Neo4j:图数据库的革命性力量
cnblogs 2024-07-14 08:13:00 阅读 88
Neo4j 首席技术官 @prathle 撰写了一篇出色的博文,总结最近围绕 GraphRAG 的热议、我们从一年来帮助用户使用知识图谱 + LLM 构建系统中学到的东西,以及我们认为该领域的发展方向。Neo4j一时间又大火起来,本文将带你快速入门这神奇的数据库。
前言
Neo4j是一款符合ACID标准的图数据库,能处理当今世界中极为复杂的关系数据。由Emil Ifram于2007年创建,使用Java编写,并开创了属性图模型。
传统的关系数据库使用表格模型,但将规范化的表连接在一起并不是人类自然思考关系的方式。我们自然会想到实体之间的连接,比如Bob在Stack Overflow上提出了一个问题,然后Alice和Chad给它点了反对票,所以Bob放弃了他的编程梦想。
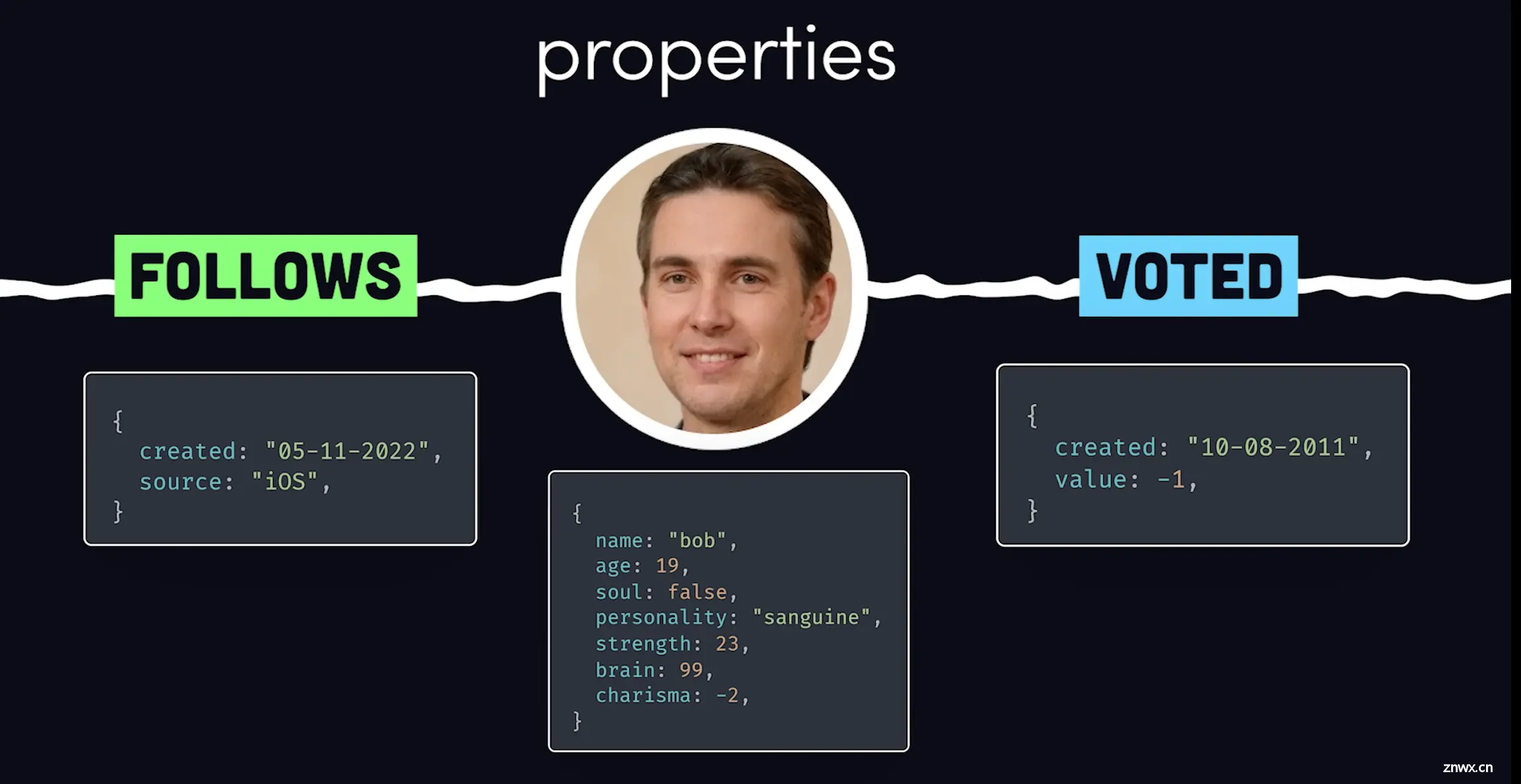
一个图可以像你在白板上可视化它一样建模这些数据。节点代表实体,边表示实体之间的关系,属性是存储在这些对象上的键值对。
在底层,Neo4j是真正的原生图数据库,将这个模型应用到存储层。

查询
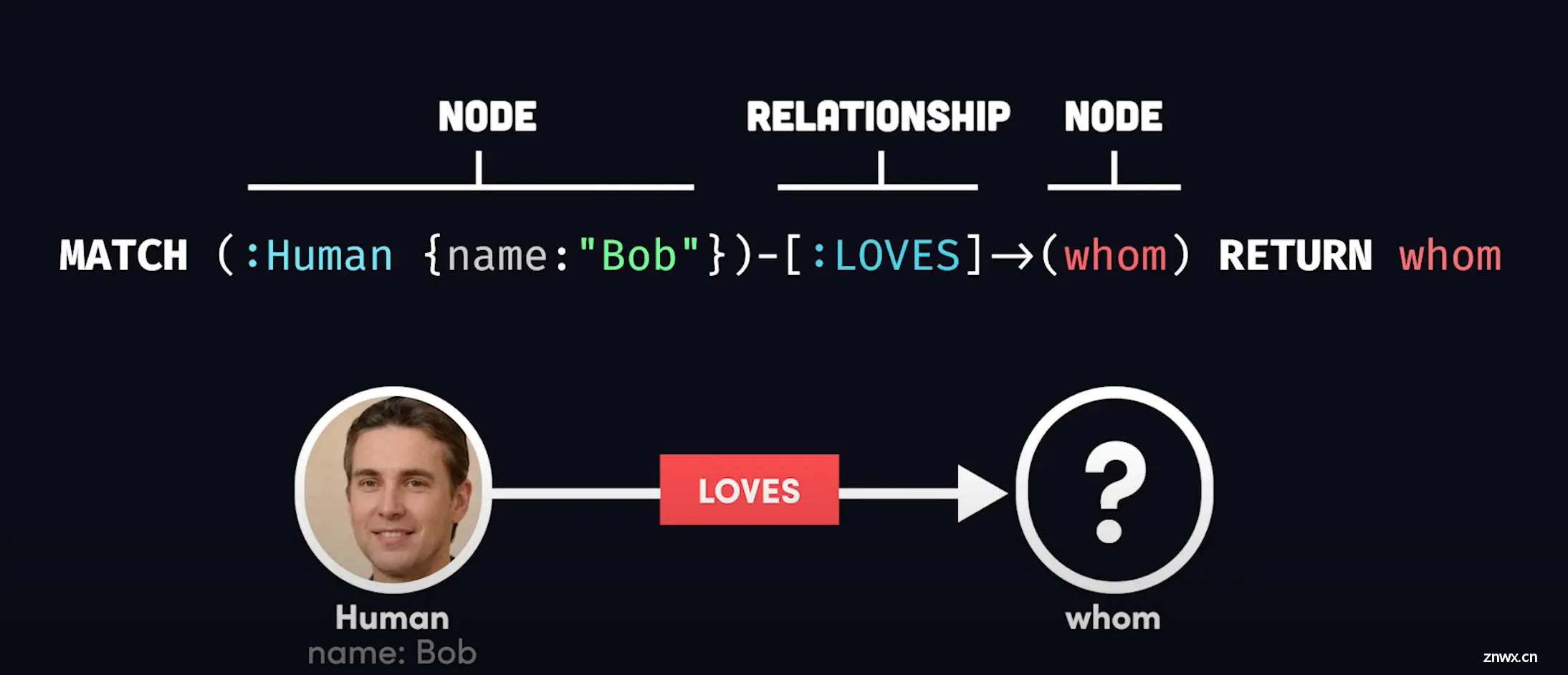
用一种叫Cypher的声明性语言编写,类似SQL,只不过节点用括号括起来,通过箭头连接到其他节点,关系用括号括起来。
要开始使用Neo4j,可以用Docker自托管,但最简单的方法是注册Aura,它提供免费的全托管云数据库。从这里,我们可以用Cypher查询来构建下一个Twitter。
使用CREATE后跟括号来创建一个新的实体或节点,这个节点有一个用户标签,用于将相似的节点分组。在大括号中,我们可以添加键值对来表示该节点上的数据。现在,一个用户可能想要关注另一个用户,这可以用括号内的关系来表示,然后注意箭头指向另一个带有用户标签的节点。创建关系数据就这么简单,不需要外键或连接表,尽管我们可以向模式添加约束,比如这里的约束确保每个用户名都是唯一的。此外,我们可以在这个查询中定义局部变量,然后从语句中返回它们以获取结果数据。特别棒的是,我们可以将其可视化为交互式图形,甚至是表格。
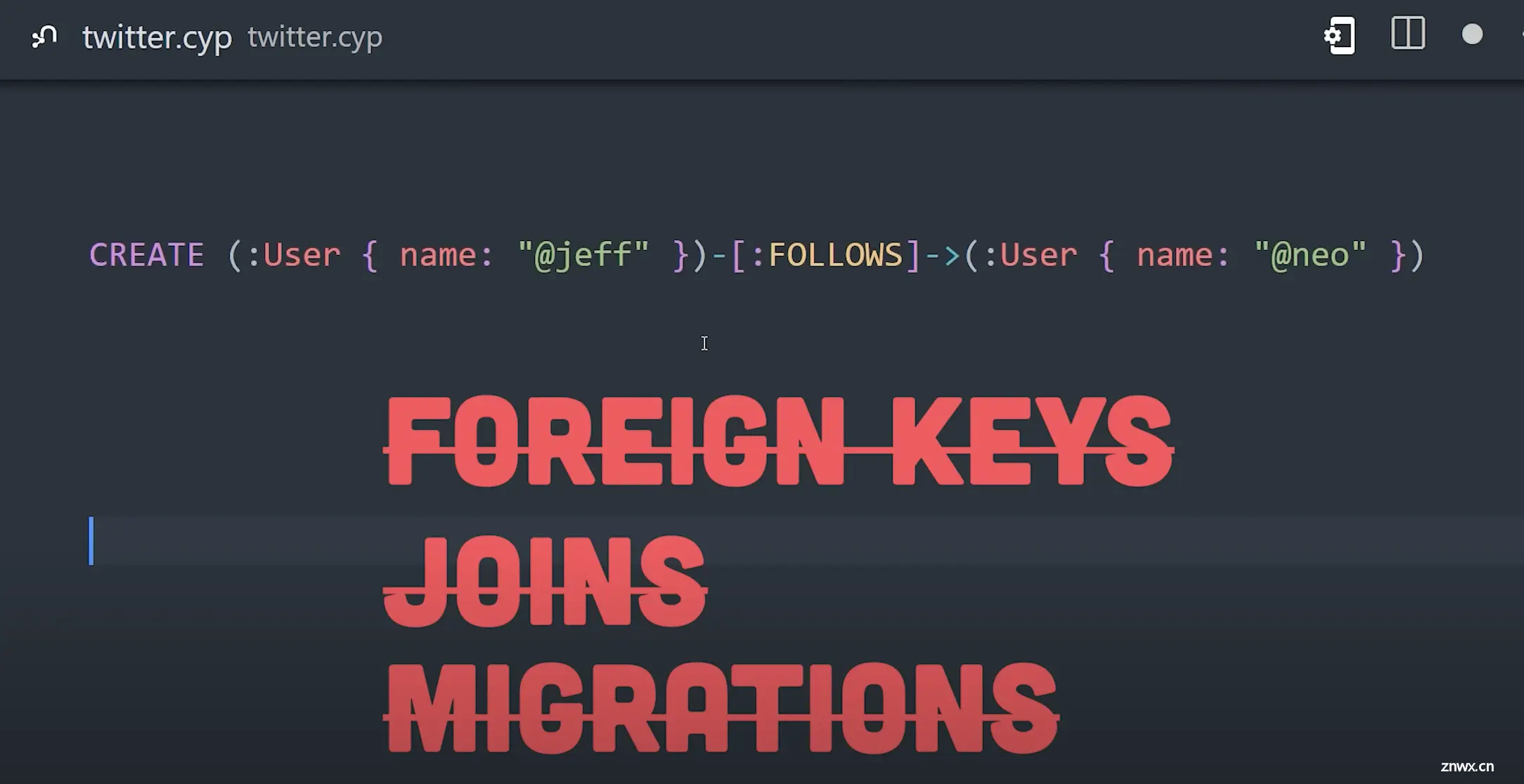
为继续构建Twitter,我们可以将多个推文节点连接到一个用户。我们还需要一个查询来返回所有被关注用户的所有推文,这可以很容易地用节点和关系表示出来,但我们也可以用WHERE子句过滤这个查询,只返回最近发布的推文。此外,我们可以匹配字符串模式和正则表达式,或者基于图形本身过滤复杂模式,比如只返回没有被静音的用户的推文。因此,它不仅对开发人员直观,而且还允许你的数据模式自然地显现出来,这在数据分析和机器学习方面是一个巨大的优势。
核心概念
属性图模型
Neo4j的属性图模型由以下三个主要元素组成:
- 节点(Nodes): 代表实体,如用户、产品或位置。
- 关系(Relationships): 连接节点,表示节点间的关联。
- 属性(Properties): 存储在节点和关系上的键值对,用于描述它们的特征。
这种模型允许我们以一种非常接近人类思维方式的形式来建模数据,使得复杂的关系数据变得直观和易于理解。
标签和类型
- 节点标签: 用于对节点进行分类和分组。例如,<code>:Person或
:Product。 - 关系类型: 描述两个节点之间关系的性质。例如,
:FOLLOWS或:PURCHASED。
Cypher查询语言
Cypher是Neo4j的声明式图形查询语言,设计灵感来自SQL,但针对图数据结构进行了优化。
基本语法
MATCH (n:Person)-[:FOLLOWS]->(m:Person)
WHERE n.name = 'Alice'
RETURN m.name
这个查询匹配所有Alice关注的人,并返回他们的名字。
创建和更新
CREATE (n:Person {name: 'Bob', age: 30})
SET n.job = 'Developer'
这个查询创建一个新的Person节点,并设置其属性。
复杂关系查询
MATCH (a:Person)-[:POSTED]->(t:Tweet)<-[:LIKED]-(b:Person)
WHERE a.name = 'Charlie' AND t.timestamp > timestamp() - 86400000
RETURN b.name, COUNT(t) AS likes
ORDER BY likes DESC
LIMIT 5
这个查询找出过去24小时内点赞Charlie推文最多的5个用户。
性能优化
索引
为了提高查询性能,Neo4j允许在节点属性上创建索引:
CREATE INDEX ON :Person(email)
查询计划
使用EXPLAIN或PROFILE关键字来分析和优化复杂查询的执行计划。
高级特性
全文搜索
Neo4j可以集成全文搜索引擎,如Apache Lucene:
CALL db.index.fulltext.createNodeIndex("tweetContent", ["Tweet"], ["text"])
图算法
Neo4j图数据科学库提供了许多内置的图算法,如PageRank、社区检测等:
CALL gds.pageRank.stream('myGraph')
YIELD nodeId, score
实际应用案例
适用场景
今天,Neo4j被用于推荐引擎(推荐系统: 基于用户行为和项目特征构建个性化推荐)

社交媒体平台:
人工智能的知识图谱,构建和查询复杂的知识网络,支持智能问答系统:

欺诈检测: 通过分析交易网络中的异常模式
技术集成
- Spring Data Neo4j: 为Java开发者提供了简单的Neo4j集成方案。
- Neo4j-GraphQL: 允许开发者使用GraphQL语法来查询Neo4j数据库。
总结
Neo4j作为领先的图数据库,不仅提供强大的数据建模和查询能力,还具有卓越的性能和可扩展性。随数据关系日益复杂,Neo4j在各个领域的应用前景将更加广阔。无论是构建下一代社交网络、优化供应链管理,还是推动AI和机器学习的发展,Neo4j都将扮演重要角色。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM Agent应用开发
- 区块链应用开发
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。