Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具
伪_装 2024-06-24 09:31:09 阅读 93
项目地址:rany2/edge-tts: Use Microsoft Edge's online text-to-speech service from Python WITHOUT needing Microsoft Edge or Windows or an API key (github.com)
Edge-TTS是由微软推出的文本转语音Python库,通过微软Azure Cognitive Services转化文本为自然语音。适合需要语音功能的开发者,GitHub上超3000星。作为国内付费TTS服务的替代品,Edge-TTS支持40多种语言和300种声音,提供优质的语音输出,满足不同开发需求。
1.安装部署
首先,你需要通过Python包管理工具pip来安装Edge-TTS库。只需在命令行中输入以下命令(没有python环境的自行配置一下):
pip install edge-tts
如果只想使用edge-tts和edge-playback命令,最好使用 pipx:
pipx install edge-tts
安装完成后,你就可以开始使用Edge-TTS来将文本转换为语音了。Edge-TTS支持多种语言和不同的声音选项,你可以根据需要选择合适的声音。
2.文本转语音
我们先来个hello world,只需要一行代码!
edge-tts --text "hello world" --write-media hello.mp3
执行完毕之后,会在你执行的目录下,生成hello.mp3文件
如果你想立即播放带有字幕的内容,可以使用以下edge-playback命令:
edge-playback --text "Hello, world!"
注意以上需要安装mpv命令行播放器。所有命令也都edge-tts可以工作。edge-playback
3.支持的语言和音色
edge-tts支持英语、汉语、日语、韩语、法语等40多种语言,共300多种可选声音,执行以下命令查询:
edge-tts --list-voices
如下图所示:
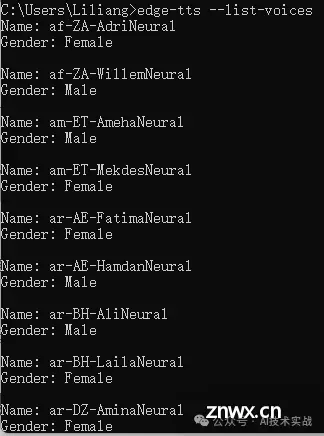
查询结果中的Gender为声音的性别,Name为声音的名字,如zh-CN-YunjianNeural,其中zh表示语言,CN表示国家或地区,可以根据需求选择不同的声音。
使用--voice参数来指定声音名称,下面我使用zh-CN-YunyangNeural声音来合成一个中文音频。
edge-tts --voice zh-CN-YunyangNeural --text "大家好,欢迎关注语音之家,语音之家是一个助理AI语音开发者的社区。" --write-media hello_in_cn.mp3
4.调整语速、音量和音调
可以对生成的语音进行细微修改。
$ edge-tts --rate=-50% --text "Hello, world!" --write-media hello_with_rate_halved.mp3 --write-subtitles hello_with_rate_halved.vtt$ edge-tts --volume=-50% --text "Hello, world!" --write-media hello_with_volume_halved.mp3 --write-subtitles hello_with_volume_halved.vtt$ edge-tts --pitch=-50Hz --text "Hello, world!" --write-media hello_with_pitch_halved.mp3 --write-subtitles hello_with_pitch_halved.vtt
此外,必须使用 --rate=-50% 而不是 --rate -50%(注意等号的缺失),否则 -50% 将被解释为另一个参数。
5.使用代码转换
上面都是用命令转换,我们也可以写代码调用,开发http接口来提供语音合成服务。
以下是一个代码示例,将代码保存到一个文件中,如tts.py。
#!/usr/bin/env python3"""Basic example of edge_tts usage."""import asyncioimport edge_ttsTEXT = "大家好,欢迎关注语音之家,语音之家是一个助理AI语音开发者的社区。"VOICE = "zh-CN-YunyangNeural"OUTPUT_FILE = "d:/test.mp3"async def amain() -> None: """Main function""" communicate = edge_tts.Communicate(TEXT, VOICE) await communicate.save(OUTPUT_FILE)if __name__ == "__main__": loop = asyncio.get_event_loop_policy().get_event_loop() try: loop.run_until_complete(amain()) finally: loop.close()
运行python tts.py,稍等即可在d盘生成合成后的音频test.mp3。
关于 edge-playback 命令的说明
edge-playback 实际上是 edge-tts 的一个封装,用于播放生成的语音。它接受与 edge-tts 选项相同的参数。
上一篇: Spring AI教程(二十三):向量数据库支持与示例项目 | Spring AI教程(二十四):接口设计与Testcontainers支持
下一篇: AI为文档图像安全注入新力量
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。