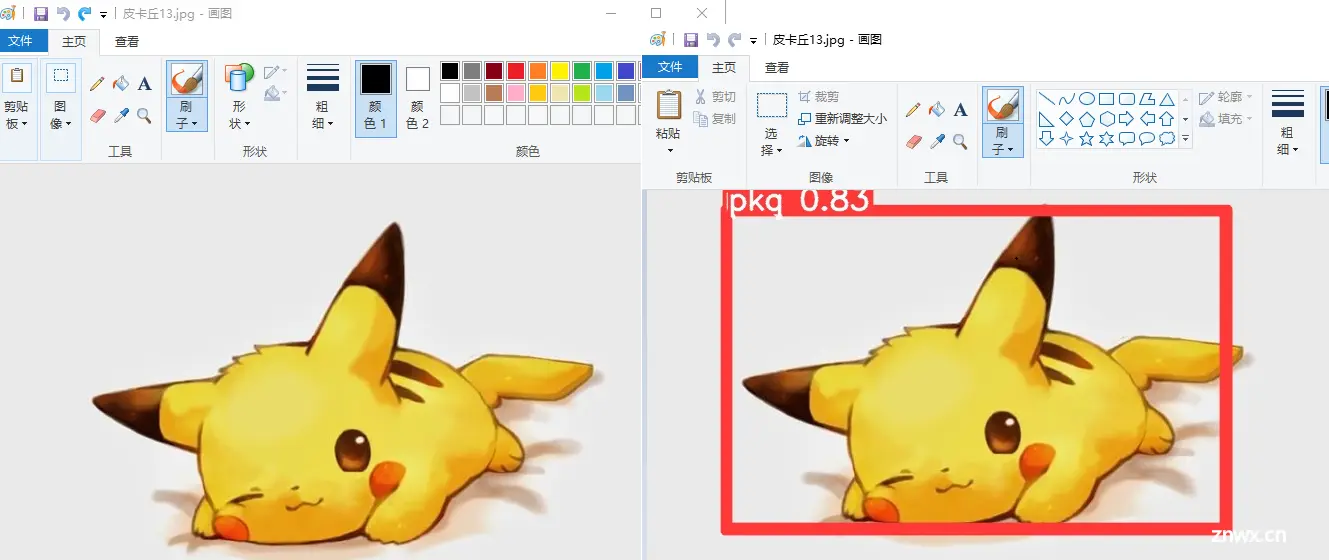
任意打开一张图片,找出识别前的图片对比一下,皮卡丘已经被框出来了,并打上我们设置的pkq标签。

至此~我们就完成了YOLOv10目标检测模型的训练与识别工作了!整个实验操作下来,Flexus云服务器X实例的表现都是非常出色的!
下一篇: Visual Studio 必备插件集合:AI 助力开发
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。