【大模型】AI视频课程制作工具开发
竹二木 2024-10-21 08:31:01 阅读 75
1. 需求信息
1.1 需求背景
讲师们在制作视频的过程中,发现录制课程比较麻烦,要保证环境安静,保证录制过程不出错,很容易反复重复录制,为了解决重复录制的工作量,想通过 ai 课程制作工具,来解决这些问题。
2. 业务分析
2.1 视频生成过程
视频素材来源: 首先由产品研发团队的产品、架构师协助提供基础资料,根据产品材料来输出ppt文档;素材上传:使用的授课课件材料,如:PPT 或 PDF(也有doc课件大纲、课程详细内容,现在我们基本上用不上),上传到AI视频制作工具平台;素材文本提取:a. 提取素材文本内容(ppt内容+备注);b. 将素材截图成图片;演讲稿制作:将第3步提取的文字,交由混元来生成讲课稿,这里可以人工校验句子合理性;演讲稿合成语音:将第4步生成的讲课稿合成音频文件;合成视频:将音频、图片合成视频。
其中,2~6可以合成一步,就是在有讲课稿的情况下,直接提取备注合成视频。
2.2 视频课程权限
数据隔离和安全:课程以空间的概念相互隔离, 用户使用OA登录系统后,默认不可见其他同事创建的空间,只能看到自己创建的空间。数据共享协作:空间创建者默认拥有空间管理权限,可以邀请其他同事协作;超级管理员:超级管理员课件所以课件,超级管理员不可配置,只能研发修改数据库角色。
2.4 发音修正
部分专业英文缩写发音不准的问题,可以通过SMAL标记语言修正发音,因此提供一个发音修正管理菜单,用户可以自定义发音部分单词。
2.5 用户登录限制
系统接入OA登录,只能在内网访问;给用户添加权限,必须在用户登录过系统之后,才能添加(必须用户登录之后,系统才会记录用户信息)。
3. 技术设计
3.1 视频制作流程
目前我们的技术方案是腾讯云语音合成(TTS)+视频合成(云点播)+混元大模型来搭建的。支持2种方式来生成视频:
无讲课稿的情况下,通过解析读取ppt文档的内容和备注, 调用混元大模型来生成演讲稿, 演讲稿生成语音, 再截取PPT的图片,来合成视频;有讲课稿的情况下, 支持一件生成讲课视频。
整体流程入下图所示:
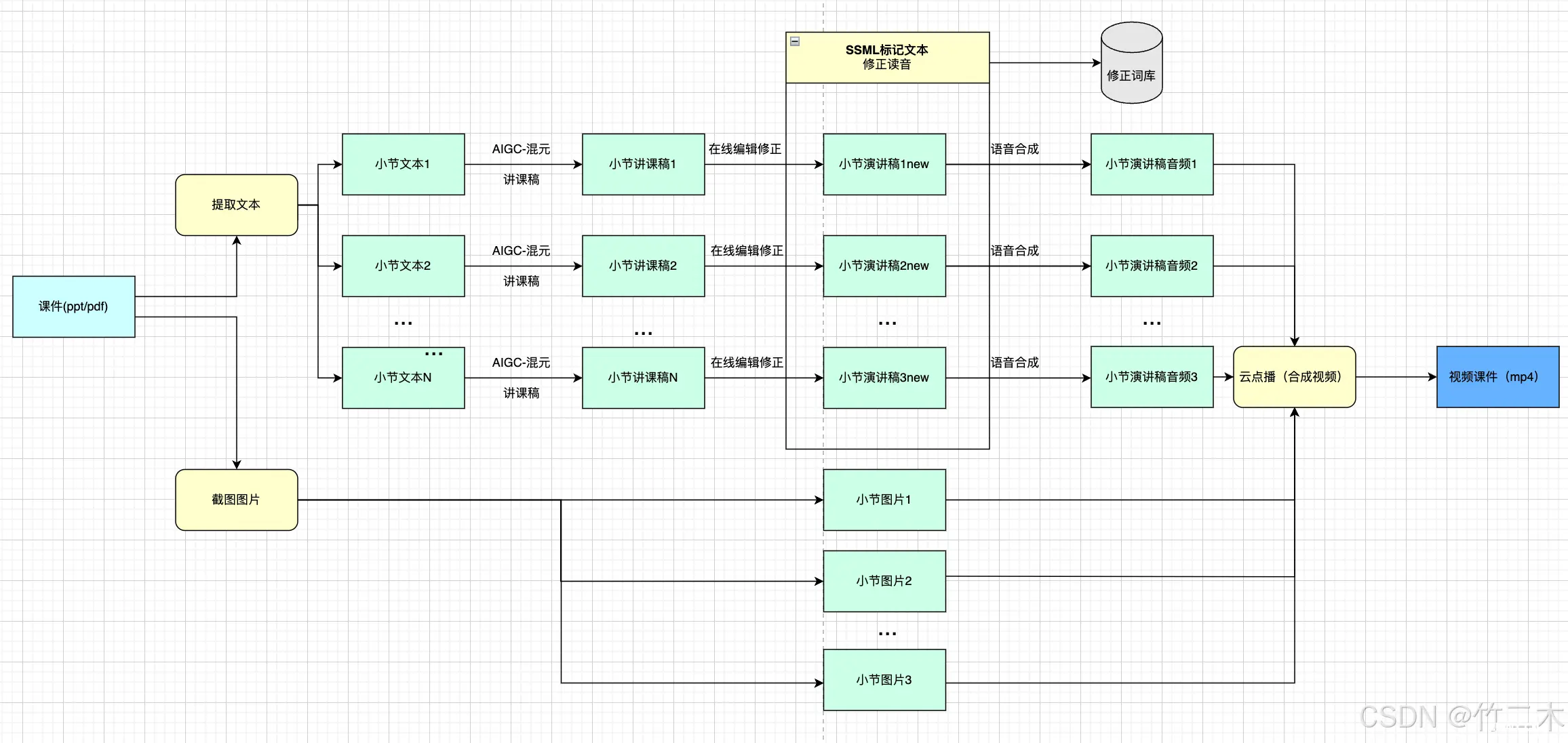
3.2 发音纠正
由于课程内容主要是腾讯云的产品培训,因此有很多腾讯云相关的专有英文名词和缩写,腾讯云TTS对这些词的合成不够理想,不过提供了SSML 标记语言,用来自定义纠正发音,如上图发音纠正部分。
3.3 相关技术工具
腾讯云对象存储cos,制作课程过程中的各种素材,包括:文件、图片、音频、视频等都是存储在cos里面数据万象: PPT转PDF使用的是cos 自带的数据万象能力,可以把ppt转换为pdf格式文件开源工具pptx:可以读取ppt的演讲稿的文本和备注;开源工具PyPDF2:可以把pdf文件截取成图;混元大模型:提供AIGC能力,写入prompt讲提取的课件文本生成讲课稿;语音合成(TTS):使用腾讯云TTS将文本生成生动的语音;视频合成:腾讯云点播将音频和图片按时间线生成视频;后端web框架:fastapi,一个python的http服务框架;前端框架:内部开源的TDesign。
4 问题
4.1 语音合成(TTS)
目前业务方使用反馈最多的是腾讯云TTS的语言合成效果问题,例如:
专有名词发音不正确;同一个语音类型发音过程中切换;中、英切换过程中出现不同发音。
针对上述问题已经在尝试2个不同的解决方案:
推动腾讯云TTS优化:已经拉通TTS产品团队在支持,并逐步在收集发音的base case;调研开源TTS语音合成大模型,目前已知的ChatTTS 和阿里开源的CosyVoice 都有非常流畅的效果;第三方云平台的TTS 实现,目前国内讯飞的合成效果也不错。
4.2 讲课稿生成
讲课稿的生成过程比较耗时,一个课程小节经常长达100+页ppt,每一页都需要AIGC生成后,还需要人工精调。
针对这个问题可以考虑:
增强知识库,随着课程制作素材的累积,我们将形成一个优质的知识库,可以提供大模型非常好的知识增强;个性化微调大模型:随着数据的积累,可以使用混元一站式训练平台,对针对性微调个性化模型专门用来优化演讲稿生成。
附件
主要python工具包
fastapi==0.111.0 // fastapi web框架python-pptx==0.6.23 // pptx 内容读取pdf2image==1.17.0 // pdf转图片tencentcloud-sdk-python==3.0.1132 // 调用腾讯云api
文本提取
<code>from pptx import Presentation
import PyPDF2
import tempfile,io,requests
from dependencies import FILE_NAME_MAX_LENGTH, new_file_name
from logger_config import logger
from repo import schemas
from typing import List
from fastapi import HTTPException
from starlette.status import HTTP_400_BAD_REQUEST, HTTP_200_OK
# 提取ppt中的正文和备注
def extract_info_from_ppt(ppt_url: str) -> List[schemas.PPtTextNode]:
# 下载PDF文件
logger.info('开始下载ppt文件: ' + ppt_url)
response = requests.get(ppt_url)
if response.status_code != HTTP_200_OK:
logger.error("file download failed : " + ppt_url)
raise HTTPException(
status_code=HTTP_400_BAD_REQUEST,
detail="文件下载失败",code>
)
pdf_bytes = response.content
# 将字节流转换为文件对象
file_obj = io.BytesIO(pdf_bytes)
# 加载 PowerPoint 文档
presentation = Presentation(file_obj)
# 备注内容
slide_infos : List[schemas.PPtTextNode] = []
# 遍历幻灯片
for slide in presentation.slides:
# 获取幻灯片上的文本
slide_text = ""
for shape in slide.shapes:
if hasattr(shape, "text"):
slide_text += shape.text
# 获取幻灯片的备注
notes_slide = slide.notes_slide
# 获取备注文本
notes_text = notes_slide.notes_text_frame.text
# 添加到备注列表
slide_infos.append(schemas.PPtTextNode(text=slide_text, note=notes_text))
return slide_infos
# 提取pdf中的内容
def extract_info_from_pdf(pdf_url: str):
# 下载PDF文件
logger.info('开始下载PDF文件: ' + pdf_url)
response = requests.get(pdf_url)
if response.status_code != HTTP_200_OK:
raise HTTPException(
status_code=HTTP_400_BAD_REQUEST,
detail="文件下载失败",code>
)
pdf_bytes = response.content
# 将字节流转换为文件对象
file_obj = io.BytesIO(pdf_bytes)
# 加载 PDF 文件
pdf_reader = PyPDF2.PdfReader(file_obj)
# 获取 PDF 文件的页数
num_pages = len(pdf_reader.pages)
# 遍历 PDF 文件的每一页
slide_infos : List[schemas.PPtTextNode] = []
for page_num in range(num_pages):
# 获取当前页
page = pdf_reader.pages[page_num]
# 提取页面内容
content = page.extract_text()
# 添加到备注列表
silde_info = schemas.PPtTextNode(text=content, notes="")code>
slide_infos.append(silde_info)
return slide_infos
pdf转图片
import os
from logic.qcloud import cosclient
import tempfile
from logger_config import logger
import requests,re
from pdf2image import convert_from_bytes
from typing import List
from repo import schemas
import tracemalloc
import config
from dependencies import FILE_NAME_MAX_LENGTH, new_file_name
# 定义一个函数来验证文件名是否安全
def is_safe_filename(filename):
# 使用正则表达式来匹配合法的文件名
return bool(re.match(r'^[\w\-.]+$', filename))
def pdf_url_to_images(pdf_url: str, space_id: int)->List[schemas.PPtToImage]:
# 下载PDF文件
logger.info('开始下载PDF文件: ' + pdf_url)
response = requests.get(pdf_url)
pdf_bytes = response.content
# 将PPT文件的每一页保存为图像
output_folder = tempfile.mkdtemp()
# 将PDF文件转换为图像
tracemalloc.start()
# 获取内存分配情况的快照
if config.get_settings().is_tracemalloc == True:
snapshot1 = tracemalloc.take_snapshot()
images = convert_from_bytes(pdf_bytes)
if config.get_settings().is_tracemalloc == True:
snapshot2 = tracemalloc.take_snapshot()
# 比较两个快照,找出内存分配差异
top_stats = snapshot2.compare_to(snapshot1, "lineno")
# 打印内存分配差异的统计信息
for stat in top_stats[:10]:
logger.info("读取文件后,内存分配差异: %s" % stat)
total_size = sum(stat.size for stat in snapshot2.statistics("lineno"))
# 将字节转换为合适的单位(如 MiB)
total_size_mib = total_size / (1024 * 1024)
logger.info(f"读取文件后,总内存分配: { total_size_mib:.2f} MiB")
#image_urls = []
file_infos : List[schemas.PPtToImage] = []
for index, image in enumerate(images):
image_path = os.path.join(output_folder, f"page_{ index + 1}.png")
image.save(image_path, "PNG")
# 上传图像到COS
url = ""
file_name = os.path.basename(image_path)
image_key = new_file_name(file_name, space_id)
if len(image_key) > FILE_NAME_MAX_LENGTH:
image_key = image_key[:FILE_NAME_MAX_LENGTH]
cosclient.put_object_file(image_path, image_key)
url = cosclient.get_presigned_url(image_key)
file_infos.append(schemas.PPtToImage(image_name=image_key, image_url=url))
logger.info(f"Uploaded { image_path} to { image_key}")
# 删除临时文件夹
for image_filename in os.listdir(output_folder):
# 验证文件名是否安全
if is_safe_filename(image_filename):
# 如果文件名安全,则删除文件
os.unlink(os.path.join(output_folder, image_filename))
else:
# 如果文件名不安全,记录日志并跳过删除操作
logger.warning(f"Unsafe filename detected: { image_filename}. Skipping deletion.")
os.rmdir(output_folder)
return file_infos
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。