打造全场景、跨领域、多模态的AI工作流 | 开源图像标注工具 X-AnyLabeling v2.4.0 正式发布!
CVHub 2024-09-18 09:31:04 阅读 61
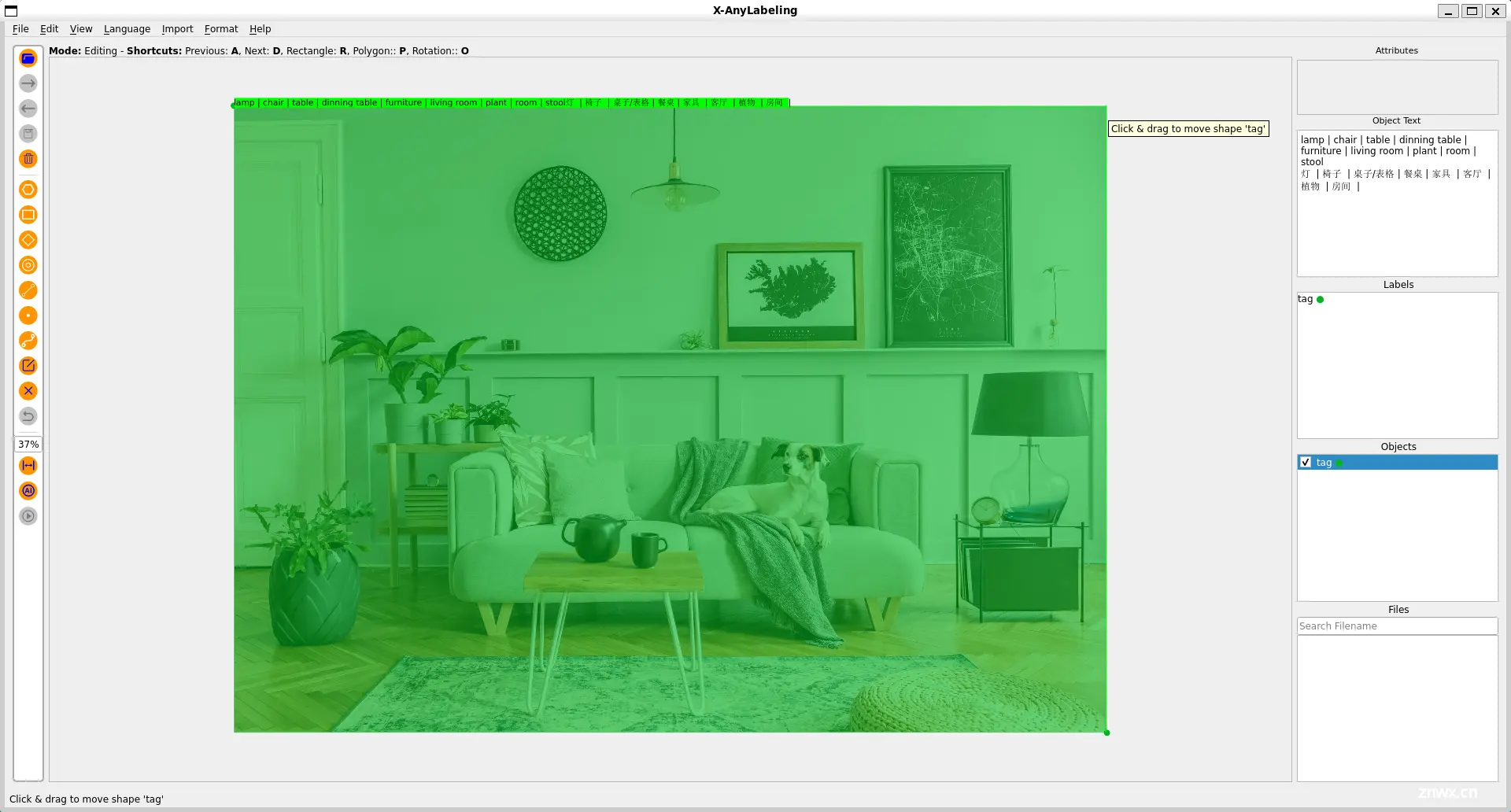
项目主页:https://github.com/CVHub520/X-AnyLabeling
安装教程:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/get_started.md
用户手册:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/user_guide.md
X-AnyLabeling

X-AnyLabeling 是一款基于AI推理引擎和丰富功能特性于一体的强大辅助标注工具,其专注于实际应用,致力于为图像数据工程师提供工业级的一站式解决方案,可自动快速进行各种复杂任务的标定。
功能特性
图像和视频文件的标注
作为一款主打视觉标定的应用,X-AnyLabeling 除了支持图像级的标注功能外,还特别引入了对视频文件的一键解析和自动标注功能。
多样化的标注样式
为满足多样化的标定需求,X-AnyLabeling 提供以下七种常规的标注样式,以适应不同的AI训练场景:
| 标注样式 | 描述 | 适用场景 |
|---|---|---|
| 矩形框 | 提供了一种快速框选目标对象的方式 | 目标检测、物体跟踪等基本任务 |
| 多边形 | 允许用户通过绘制不规则形状来精确标注目标区域 | 图像分割、显著性检测等复杂任务 |
| 旋转框 | 可以更准确地描述物体的方向和姿态 | 旋转目标检测 |
| 点 | 允许用户在图像上标记特定的关键点 | 姿态估计、关键点检测等任务 |
| 线段 | 适用于标注直线关系的场景 | 道路标线、简单的图形边界等 |
| 折线段 | 用户可以连续绘制折线来标注弯曲的线条 | 车道线检测等任务 |
| 圆形 | 提供了一种便捷的圆形目标标注方式 | 车辆轮胎、瞳孔等圆形目标标注场景 |
同时也支持图像及对象级的标签分类和描述,适用于图像分类(Image Classification)、图像描述(Image Captioning)及图像标签(Image Tagging)任务。此外,对于 v2.4.0 及以上的版本,支持 KIE 场景在的 SER 和 RE 标定任务,详情可参见后续的 OCR 任务章节。
丰富的导入导出格式
为了进一步提升数据处理效率,确保大家能够轻松快捷地将数据进行导入与导出,X-AnyLabeling 精心设计并集成了对当前市场上各大主流训练框架,如YOLO、OpenMMLab、PaddlePaddle等,所广泛使用的数据集格式的全面支持。这一功能大大简化了数据准备工作流程,让用户能够更加专注于模型训练和优化。
集成多种SOTA级的AI模型

作为最主打的核心亮点,X-AnyLabeling 中内置了多领域各方向最先进的深度学习算法,包括但不仅限于经典的YOLO以及热门的SAM和Grounding系列等算法,目前仍在不断扩充中,详情可访问以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/model_zoo.md
当然,我们也提供了详细的用户手册来支持导入用户训练的自定义模型,具体可参考以下教程:
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/custom_model.md
当您选择开启 AI 模型应用时,您可以进行单帧图像预测,也可以选择一键批量推理当前任务。此外,针对不同的算法模型,我们也提供了不同的用户配置,除了配置文件外,也支持直接在界面通过 GUI 进行设置。
更进一步,您还能够通过组合多样的基础模型,并结合X-AnyLabeling提供的丰富UI组件,轻松构建出更为复杂和高级的应用场景,实现更深入的定制化需求。此部分内容将会在后续章节详细为大家介绍。
多硬件环境和跨平台应用
X-AnyLabeling 支持在不同硬件环境下运行。除了常规的 CPU 推理外,还引入了 GPU 加速推理支持。当前AI模型的推理后端适配 OnnxRunTime,用户仅需将训练的模型导出为统一的 ONNX 文件后便可轻松集成到工具中。当然,您也可以方便的集成 Pytorch、OpenVINO 或者是 TensorRT 等后端。
此外,X-AnyLabeling 同时也具备多平台兼容性,能够在 Windows、Linux 和 MacOS 等不同操作系统环境下流畅运行。不仅如此,平台还提供一键编译脚本,赋予用户根据其具体需求自行编译系统的能力,使用户能够随时随地轻松地分发应用,为其提供更加灵活的定制和部署体验,从而进一步简化工具的安装流程。
详细的帮助文档
一份好的帮助文档,是用户解决问题的关键。这里,笔者精心为大家准备了全面而详尽的帮助文档,旨在为用户提供清晰的操作指南和快速的问题解决方案。无论您是初学者还是资深用户,这些文档都能助您快速上手,高效应对各种挑战。
具体地,你可以通过以下链接进行访问:
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/user_guide.md
完善的社区支持
最后,笔者也一直致力于精心维护 X-AnyLabeling 社区的发展。因此,如果您在使用过程中遇到任何问题、迸发任何想法或拥有宝贵建议,我诚挚地邀请并鼓励各位在issue区或讨论区积极提出和交流。您的每一条反馈都是前进的源动力。
基础视觉任务
图像分类
图像分类被誉为计算机视觉领域的“Hello World”任务,核心在于将整张图像归类到特定的标签或类别。如上图所示,该任务通常分为两个子类别:
多类别分类(Multiclass classification):在多类别分类任务中,每张图像被分配到一个且仅一个预定义的类别中。这意味着图像的内容被限定在几个互斥的类别之中,例如猫、狗、汽车等。在这种分类方式下,模型的任务是确定图像最有可能属于哪个单一类别。例如,在识别动物种类的任务中,一张图片只能被分类为猫、狗或鸟中的一个。多标签分类(Multilabel classification):与多类别分类不同,多标签分类允许一张图像同时属于多个类别。在这种情况下,图像中的内容可能涉及多个标签,而这些标签之间并不互斥。例如,一张图片可能同时包含一只猫和一只狗,因此该图片将被同时标记为“猫”和“狗”。多标签分类模型需要识别图像中的所有相关元素,并为每个元素分配相应的标签。

在 X-AnyLabeling 中,你可以非常方便的通过内置的 Resnet50 和 InternImage,或者是 yolov5-cls 和 yolov8-cls 图像分类模型进行预打标。除了图像级的分类任务外,也支持实例级的分类任务:

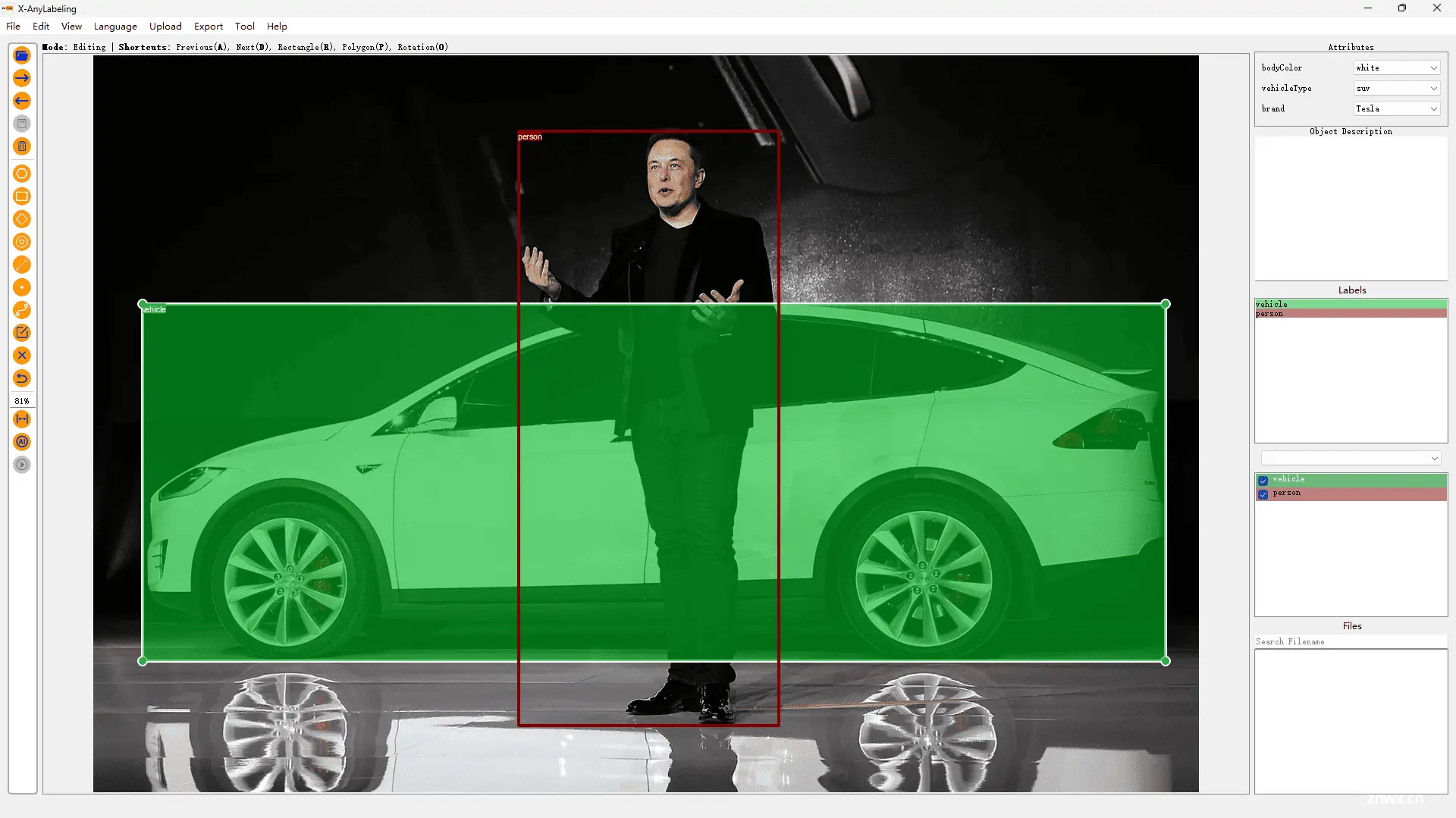
当然,对于更为复杂的 多任务分类(Multitask classification) 也是同样支持的,这意味着你可以基于 X-AnyLabeling 为不同的对象轻松的构建多种属性:
当前,X-AnyLabeling 中适配了 paddlepaddle 开源的 PULC 车辆属性(Vehicle Attribute)和行人属性(Person Attribute)模型。整体的用户界面(UI)设计也参照 CVAT 的标注范式,为用户提供更加一致和友好的体验。详情可参考以下教程:
https://github.com/CVHub520/X-AnyLabeling/tree/main/examples/classification
目标检测
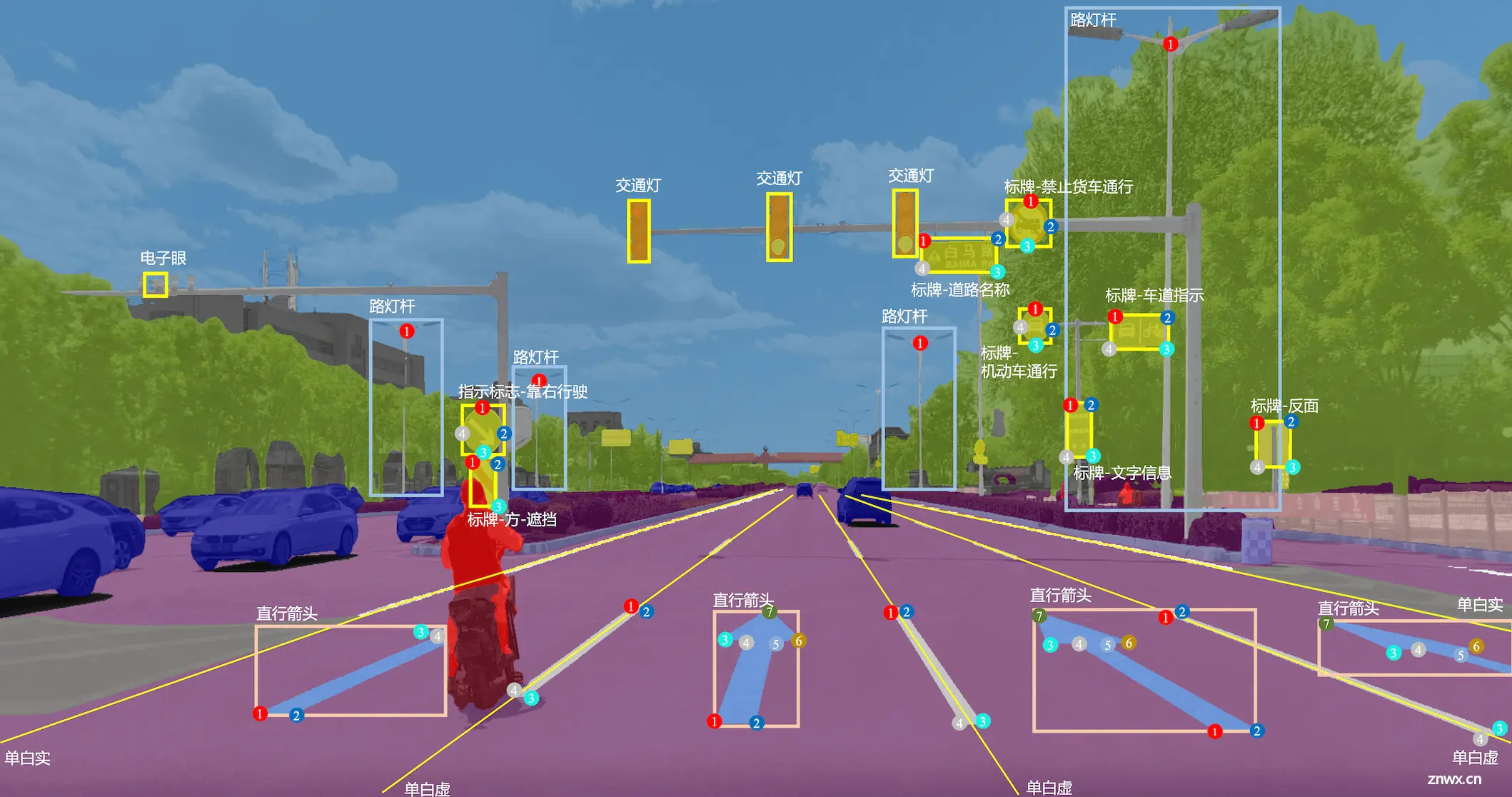
目标检测是计算机视觉领域中一项非常基础且重要的技术,它旨在识别并定位图像或视频中的各种物体,同时为每个检测到的物体绘制一个边界框并给出它所属的类别。
当前,X-AnyLabeling 中内置了多款主流的目标检测器,包括但不仅限于:
rtdetr、rtdetrv2damo_yolo、gold_yolo、yolox、yolo_nas、yolo_worldyolov5(适配5.0~7.0版本)、yolov6、yolov7、yolov8、yolov9、yolov10

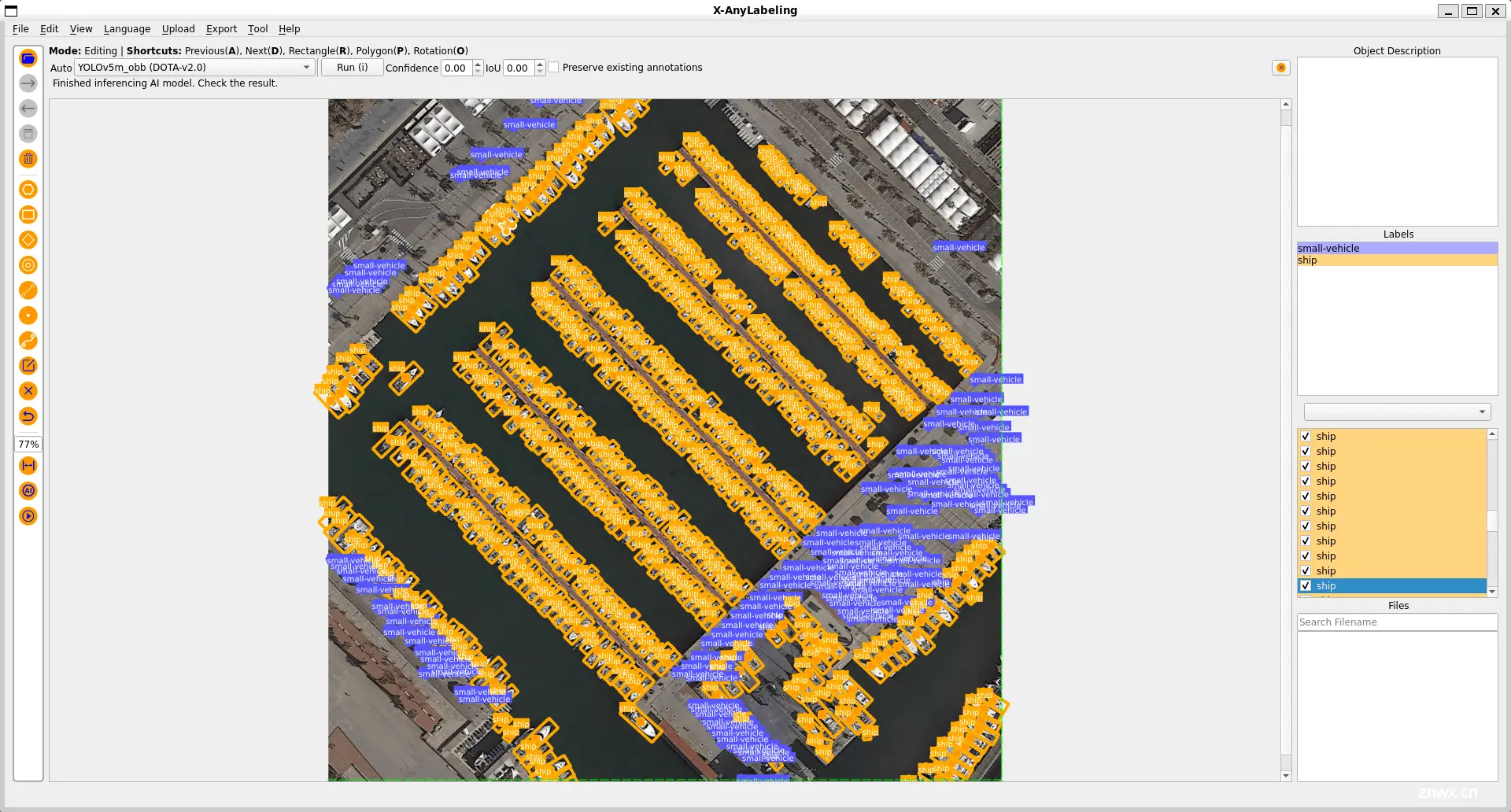
同时也支持旋转框的标定,并包括 yolov5_obb 和 yolov8_obb 等旋转目标检测模型,以更好的适配旋转目标检测任务。

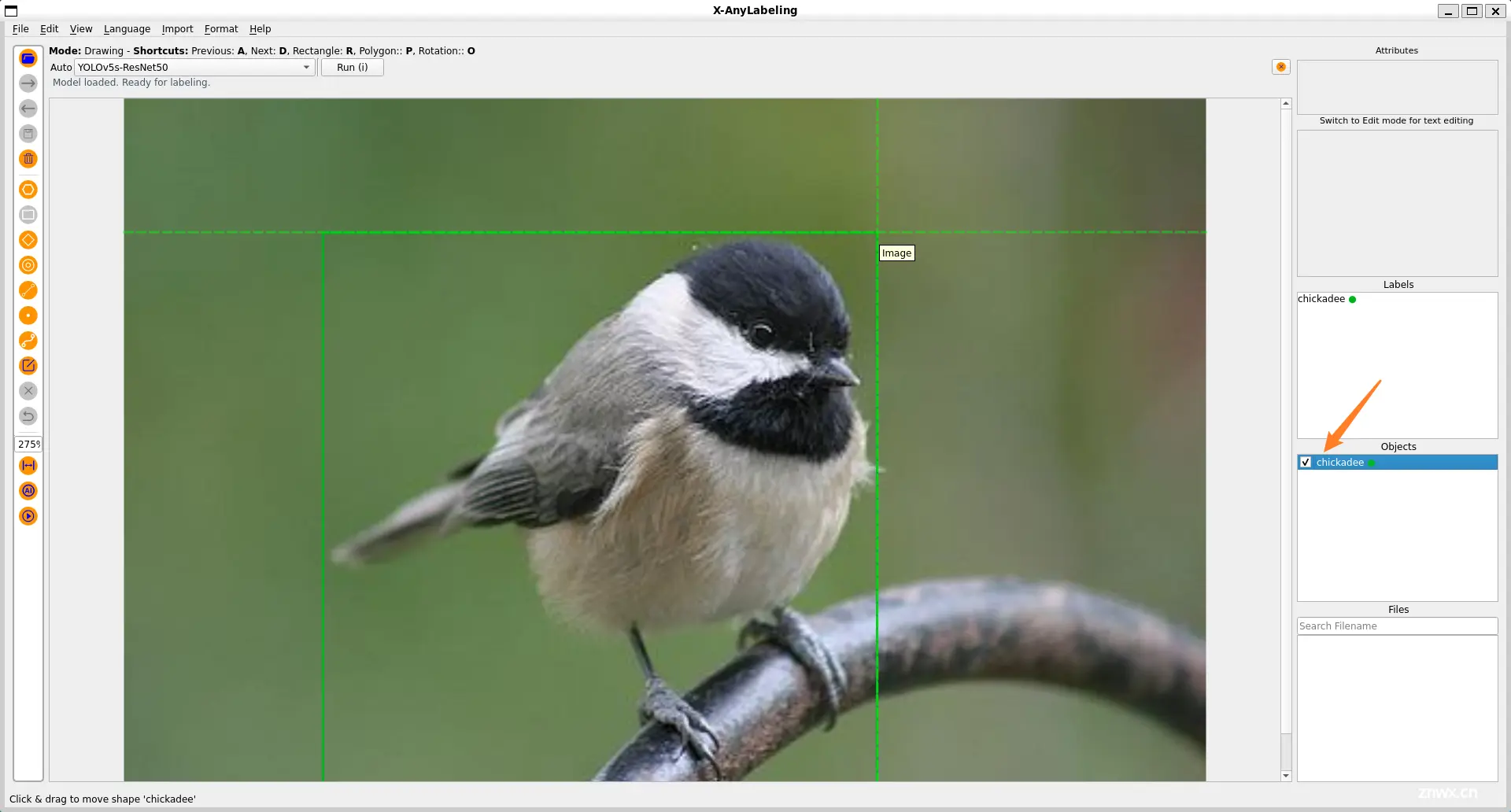
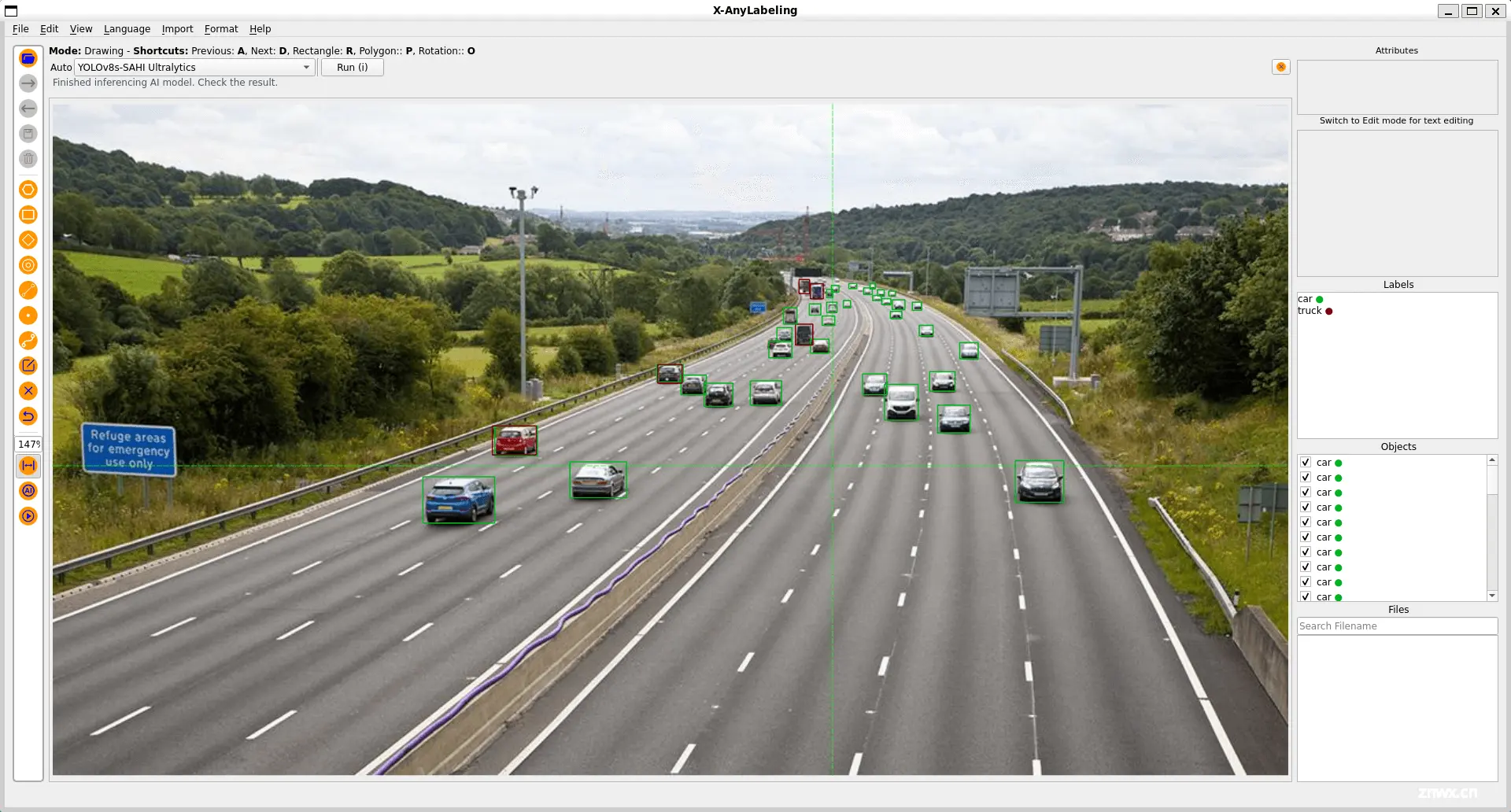
此外,针对小目标场景,X-AnyLabeling 中还集成了 SAHI 工具,支持切片推理,可有效提升小目标场景的检测召回率,如上图所示。

特别地,X-AnyLabeling 还适配了 Grounding-DINO 模型,可支持通过文本提示输入检测一切。Grounding DINO 是一个非常出色的零样本目标检测模型,它是通过将基于 Transformer 的 DINO 检测器与基于 grounded 的预训练相结合而构建的。
详情可参考以下教程:
HBB: https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/detection/hbb/README.md
OBB: https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/detection/obb/README.md
图像分割

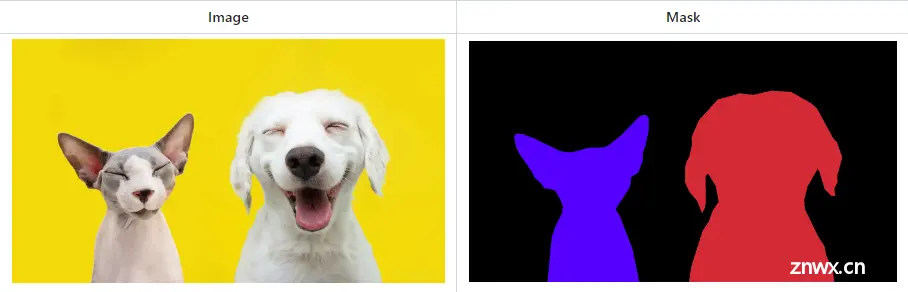
图像分割,作为计算机视觉领域三大经典任务之一,承担着为图像中的每个像素分配标签的重任,确保具有相同标签的像素展现出共同的特征。这一领域主要分为以下三种类型:
语义分割(Semantic Segmentation):在这种分割方式中,每个像素都被分配一个类别标签,但不区分不同的实例。例如,在一张街道图片中,所有的人像素可能都被标记为“人”,而不区分个体。实例分割(Instance Segmentation):实例分割不仅对每个像素进行分类,还区分同一类别中的不同实例。在同样的街道图片中,不同的行人会被分配不同的颜色或标签,以区分彼此。全景分割(Panoptic Segmentation):全景分割结合了语义分割和实例分割的特点,旨在为图像中的每个像素分配一个标签,同时区分不同的实例和背景。这种方法能够提供一个全面的场景理解,包括对单个物体的识别和整个场景的描述。
在 X-AnyLabeling 中,你可以使用内置的 yolov5-seg、yolov8-seg 或者是自定义的语义分割模型如 U-Net 等轻松完成以上任务的标定。

此外,我们还额外提供了包括 SAM2\SAM\EdgeSAM\MobileSAM\HQ-SAM\Efficifientvit-SAM 在内的基于 Segment-Anything 系列的模型支持,并配备了多种不同的型号,以便用户能够根据自己的具体需求、设备性能和场景应用来选择最合适的模型。

更进一步地,针对医学图像场景,X-AnyLabeling中同样提供了多种基于 SAM 微调的高精度模型,包括:
SAM-Med2D: 通用医疗图像分割一切模型;LVM-Med ISIC SAM:皮肤病灶分割一切模型;LVM-Med BUID SAM:超声乳腺癌分割一切模型;LVM-Med Kvasir SAM:结直肠息肉分割一切模型;

详情可参考以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/segmentation/README.md
关键点检测
关键点检测,旨在识别图像中特定点的位置,这些点被称为关键点。这些关键点通常代表了对象的特定部分,如人体的关节、物体的地标或其它显著的特征点。通过检测这些关键点,可以更好地理解图像中对象的姿态、形状和结构。
关键点检测部分主要包括人脸关键点回归(Facial Landmark Detection)和全身人体姿态估计(Pose Estimation)两个关键领域。在这方面,FLD 的一期规划已经植入了美团的 YOLOv6lite-face 模型。

此外,对于全身人体姿态估计任务,X-AnyLabeling 中内置了包括 yolov8-pose、yolox-dwpose 以及 rtmo-dwpose 在内的三款主流姿态估计模型供用户选择。
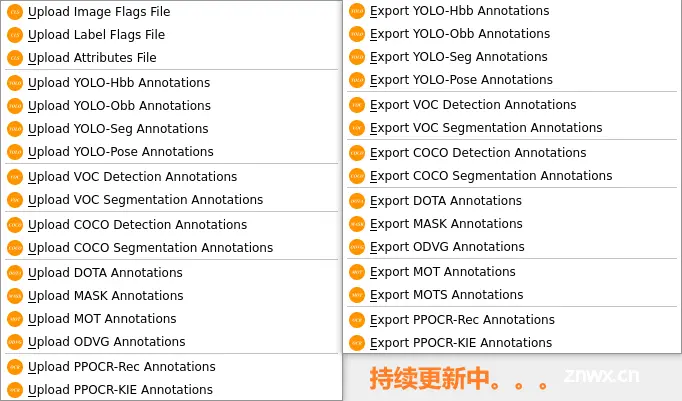
详情可参考以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/estimation/pose_estimation/README.md
多目标跟踪
多目标跟踪(MOT)技术用于在视频序列中同时识别和跟踪多个目标,涉及在不同帧之间关联目标。在X-AnyLabeling 中,我们提供了基于 ByteTrack 和 BotSort 的目标跟踪器,同时支持以下四大任务的跟踪。

详情可参考以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/multiple_object_tracking/README.md
深度估计
深度估计是一项关键的技术,其目的是预测图像中每个像素的深度信息,也就是确定从相机到场景中每个点的距离。这项技术的应用至关重要,它有助于我们理解场景的三维结构,并且在增强现实(AR)、机器人导航以及自动驾驶汽车等众多领域中发挥着重要作用。通过准确的深度估计,系统能够更好地与三维世界互动,从而提高任务的执行效率和安全性。
在X-AnyLabeling平台中,包含了深度估计的功能,目前提供了以下两大模型:
Depth-Anything V1 是一种非常实用的解决方案,用于稳健的单目深度估计,它通过在150万张带标签的图像和6200万张以上无标签的图像上进行训练而实现。Depth-Anything V2 在细粒度细节和鲁棒性方面显著优于其前身V1。与基于SD(可能指StyleGAN或类似架构)的模型相比,V2具有更快的推理速度、更少的参数数量以及更高的深度估计精度。
这些模型能够通过单张图片预测出场景的深度图,详情和使用指南可以通过以下链接查看:
https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/estimation/depth_estimation/README.md
图像标记
图像分析可以返回图像中出现的数千个可识别物体、生物、风景和动作的内容标签。标记不仅限于主要主题(例如前景中的人),还包括设置(室内或室外)、家具、工具、植物、动物、配件、小工具等。标签不是按分类组织起来的,也没有继承层次结构。
其中,以 Recognize Anything, RAM 为代表,这是专用于图像标记的识别一切模型。与 SAM 类似,作为基础模型,它具备卓越的识别能力,在准确性和识别种类方面均超越了 BLIP 等当前领先的模型。特别地,在最新版本的 X-AnyLabeling 中,我们还额外引入了 RAM++ 模型,相比于 RAM 模型,它能够提供更加出众的图标标记能力。
详情可参考以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/description/tagging/README.md
光学字符识别
光学字符识别(Optical Character Recognition, OCR)是一种技术,它通过运用机器学习和模式识别等手段,自动识别图像中的文字并将其转换为可编辑的文本,从而便于后续的处理、搜索和编辑工作。
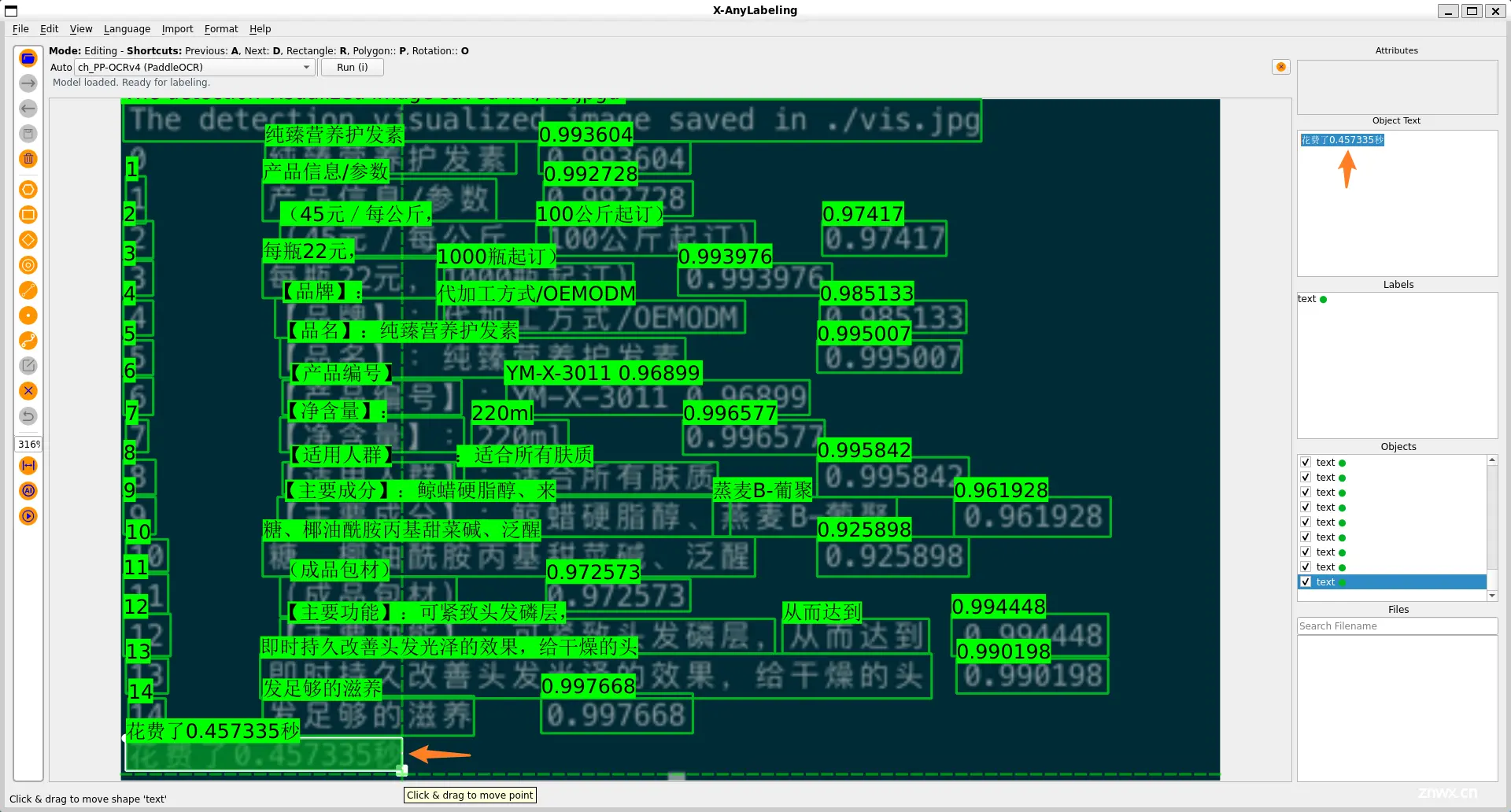
其中,文本标注是众多标注任务中一个非常频繁出现的任务,对于当前的多模态大型语言模型来说,这也是一个极其重要的子任务。然而,遗憾的是,目前市场上主流的标注工具要么不支持这一功能,要么提供的服务不够完善。即便是相对较为接近的 PPOCRLabel,也因为长时间缺乏维护而存在诸多问题。
针对这一痛点,X-AnyLabeling 工具完美地支持了这一新功能。为了提高标注效率,工具内置了基于 PaddlePaddle 最新开源的 PP-OCRv4 轻量化模型,支持中日英等多种语言的文本检测和识别。

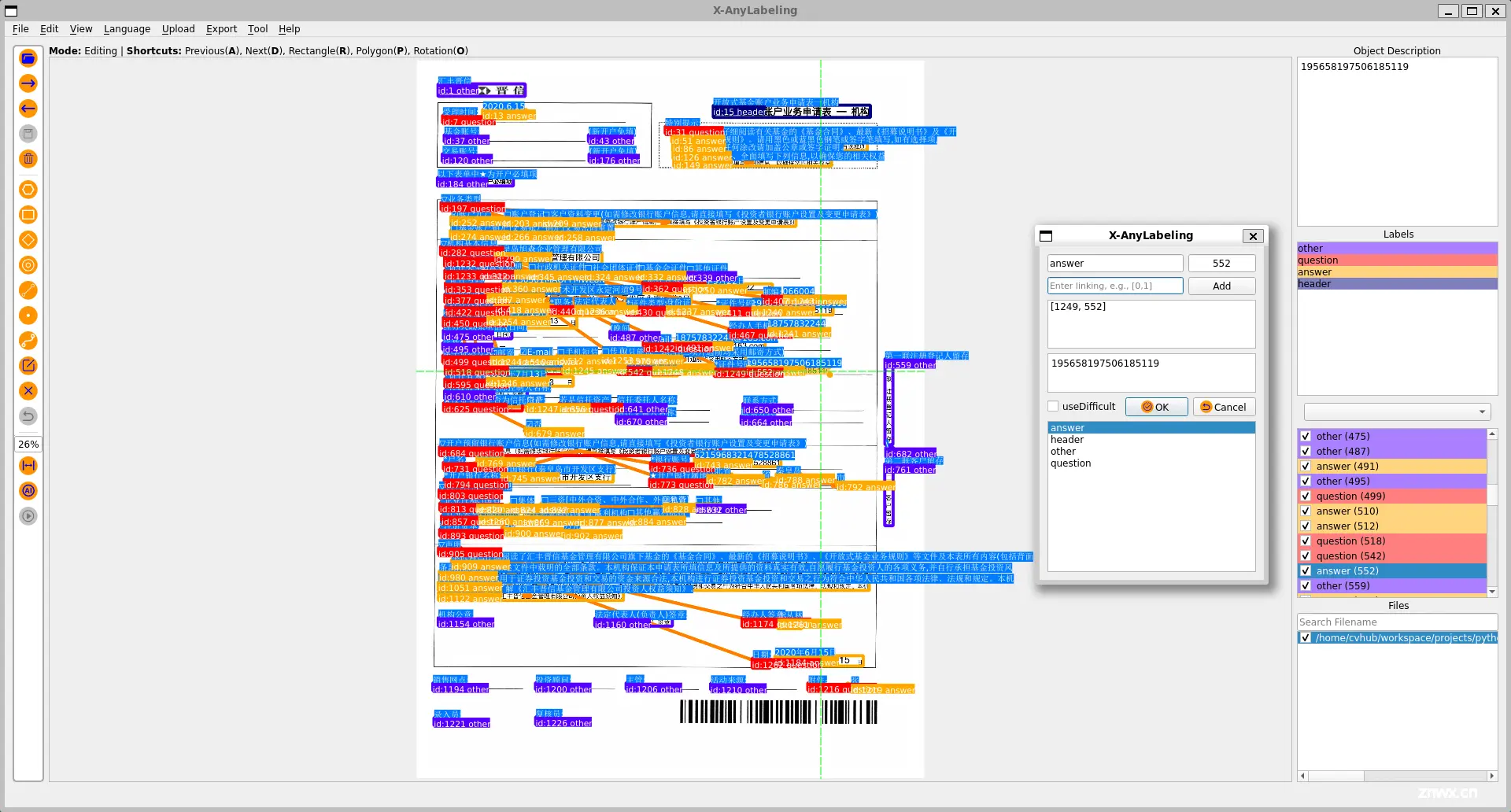
不仅如此,在最新版本中,我们也支持了关键信息提取(Key Information Extraction, KIE),用于从文本或者图像中,抽取出关键的信息。具体地,其包含两个子任务:
语义实体识别(Semantic Entity Recognition, SER):在图像中识别并分类文本。关系抽取(Relation Extraction, RE):对检测到的文本进行分类(例如,区分问题与答案)并识别它们之间的关系,比如将问题与其对应的答案进行匹配。
详情可参考以下链接:
OCR: https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/optical_character_recognition/text_recognition/README.md
KIE: https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/optical_character_recognition/key_information_extraction/README.md
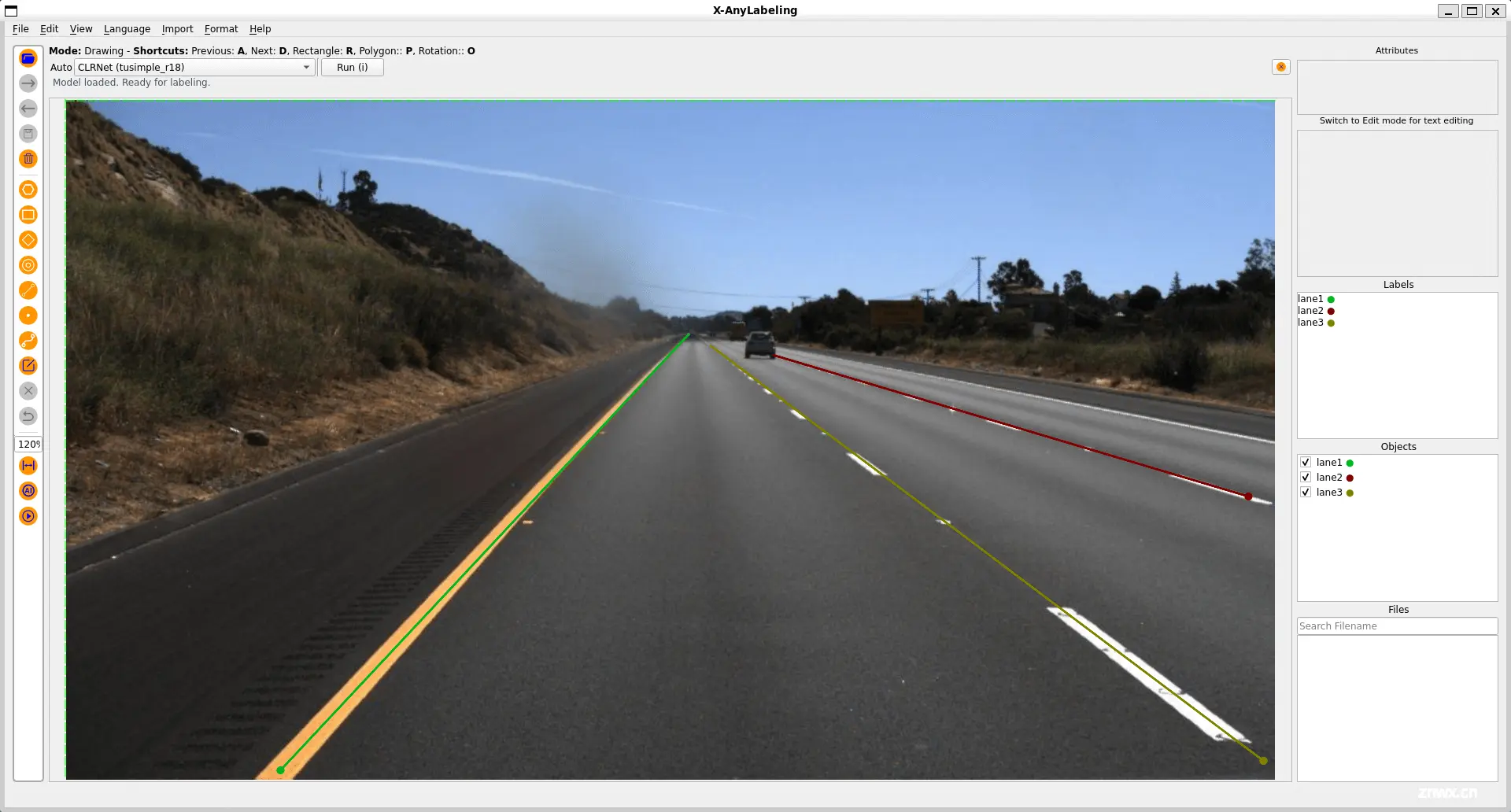
车道线检测
基于Line模式,X-AnyLabeling 中集成了 CLRNet-Tusimple (CVPR 2022) 模型供大家快速体验:
联合视觉任务
如上所述,X-AnyLabeling 中集成了多个领域不同方向的主流算法模型。通过这些内置的深度学习模型,搭配上 X-AnyLabeling 应用中提供的丰富功能组件,我们完全可以构建出更为强大和更有意思的工作流,以解决更为复杂的任务。
下面笔者简单为大家介绍案例,我们也非常鼓励用户根据自己的场景来构建更为有趣且丰富的 Pipeline。
Grounding-DINO + SAM
我们知道,给定一个文本提示和一张图片,Grounding-DINO 可以返回与给定提示最相关的边界框。我们还知道,给定一个边界框提示和一张图片,SAM 可以返回边界框内的分割掩码。
现在,在 X-AnyLabeling 中,你可以很轻松的将这两部分组合在一起,从而实现给定一个基于图像和文本提示来自动完成基于文本提示的分割结果!
SAM + CLIP
众所周知,CLIP 模型能够很好的理解图像和文本之间的关联,而 SAM 则能够根据提示生成精确的分割掩码。通过将两者结合,我们便可以轻松地进行万物检测!
如下所示,用户只需提前在配置文件中添加你需要识别的任意类别名称(支持中英文):
type: sam
name: segment_anything
display_name: Segment Anything
# SAM
encoder_model_path: sam_encoder.onnx
decoder_model_path: sam_decoder.onnx
# Clip
model_type: clip
model_arch: ViT-B-16
...
classes: ["猫", "狗"]
便可以在 X-AnyLabeling 中通过类似于SAM的交互方式轻松高效的完成任意类别的检测与识别!
这种组合极大地简化了交互过程,使得基于提示的检测与分割任务变得更加直观和高效。
YOLO + X
上述我们简单向大家介绍了基于图像级别的分类和标记功能。这里,我们完成可以借助 YOLO 等目标检测器构建二阶段的级联任务,实现对象级别的分类和标记功能,从而提供更细粒度的识别结果!
以检测+分类的级联模型为例,这里可以将原本是鸟的大类别进一步判断为山雀的细粒度类别:

这意味着整个系统不仅能够在整体上描述图像,还能够深入到图像中的各个对象层面,为用户提供更为细致和全面的信息。
同样地,你还可以:
将 SAM 作为 YOLO 等检测器的后处理环节来改善分割细节;将 Detector、OCR和Tracker三者结合起来完成视频字幕的自动生成;…
由于篇幅有限,这里我们就介绍这么多,感兴趣的同学可以亲自上手体验一波。
写在最后
开源之路,虽漫漫而修远,但笔者诚挚邀请各位小伙伴及爱好者携手共进,共同构建这一平台。
最后,如果您觉得这个项目对您有所帮助,不妨给它点一个Star🌟,您的鼓励和支持将是对我们最大的动力。谢谢!_

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。