丹摩智算:如何在云端开发一个AI应用——基于UNet的眼底血管分割案例
CSDN 2024-08-17 15:01:03 阅读 83
目录
0 写在前面1 云实例:配置选型与启动1.1 登录注册1.2 配置SSH密钥对1.3 创建实例1.4 登录云实例
2 云存储:数据集上传与下载3 云开发:眼底血管分割案例3.1 案例背景3.2 网络搭建3.3 网络训练3.4 模型测试
总结粉丝福利
0 写在前面
DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。<code>DAMODEL配备124G大内存和100G大空间系统盘,一键部署,三秒启动;覆盖从入门级到专业级GPU,满足各层次开发需求,使每一位开发者都能体验到顶级的计算性能和专属服务。
接下来,就以一个实际项目作为案例,体验丹摩智算<code>DAMODEL的开发流程,大家也可以滑到最后领取粉丝专属福利
1 云实例:配置选型与启动
1.1 登录注册
首先进入登录界面注册并登录账号

1.2 配置SSH密钥对
配置SSH密钥对的作用是后续远程登录服务器不需要密码验证,更加方便。
首先创建本地公钥,进入本地<code>.ssh目录输入ssh-keygen -o命令,这里文件名可以设置为id_dsa,也可以是其他任意名字
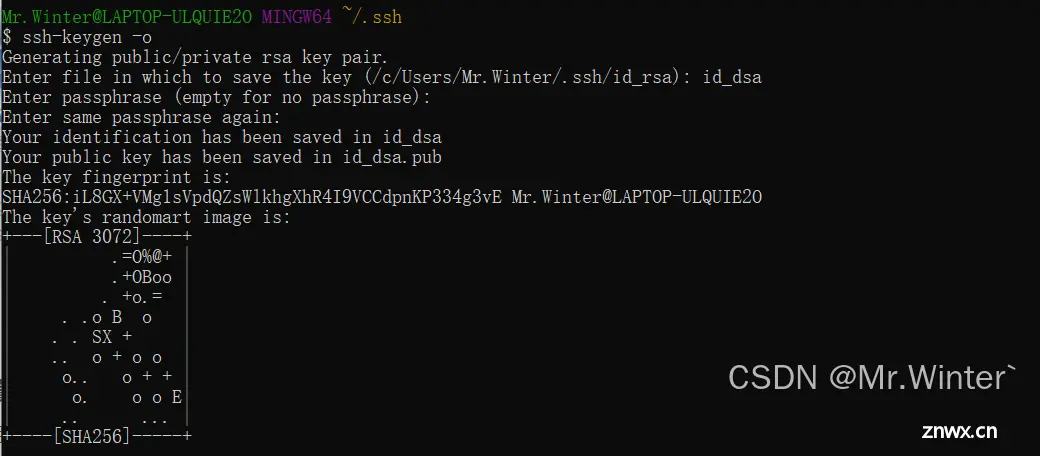
之后我们可以在<code>.ssh目录看到刚刚创建的两个文件
id_dsaid_dsa.pub
其中id_dsa.pub就是需要的公钥文件
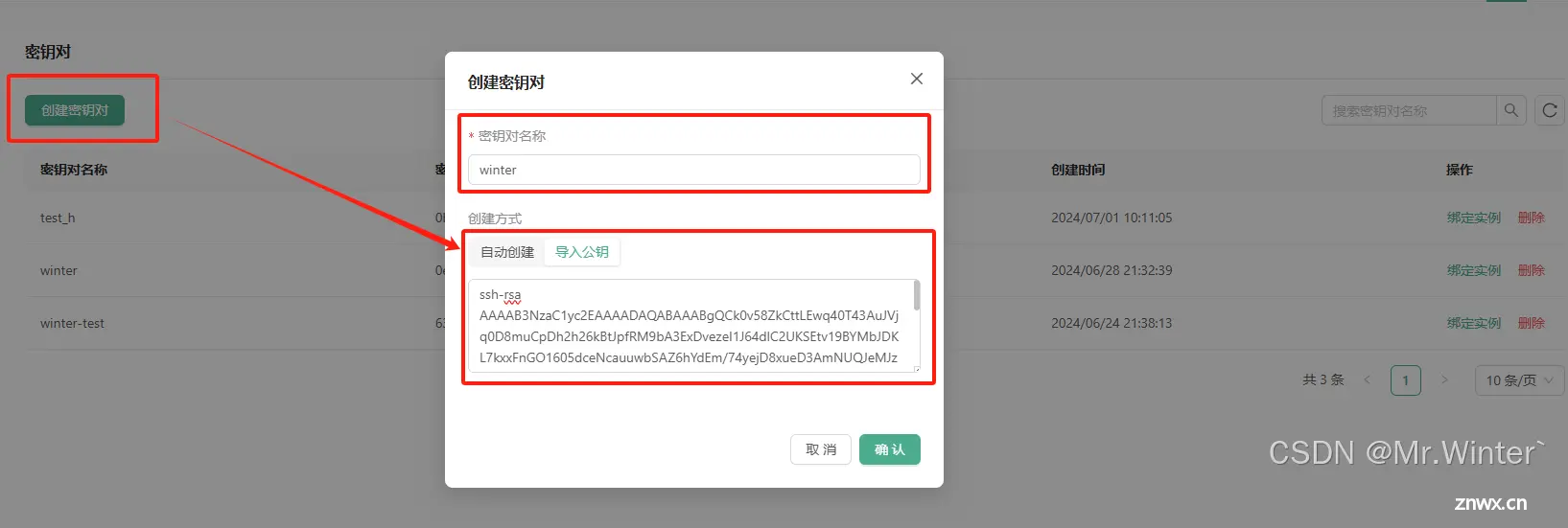
进入密钥对配置,创建密钥对,将id_dsa.pub的内容复制到这里就可以
1.3 创建实例
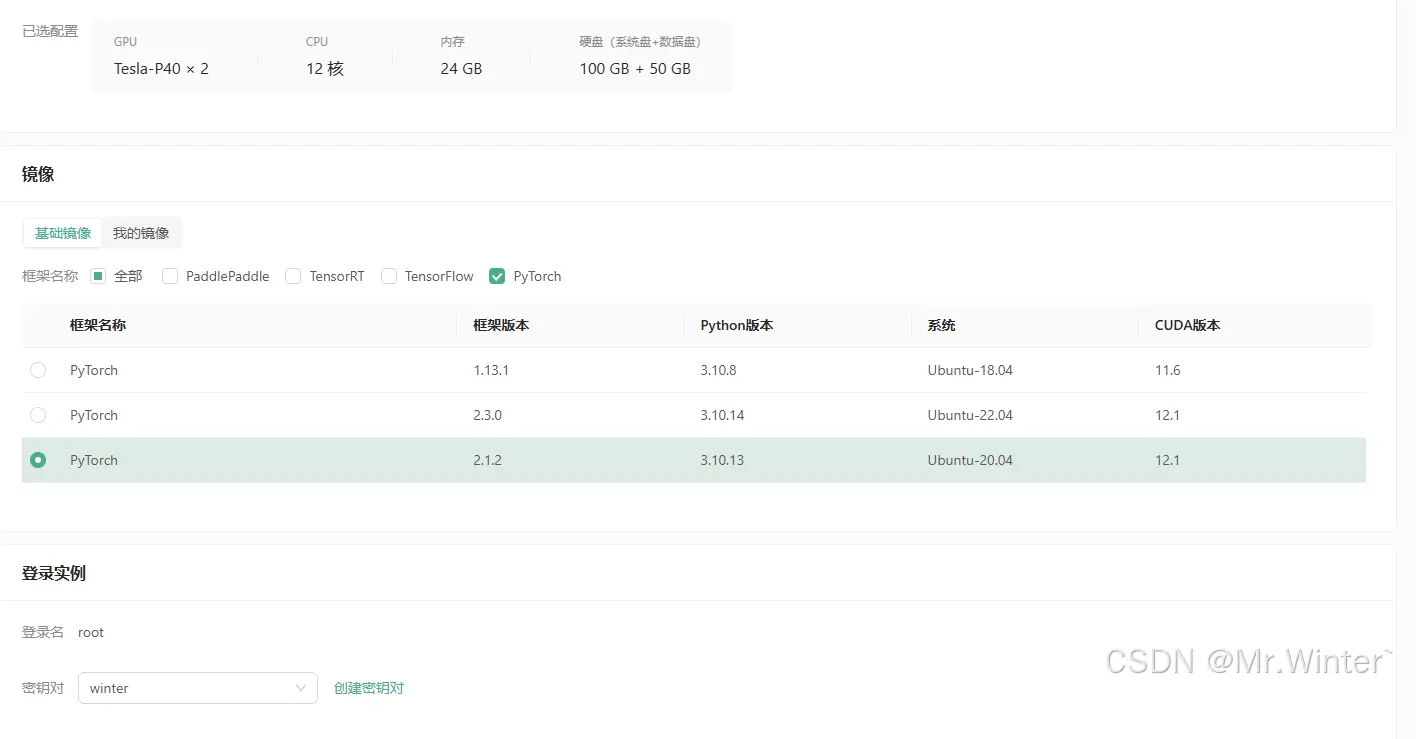
进入GPU云实例,点击创建实例。如下图所示,按需选择需要的GPU型号和镜像
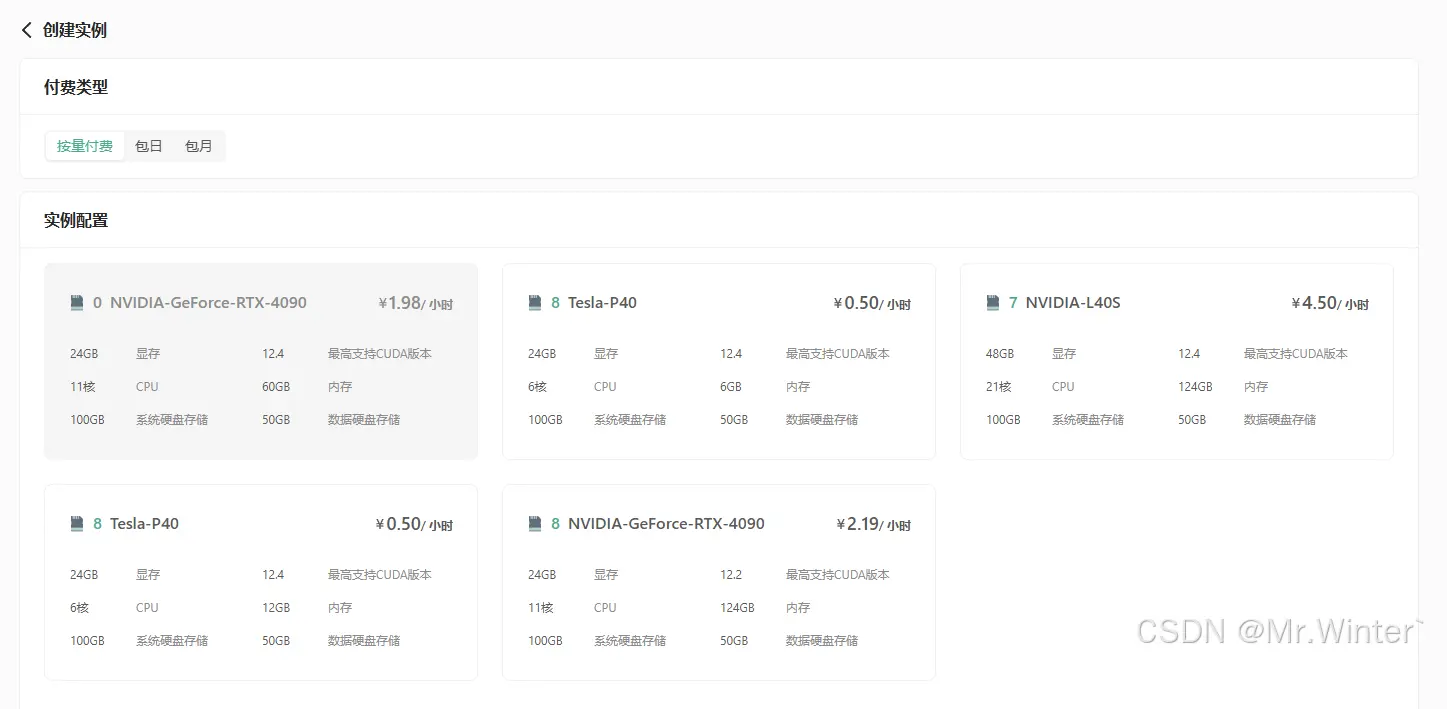
我这里选择的配置如下,大家可以参考。需要注意的是,这里记得选择之前创建的密钥对。一切确认完成后,点击立即创建即可
1.4 登录云实例
等待实例创建完成后,点击复制“访问链接”。

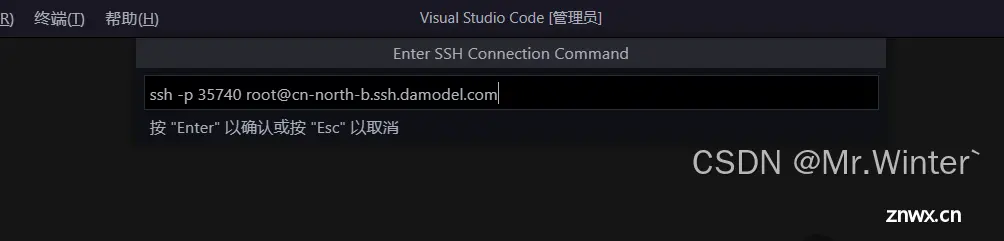
接着来到任意一个SSH连接终端进行云实例登录,我这里选择的是VSCode,如下所示
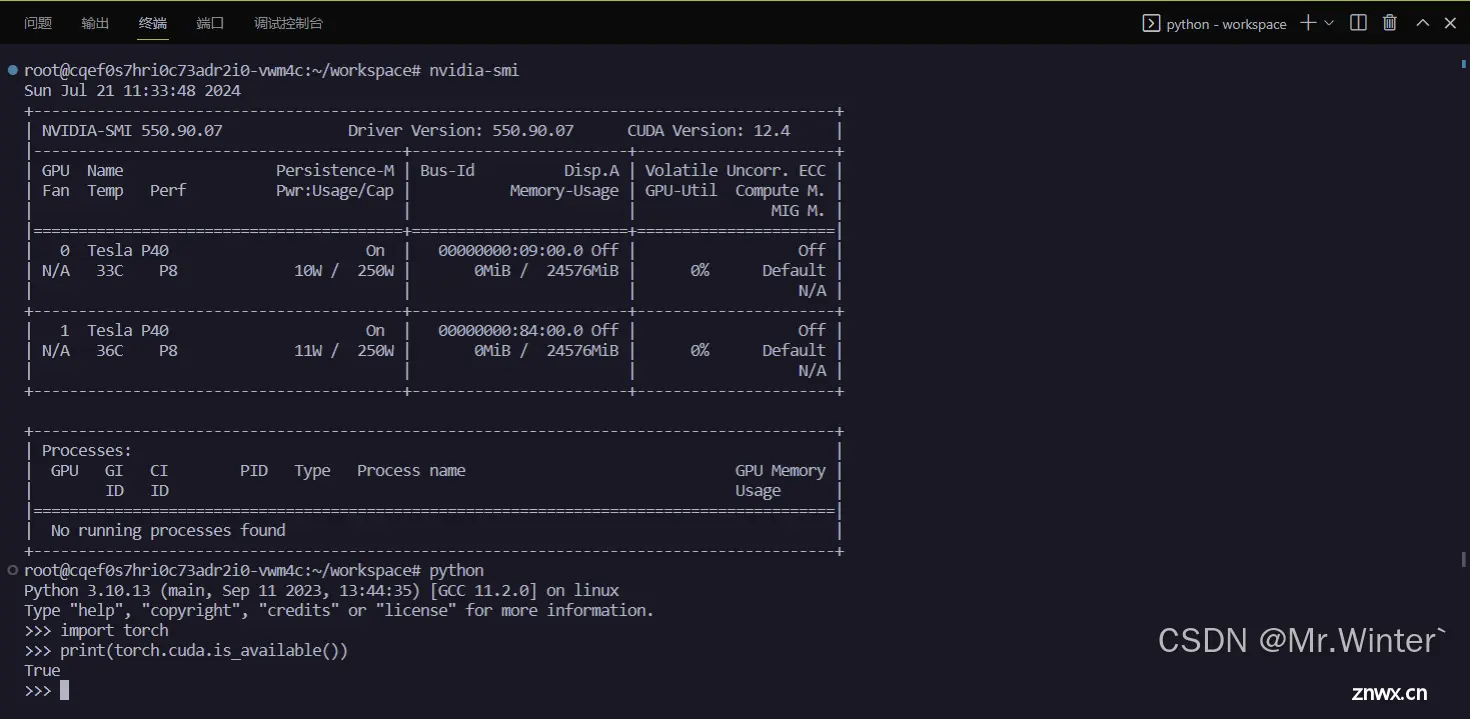
登录成功后,通过
<code>nvidia-smi
torch.cuda.is_available()
简单验证一下功能即可,如下所示即为成功
2 云存储:数据集上传与下载
文件存储为网络共享存储,可挂载至的不同实例中。相比本地数据盘,其优势是实例间共享,可以多点读写,不受实例释放的影响;此外存储后端有多冗余副本,数据可靠性非常高;但缺陷是IO性能一般
考虑到以上优劣,推荐使用方式:将重要数据或代码存放于文件存储中,所有实例共享,便利的同时数据可靠性也有保障;在训练时,需要高IO性能的数据(如训练数据),先拷贝到实例本地数据盘,从本地盘读数据获得更好的IO性能。如此兼顾便利、安全和性能。
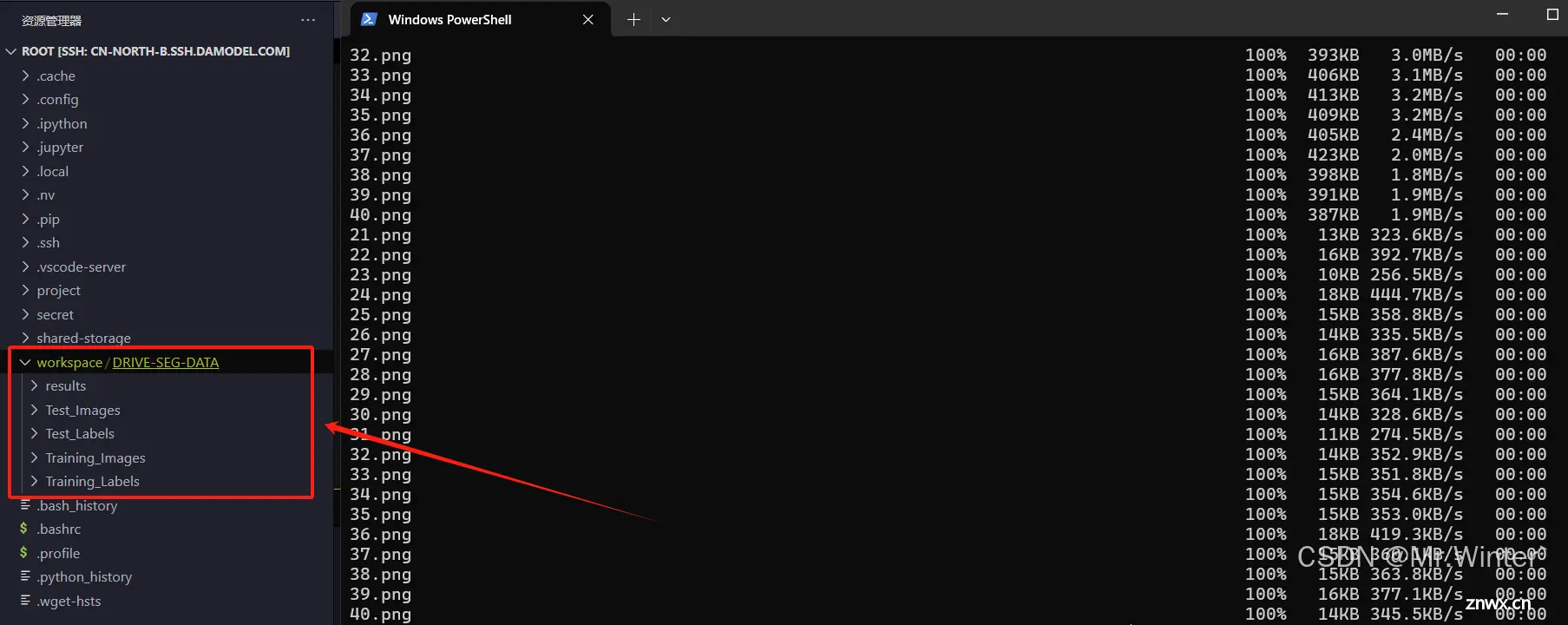
接下来,我们将训练数据上传到云实例数据盘中。使用<code>scp工具如下
scp -rP 35740 ./DRIVE-SEG-DATA root@cn-north-b.ssh.damodel.com:/root/workspace
具体地:
35740与cn-north-b.ssh.damodel.com分别为端口号和远程地址,请参考1.4节替换为自己的参数./DRIVE-SEG-DATA是本地数据集路径/root/workspace是远程实例数据集路径
可以看到数据上传成功
数据的下载也是类似的命令
<code>scp -rP 35740 root@cn-north-b.ssh.damodel.com:/root/workspace ./DRIVE-SEG-DATA
本文提到的数据集可以在DRIVE数据集中下载
3 云开发:眼底血管分割案例
3.1 案例背景
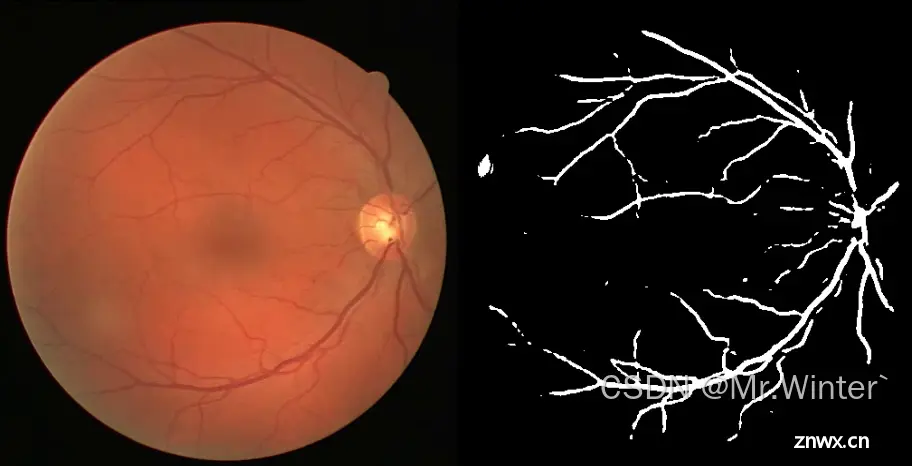
眼底也称为眼球的内膜,包括黄斑、视网膜和视网膜中央动静脉等结构。在临床医学中,眼底图像是眼科医生对眼疾病患者进行诊断的重要依据。随着深度学习的发展,医学影像分割技术产生了深远的变化,尤其是卷积神经网络AlexNet、VGGNet、GoogLeNet、ResNet等,能够学习到更加抽象和高级的特征表示,从而实现更加精确的分割结果。深度学习模型在大规模数据上训练后,通常能够获得更好的泛化能力,即对未见过的数据也能做出相对准确的预测。对于医学影像分割来说,这意味着模型可以更好地适应不同类型和来源的医学图像数据,提高了分割结果的可靠性和稳定性。同时,深度学习技术支持端到端的学习方式,即从原始输入数据直接学习到最终的分割结果,无需手工设计复杂的特征提取和预处理流程。这简化了分割算法的开发流程,提高了效率和准确性。此外,医学影像数据常常包含多种模态,如CT、MRI等。深度学习技术能够更好地处理多模态数据,实现不同模态之间的信息融合,从而提高了医学影像分割的准确性和全面性
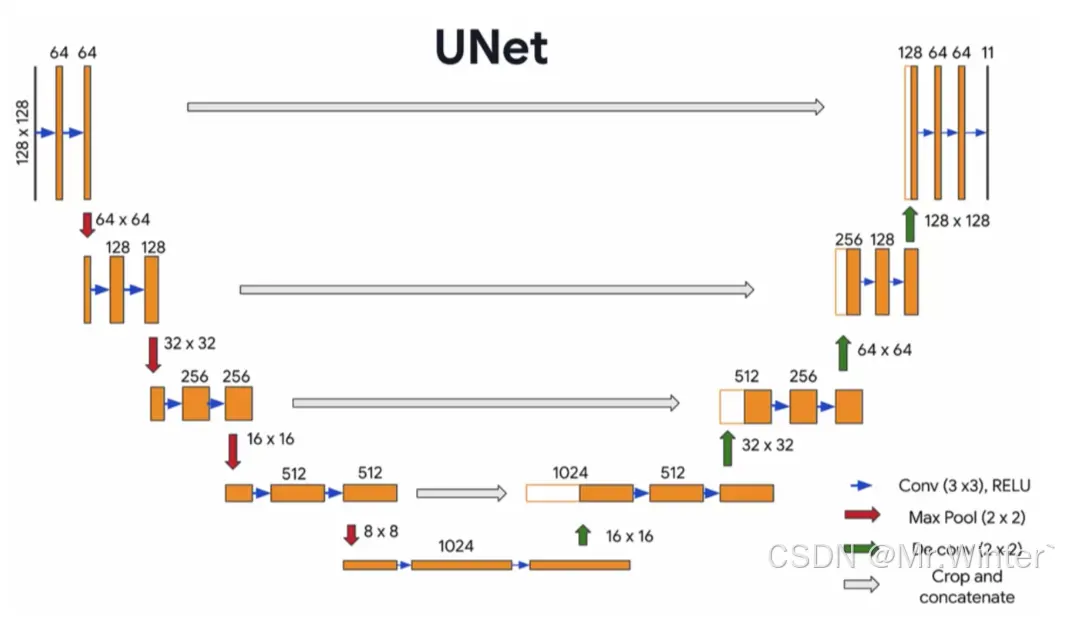
本次实践,我们采用UNet进行眼底血管医学图像分割任务。UNet是一种被广泛应用于语义分割任务的网络结构,其编码器-解码器结构以及跳跃连接的设计,使其能够有效地捕获图像中不同尺度的特征信息,从而在眼底血管分割任务中取得较好的效果。同时,在推理阶段,UNet采用全卷积网络结构,能够快速对新的眼底图像进行血管分割,为临床应用提供了实时性支持。
3.2 网络搭建
选用U-Net 网络结构作为基础分割模型的原因在于其通过编解码器架构,有效地结合局部信息和全局信息,提高分割准确性;同时,U-Net的跳跃连接结构有助于保留和恢复图像中的细节和边缘信息,且在小样本情况下表现优异,能够充分利用有限数据进行有效训练,广泛应用于医学图像分割任务中。网络架构如下
<code>class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256, bilinear)
self.up2 = Up(512, 128, bilinear)
self.up3 = Up(256, 64, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
3.3 网络训练
基于 PyTorch 的神经网络训练流程可以分为以下步骤(不考虑前期数据准备和模型结构):
定义损失函数
根据任务类型选择合适的损失函数(loss function),如分类任务常用的交叉熵损失(Cross-Entropy Loss)或回归任务中的均方误差(Mean Square Error)。
选择优化器
选择合适的优化器(optimizer),如随机梯度下降(SGD)、Adam 或 RMSprop,并设置初始学习率及其它优化参数。
训练模型
在训练过程中,通过迭代训练数据集来调整模型参数。每个迭代周期称为一个 epoch。对于每个 epoch,数据会被分成多个 batch,每个 batch 被输入到模型中进行前向传播、计算损失、反向传播更新梯度,并最终优化模型参数。
保存模型
当满足需求时,可以将训练好的模型保存下来,以便后续部署和使用。
根据这个步骤编写以下代码
def train_net(net, device, data_path, epochs=40, batch_size=1, lr=0.00001):
dataset = Dateset_Loader(data_path)
per_epoch_num = len(dataset) / batch_size
train_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True)
optimizer = optim.Adam(net.parameters(),lr=lr,betas=(0.9, 0.999),eps=1e-08, weight_decay=1e-08,amsgrad=False)
criterion = nn.BCEWithLogitsLoss()
best_loss = float('inf')
loss_record = []
with tqdm(total=epochs*per_epoch_num) as pbar:
for epoch in range(epochs):
net.train()
for image, label in train_loader:
optimizer.zero_grad()
image = image.to(device=device, dtype=torch.float32)
label = label.to(device=device, dtype=torch.float32)
pred = net(image)
loss = criterion(pred, label)
pbar.set_description("Processing Epoch: {} Loss: {}".format(epoch+1, loss))
if loss < best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
loss.backward()
optimizer.step()
pbar.update(1)
loss_record.append(loss.item())
plt.figure()
plt.plot([i+1 for i in range(0, len(loss_record))], loss_record)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.savefig('/root/shared-storage/results/training_loss.png')
运行这个脚本,可以在终端看到进度

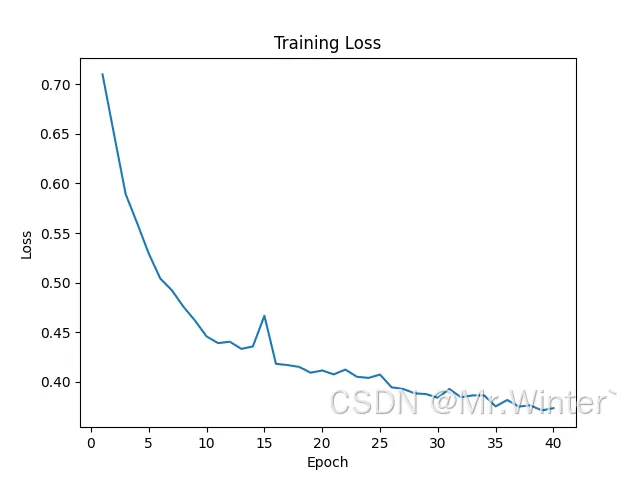
训练损失函数如下,可以看到已经收敛
3.4 模型测试
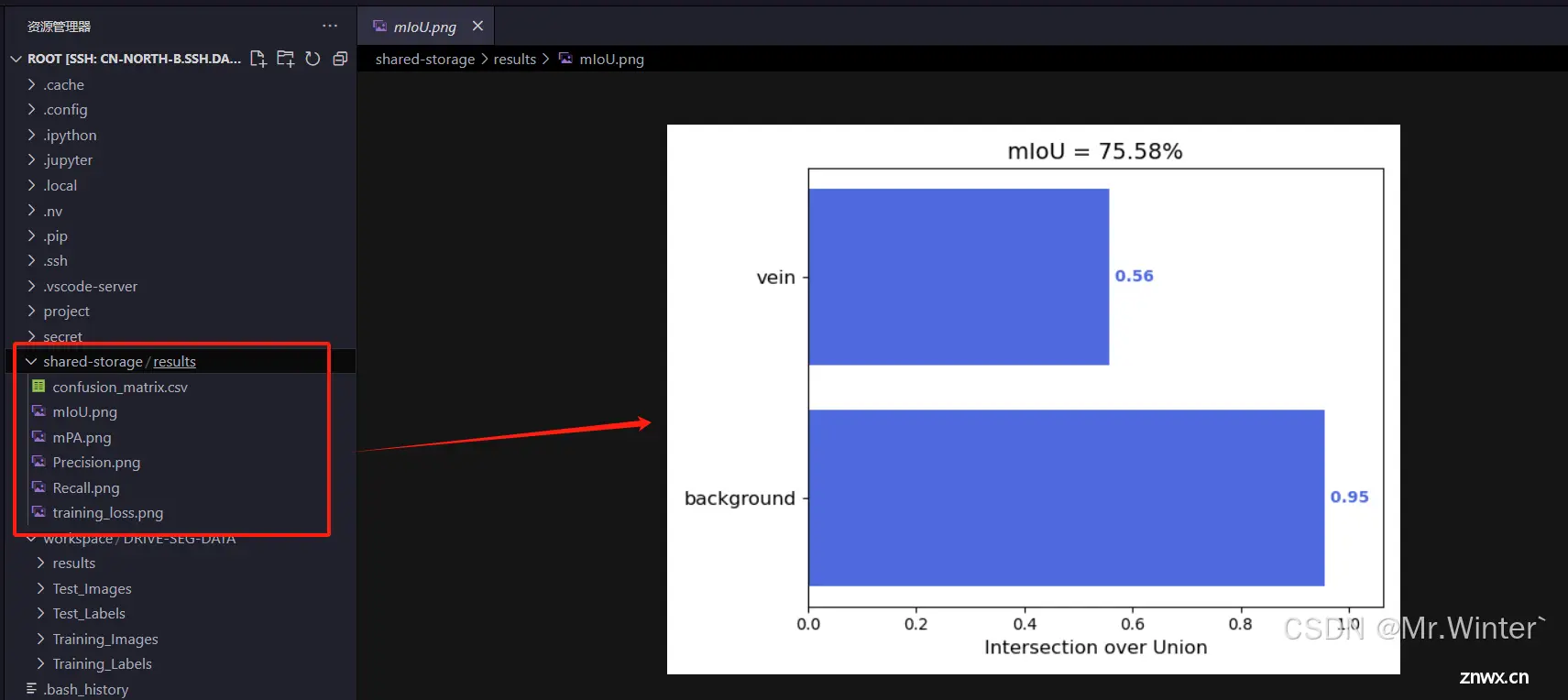
测试逻辑如下所示,主要是计算IoU指标
<code>def cal_miou(test_dir="/root/workspace/DRIVE-SEG-DATA/Test_Images",code>
pred_dir="/root/workspace/DRIVE-SEG-DATA/results", gt_dir="/root/workspace/DRIVE-SEG-DATA/Test_Labels",code>
model_path='best_model_drive.pth'):code>
name_classes = ["background", "vein"]
num_classes = len(name_classes)
if not os.path.exists(pred_dir):
os.makedirs(pred_dir)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = UNet(n_channels=1, n_classes=1)
net.to(device=device)
net.load_state_dict(torch.load(model_path, map_location=device))
net.eval()
img_names = os.listdir(test_dir)
image_ids = [image_name.split(".")[0] for image_name in img_names]
time.sleep(1)
for image_id in tqdm(image_ids):
image_path = os.path.join(test_dir, image_id + ".png")
img = cv2.imread(image_path)
origin_shape = img.shape
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
img = cv2.resize(img, (512, 512))
img = img.reshape(1, 1, img.shape[0], img.shape[1])
img_tensor = torch.from_numpy(img)
img_tensor = img_tensor.to(device=device, dtype=torch.float32)
pred = net(img_tensor)
pred = np.array(pred.data.cpu()[0])[0]
pred[pred >= 0.5] = 255
pred[pred < 0.5] = 0
pred = cv2.resize(pred, (origin_shape[1], origin_shape[0]), interpolation=cv2.INTER_NEAREST)
cv2.imwrite(os.path.join(pred_dir, image_id + ".png"), pred)
hist, IoUs, PA_Recall, Precision = compute_mIoU_gray(gt_dir, pred_dir, image_ids, num_classes, name_classes)
miou_out_path = "/root/shared-storage/results/"
show_results(miou_out_path, hist, IoUs, PA_Recall, Precision, name_classes)
模型保存的时候保存到共享存储路径/root/shared-storage,其他实例可以直接从共享存储中获取训练后的模型
总结
整体体验丹摩智算<code>DAMODEL后,我发现它是一个非常强大且易于使用的代码开发平台。首先它提供了多种不同的开发环境,可以轻松地选择最熟悉或最适合用户需求的环境来构建、训练和部署应用程序,而无需考虑配置的问题。在案例中可以看到,丹摩智算DAMODEL提供了预构建的框架,即使临时安装依赖也很方便。
总的来说,和现有平台相比,丹摩智算DAMODEL核心在于快速启动,便捷开发,非常适合和各个应用领域结合,快速提供相关的解决方案。
粉丝福利
丹摩智算低价狂欢节开始,点击注册链接即可享受免费试用,还有4090、显示器等神秘好礼等待大家!
下一篇: 【人工智能】YOLOv10实时目标检测模型在香橙派AIPro上的首次体验!
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。