人工智能和机器学习5 (复旦大学计算机科学与技术实践工作站)语言模型相关的技术和应用、通过OpenAI库,调用千问大模型,并进行反复询问等功能加强
Stitch . 2024-09-08 17:01:01 阅读 71
前言
在这个日新月异的AI时代,自然语言处理(NLP)技术正以前所未有的速度改变着我们的生活方式和工作模式。作为这一领域的佼佼者,OpenAI不仅以其强大的GPT系列模型引领风骚,还通过其开放的API接口,让全球开发者能够轻松接入并探索AI的无限可能。今天,我将带大家一起探索如何使用OpenAI库来调用“千问大模型”(这里假设的模型名,实际中可能是GPT-3、GPT-4或其他类似的高级语言模型),并通过一系列编程技巧实现反复询问、上下文记忆等功能加强,从而构建出更加智能、流畅的对话体验。

一、环境准备
首先,确保你的开发环境已经安装了Python,并配置了必要的库。对于OpenAI的API调用,你需要安装<code>openai库。可以通过pip命令轻松完成安装:
pip install openai
主要讲语言模型相关的技术和应用。
和之前的课不衔接,之前有地方还没理解的同学也可以直接听。大家有安装任意版本python环境即可,提前安装openai包,命令是 pip install openai
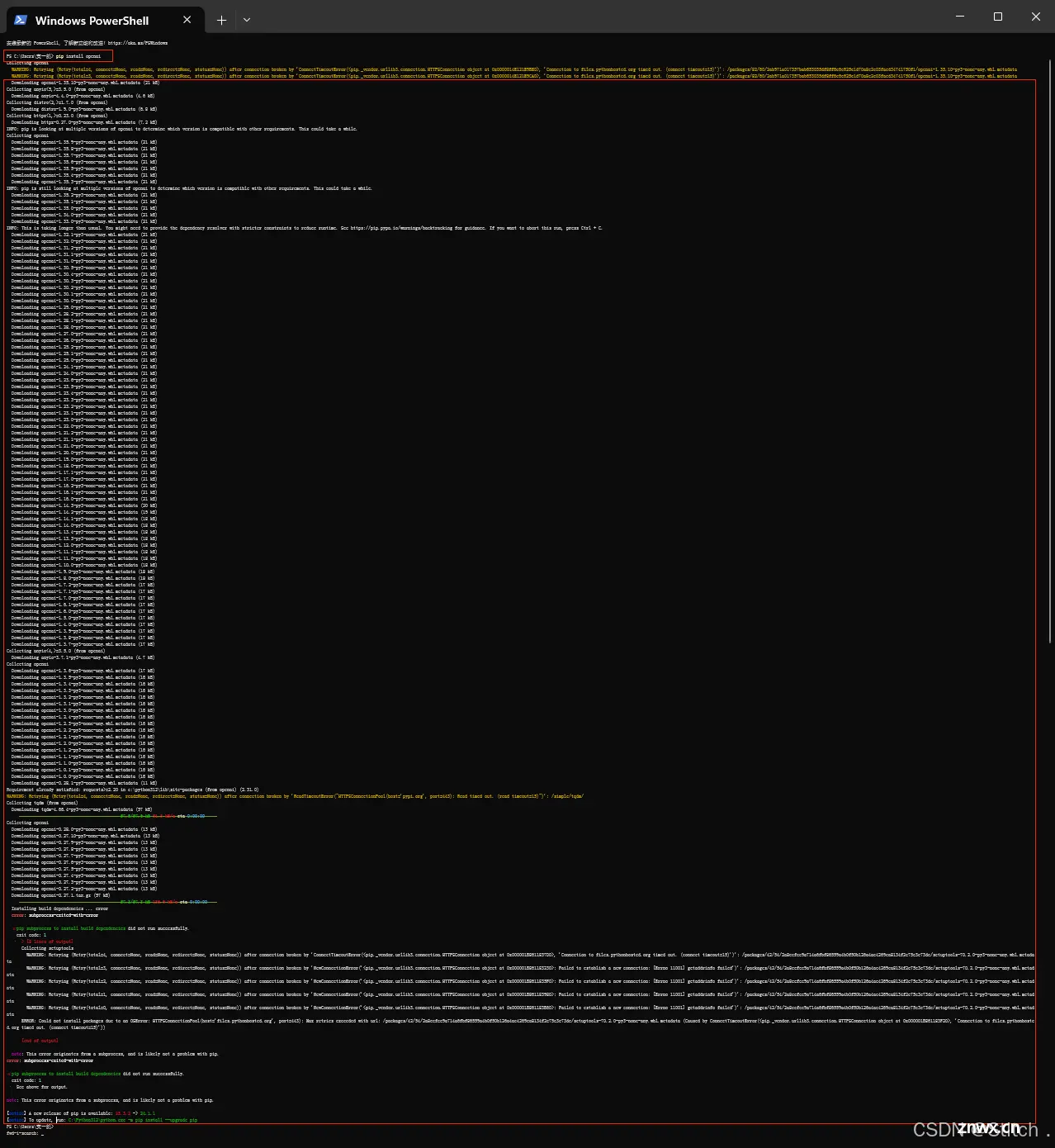
只用这一个包就可以了
另外大家注册下 通义千问:通义 (aliyun.com)

https://tongyi.aliyun.com/qianwen/

和 阿里云 平台:阿里云-计算,为了无法计算的价值 (aliyun.com)
https://www.aliyun.com/并用成年人身份证实名认证阿里云平台。
接下来,你需要在OpenAI的官方网站注册账号,并获取你的API密钥(API Key)。这个密钥将用于你的Python脚本中,以便能够调用OpenAI的API。
不用代理,搜索“通义千问”:(点击如下图会打开通义千问官网,我们不用点击直接搜索)
找到通义千问|模型服务灵积如何定制通义千问模型_模型服务灵积(DashScope)-阿里云帮助中心 (aliyun.com)
https://help.aliyun.com/zh/dashscope/developer-reference/finetune-qwen?spm=5176.21213303.J_qCOwPWspKEuWcmp8qiZNQ.148.2fe62f3dvLEJJc&scm=20140722.S_help@@%E6%96%87%E6%A1%A3@@2399895._.ID_help@@%E6%96%87%E6%A1%A3@@2399895-RL_%E9%80%9A%E4%B9%89%E5%8D%83%E9%97%AE-LOC_llm-OR_ser-V_3-RE_new2@@cardNew-P0_13
点击开发参考,按照教程先去开通DashScope并创建获取API-KEY如何获取通义千问API的KEY_模型服务灵积(DashScope)-阿里云帮助中心 (aliyun.com)
https://help.aliyun.com/zh/dashscope/developer-reference/acquisition-and-configuration-of-api-key?spm=a2c4g.11186623.0.0.270c5796VLjNWG

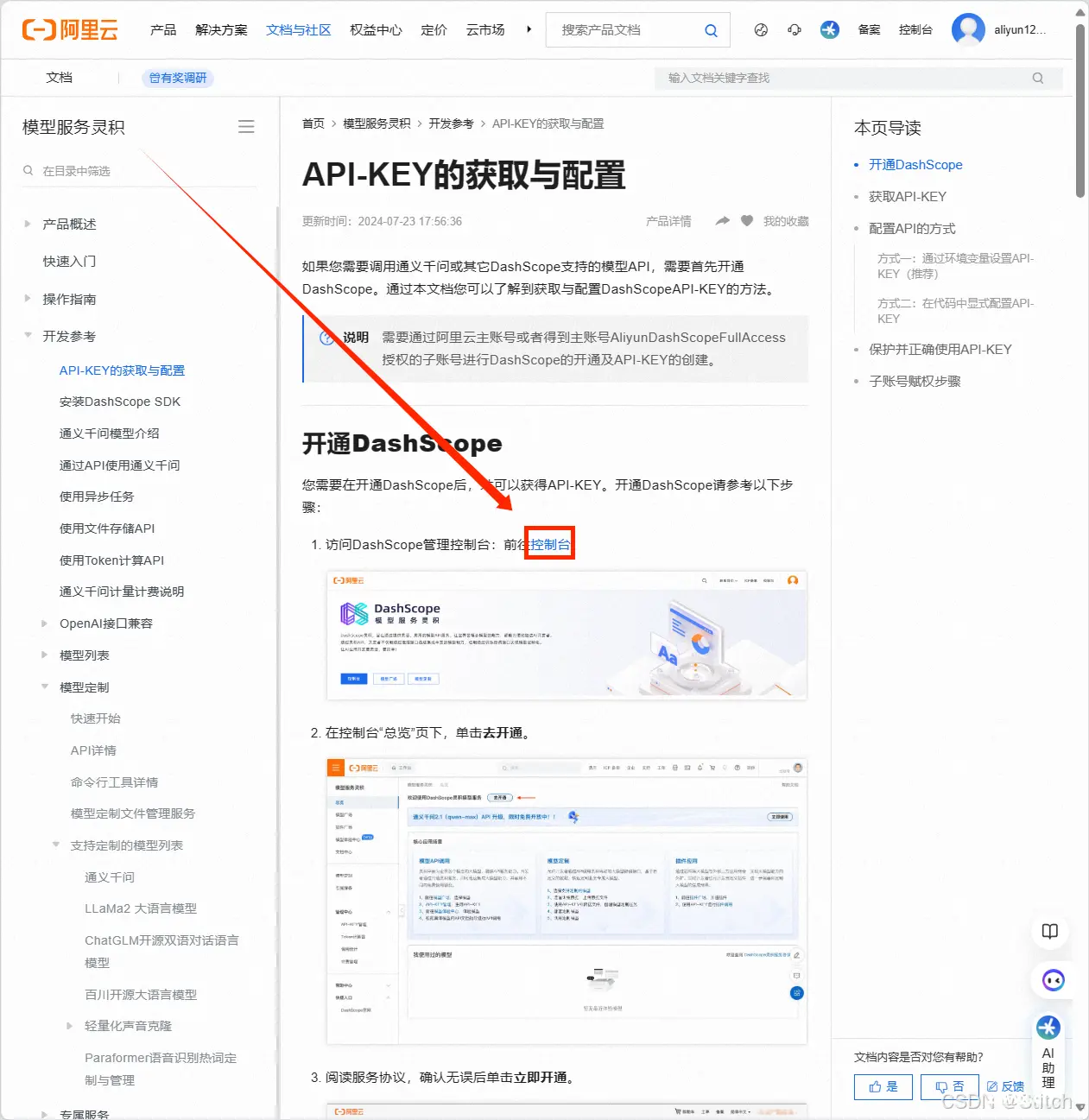
开通DashScope
需要在开通DashScope后,才可以获得API-KEY,开通DashScope请参考以下步骤:
1、访问DashScope管理控制台:前往控制台。
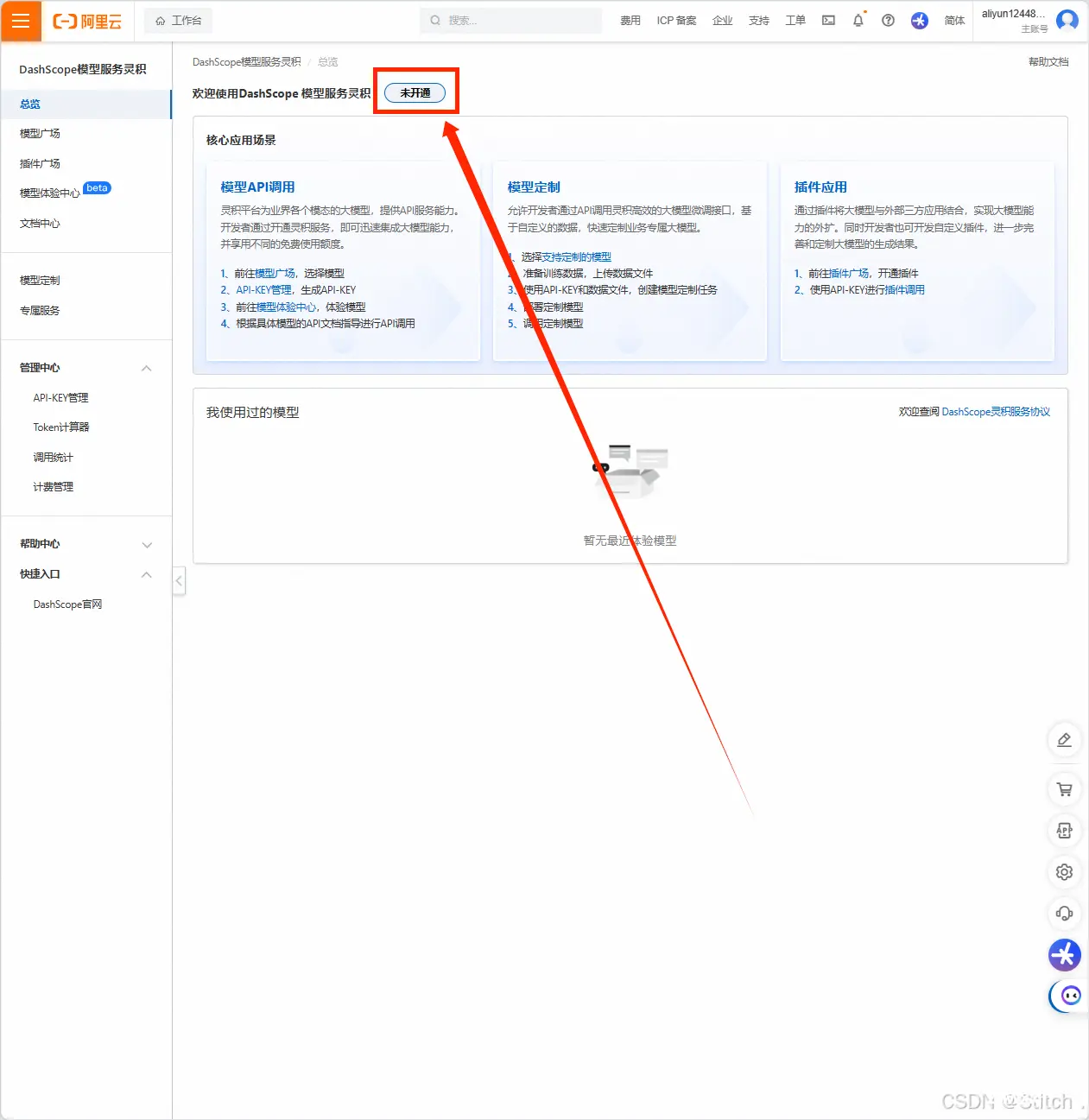
2、点击“未开通”,在控制台“总览”页下,单击去开通。
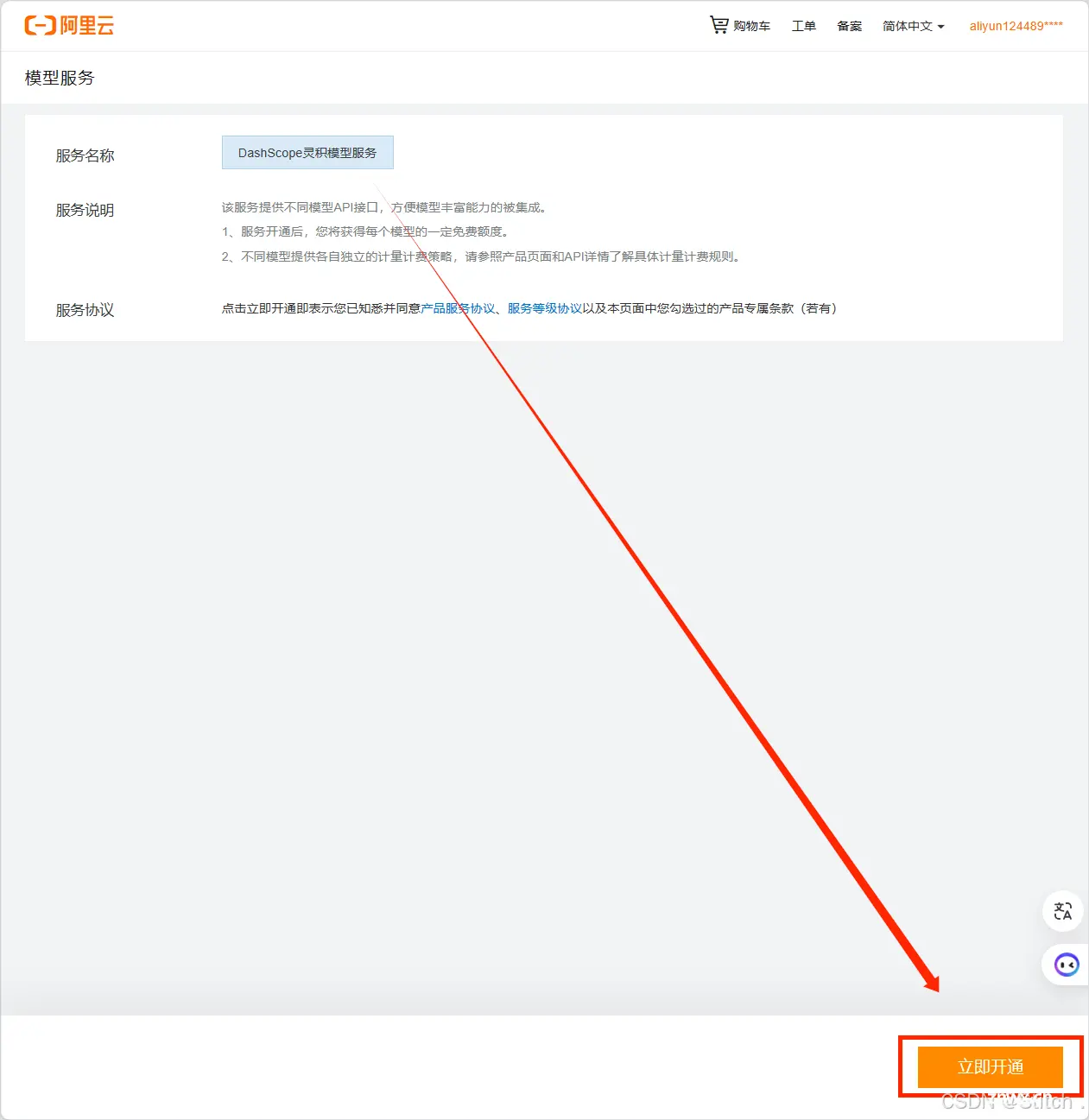
3、阅读服务协议,确认无误后单击立即开通。
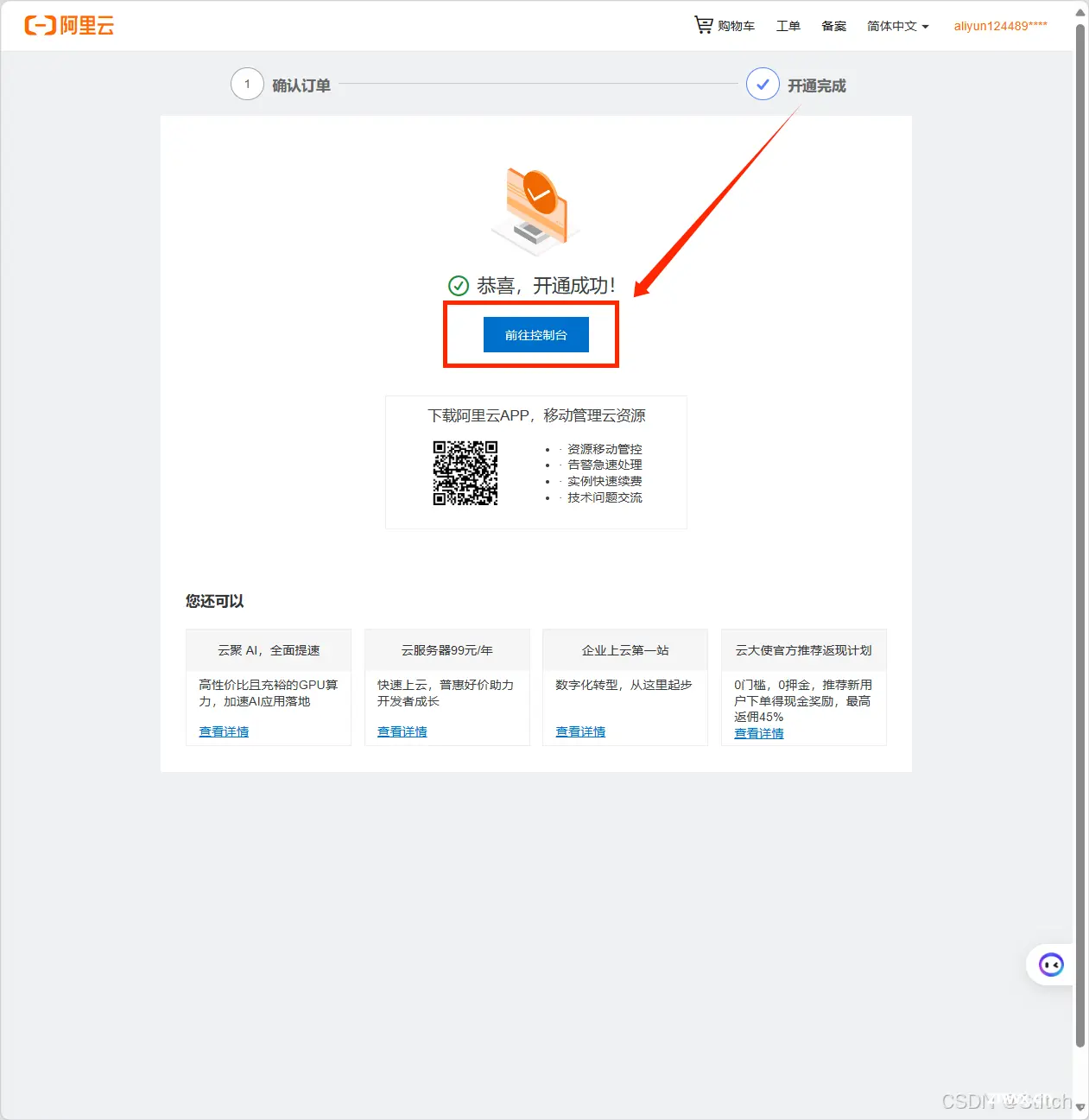
4、开通完成:
获取API-KEY
按照以下步骤获取DashScope的API-KEY。
安全提示:
访问DashScope管理控制台API-KEY管理页面:前往API-KEY管理,单击创建新的API-KEY。
系统创建生成API-KEY,并在弹出的对话框中展示,您可以单击复制按钮将API-KEY的内容复制保存。(sk-xx5d4b8c7a9d42e6a31965f0632fxxxx)实在忘记了,就删了重新建一个吧~
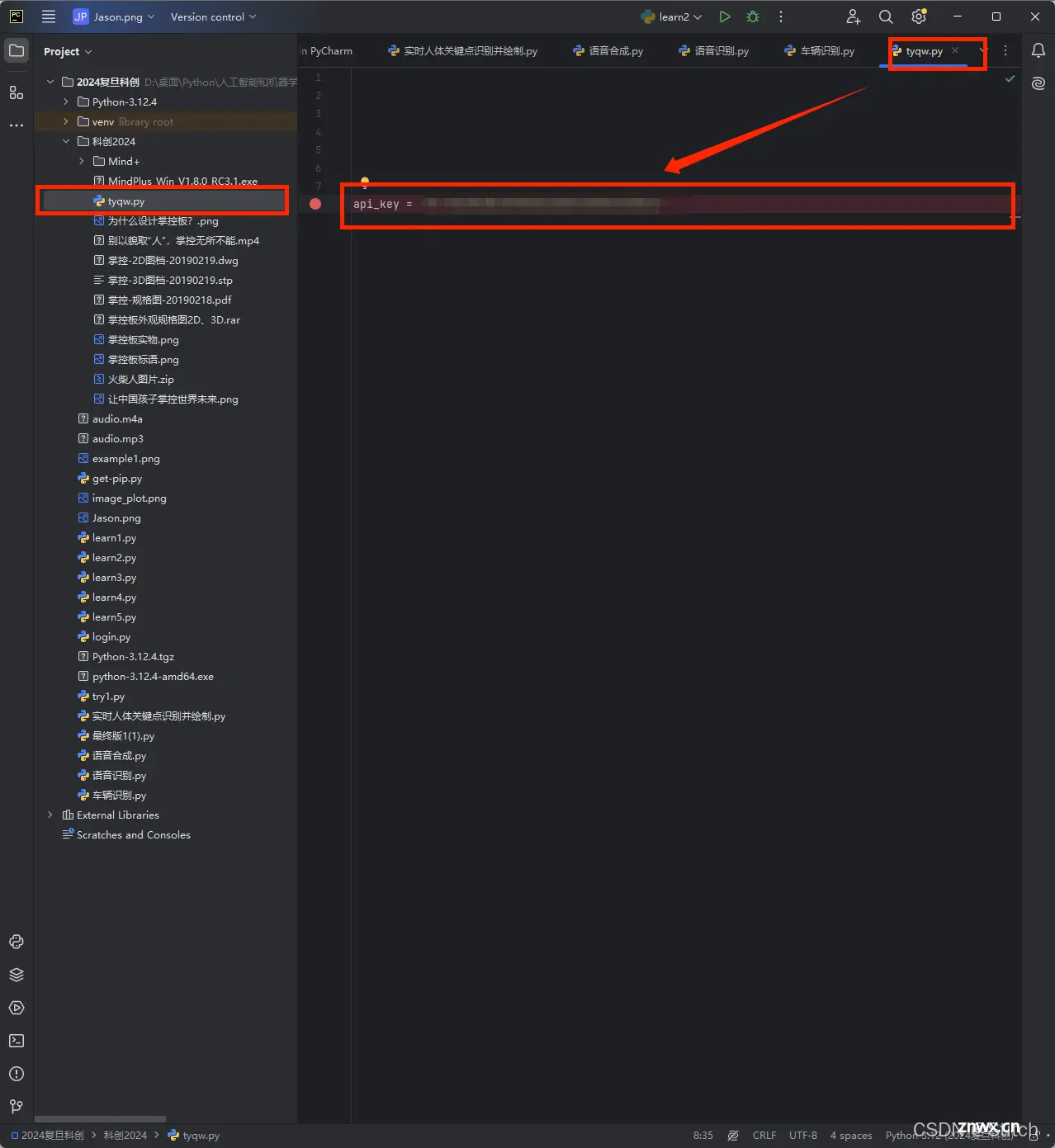
新建一个tyqw.py文件:
把自己的API-KEY输入进去,留着一会备用, (阿里云这个API-KEY既可以当作用户又可以当作密码用)
<code>api_key = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx'
复制并在安全的地方保存API-KEY后,单击我已保存,关闭。此次创建的API-KEY可立即用于调用DashScopeAPI,对API-KEY的后续操作均可在当前的API-KEY管理页面进行。



二、基本调用示例
API platform | OpenAI
https://openai.com/api/在开始之前,让我们先通过一个简单的例子来展示如何使用OpenAI库发送请求到千问大模型:
<code>import openai
# 设置你的API密钥
openai.api_key = "YOUR_API_KEY_HERE"
# 发送请求到模型
response = openai.Completion.create(
engine="text-davinci-003", # 假设使用GPT-3的某个版本,实际应根据千问大模型的名称调整 code>
prompt="请问今天天气如何?", code>
max_tokens=100,
temperature=0.5,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0
)
# 打印模型回复
print(response['choices'][0]['text'])
如何定制通义千问模型_模型服务灵积(DashScope)-阿里云帮助中心 (aliyun.com)
https://help.aliyun.com/zh/dashscope/developer-reference/finetune-qwen?spm=a2c4g.11186623.0.0.75735796iyp8e6通义千问是阿里云自主研发的超大规模语言模型,具备多领域、多任务的自然语言处理能力。它能进行创作(如写故事、公文等)、编写代码、翻译多种语言、文本润色和摘要、角色扮演对话及制作图表等。该模型支持fine-tune,提供多种版本如qwen-turbo、qwen-7b-chat及qwen-72b-chat,以适应不同需求。
在定制模型时,需要准备JSON格式的训练数据,包括用户与助手的对话内容。数据准备支持messages、prompt-completion及human-assistant(已弃用)三种格式。模型训练可通过设置超参数如n_epochs、batch_size和learning_rate来优化。
使用通义千问模型进行定制时,有限制条件如同时只能运行一个定制任务,且最多可创建五个定制任务(不包括失败及取消的)。定制任务的状态包括准备中、运行中、成功、失败和取消。若任务失败,可通过错误码判断原因并寻求解决方案。
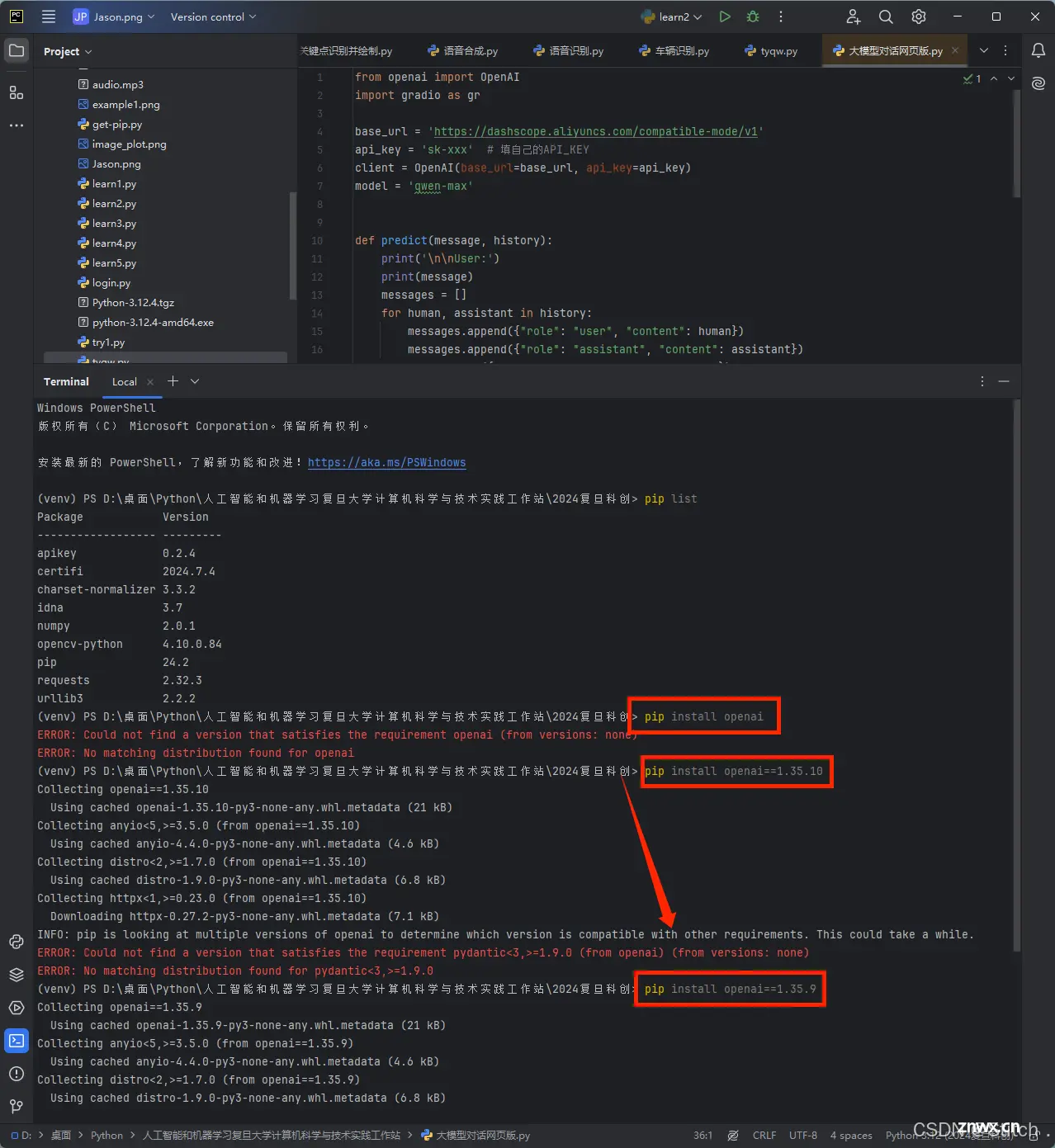
如果之前openai没有按转好的同学可以试着安装特定版本openai1.35.9及以上的版本,找到适合自己的版本安装好就好,
<code>pip install openai==1.35.9
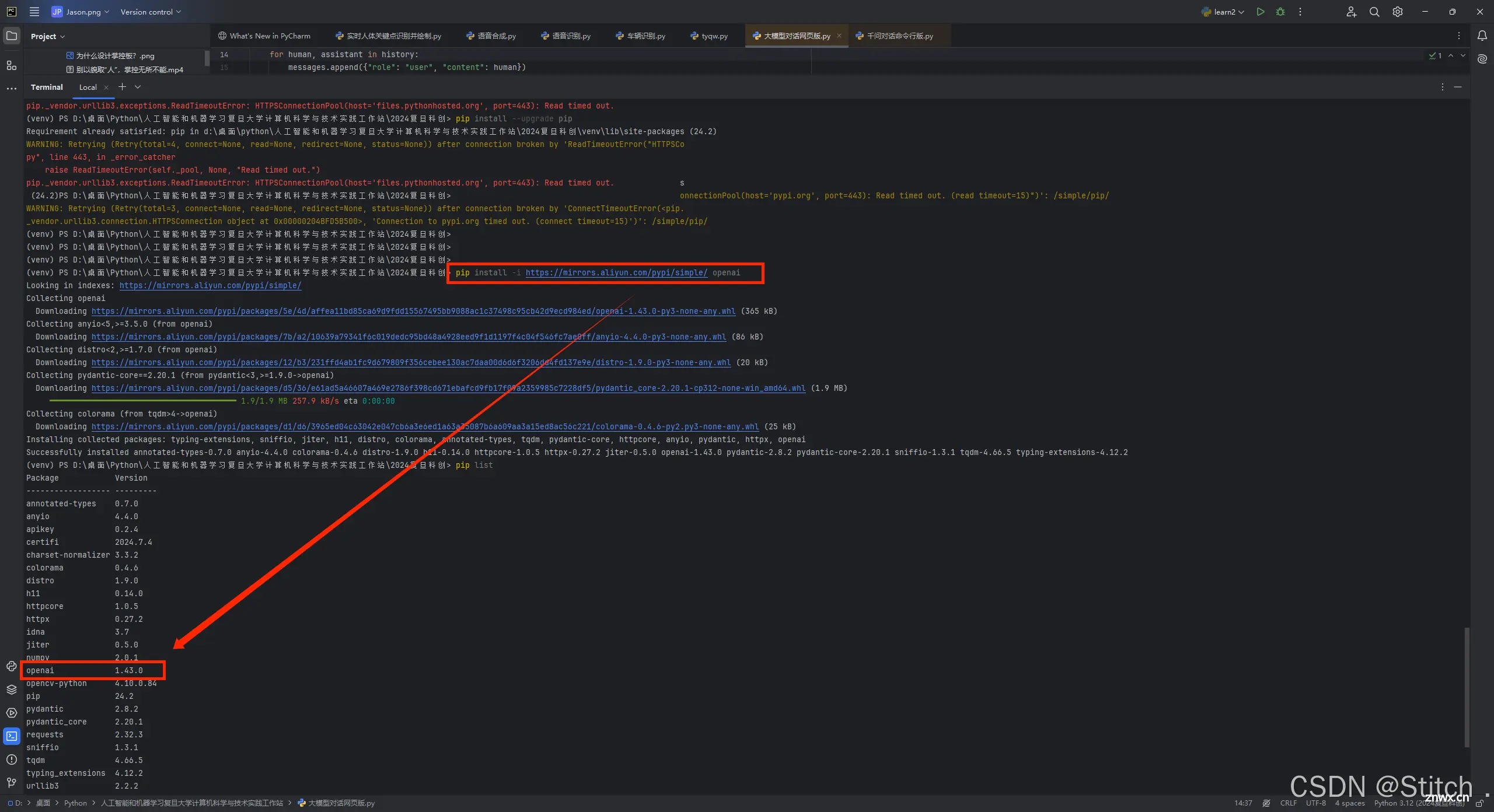
(万能解决办法)更换 PyPI 源:
pip 默认使用 PyPI 的官方源,但你可以配置它使用其他镜像源,这些源可能位于更接近你的地理位置的服务器上,从而提供更好的连接速度。你可以使用国内的镜像源,如阿里云、清华大学、中国科技大学等提供的 PyPI 镜像。使用以下命令来配置 pip 使用特定的镜像源(以阿里云为例):
<code>pip install -i https://mirrors.aliyun.com/pypi/simple/ openai
快速入门 | OpenAI 官方帮助文档中文版 (xiniushu.com)
https://openai.xiniushu.com/docs/quickstart介绍 - OpenAI(ChatGPT) (apifox.cn)
https://openai.apifox.cn/回到阿里云的"模型广场“(开源)———选择第一个<通义千问>点击进去就好了,

三、通义千问模型介绍
通义千问是由阿里云自主研发的大语言模型,用于理解和分析用户输入的自然语言,在不同领域和任务为用户提供服务和帮助。您可以通过提供尽可能清晰详细的指令,来获取符合您预期的结果。
模型体验
您可以在模型体验中心试用通义千问模型,具体操作,请参见模型体验中心。
应用场景
通义千问凭借其强大的语言处理能力,为用户带来高效、智能的语言服务体验,其能力包括但不限于文字创作、翻译服务和对话模拟等,具体应用场景如下:
文字创作:撰写故事、公文、邮件、剧本和诗歌等。
文本处理:润色文本和提取文本摘要等。
编程辅助:编写和优化代码等。
翻译服务:提供各类语言的翻译服务,如英语、日语、法语或西班牙语等。
对话模拟:扮演不同角色进行交互式对话。
数据可视化:图表制作和数据呈现等。通义千问模型是什么_模型服务灵积(DashScope)-阿里云帮助中心 (aliyun.com)
https://help.aliyun.com/zh/dashscope/developer-reference/model-introduction?spm=a2c4g.11186623.0.0.351246c1qCKhJB#BQnl3
四、模型概览
以下是通义千问模型的商业版。相较于开源版,商业版具有最新的能力和改进。
通义千问模型商业版概览
通义千问模型商业版提供了多个针对不同任务复杂度和性能需求的模型选项,包括通义千问-Max、通义千问-Plus和通义千问-Turbo,每个系列均持续优化并引入最新能力。
通义千问-Max
定位:系列中效果最优的模型,专为处理复杂、多步骤的任务设计。版本与快照:提供最新版本及历史快照(如qwen-max-0428、qwen-max-0403等),确保用户可根据需求选择固定版本。性能参数:支持长上下文(如qwen-max-longcontext达30k),高输入输出限制(如最大输入6k,最大输出2k),适合深度交互场景。成本:输入成本为每千Token 0.04元,输出成本为每千Token 0.12元,提供100万Token免费额度(有效期视开通服务而定)。
通义千问-Plus
定位:能力均衡,推理效果和速度介于Max与Turbo之间,适合中等复杂任务。更新亮点:如qwen-plus-0806版本,集中提升了语言一致性、修复了中英文混答问题、减少了回复重复,并显著增强了数学、阅读理解、表格理解和推理能力,同时提升了对系统指令的响应能力。性能参数:高上下文长度(如131072)和输入输出限制(如最大输入128k,最大输出8k),满足广泛需求。成本:输入成本为每千Token 0.004元,输出成本为每千Token 0.012元,同样提供100万Token免费额度。
通义千问-Turbo
定位:系列中速度最快、成本最低的模型,适合处理简单任务。版本与快照:包括最新版本及历史快照(如qwen-turbo-0624),便于用户选择。性能参数:虽然上下文长度和输入输出限制相对较低(如最大输入6k,最大输出1.5k),但足以应对日常简单查询和交互。成本:输入成本为每千Token 0.002元,输出成本为每千Token 0.006元,同样享有100万Token免费额度。
总结:通义千问商业版模型系列覆盖了从简单到复杂的不同任务需求,通过持续的技术更新和性能优化,为用户提供高效、经济的自然语言处理解决方案。用户可根据具体应用场景和预算限制,灵活选择合适的模型版本。
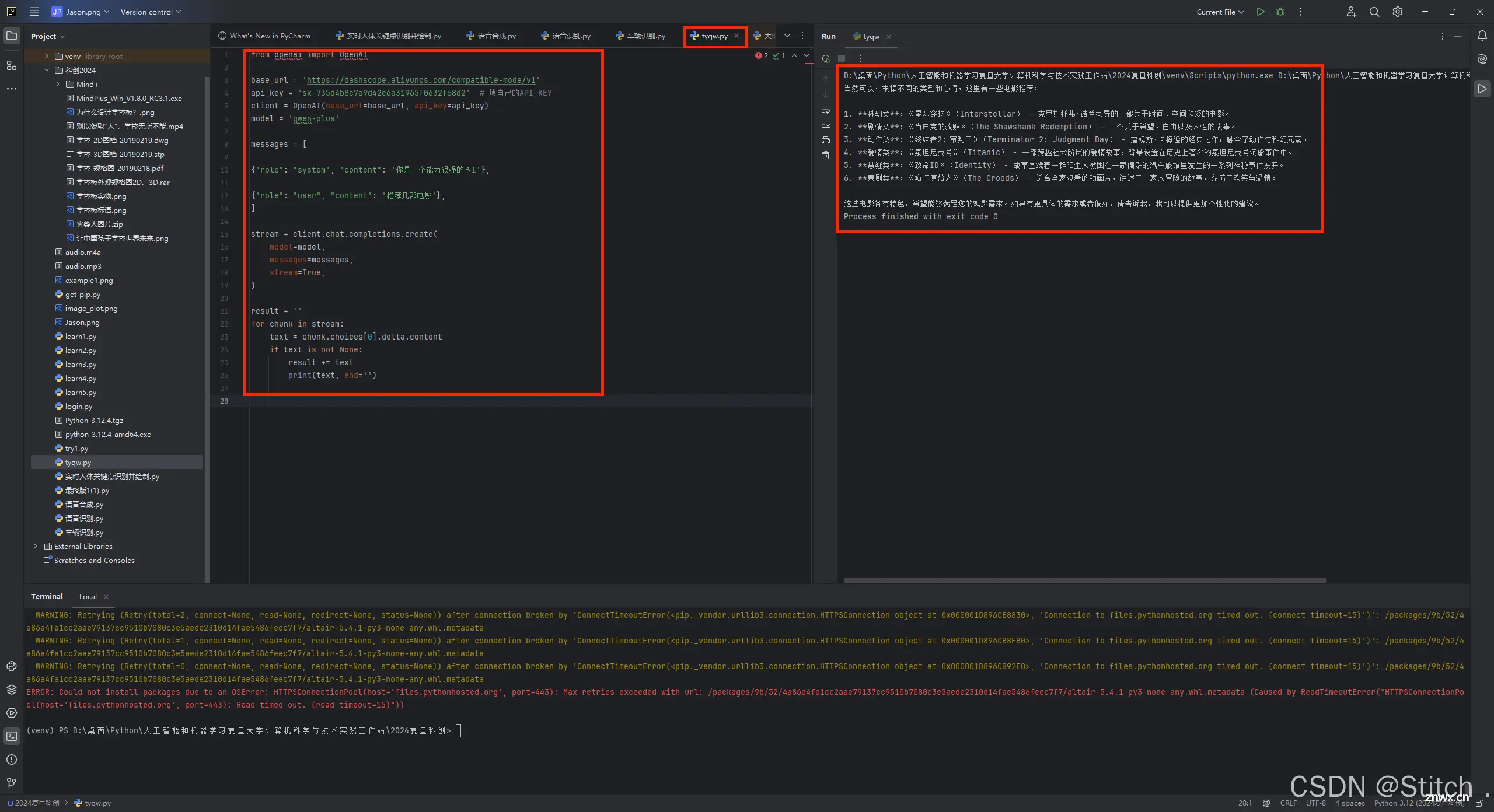
小试牛刀1:
<code>from openai import OpenAI
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
api_key = 'sk-xxxxxxxxxxxxxxxxxxxxxx' # 填自己的API_KEY
client = OpenAI(base_url=base_url, api_key=api_key)
model = 'qwen-plus'
messages = [
{"role": "system", "content": '你是一个能力很强的AI'},
{"role": "user", "content": '推荐几部电影'},
]
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
)
result = ''
for chunk in stream:
text = chunk.choices[0].delta.content
if text is not None:
result += text
print(text, end='')code>
这段代码尝试通过模拟OpenAI的API客户端与一个自定义或第三方服务(通过<code>https://dashscope.aliyuncs.com/compatible-mode/v1这个URL访问)进行交互,以执行聊天机器人风格的文本生成任务。尽管代码中使用了
OpenAI这个类名,但很可能这并不是直接来自OpenAI官方库的类,而是为了适应特定服务而自定义或修改过的。
初始化客户端:代码通过传递一个基础URL和API密钥来创建一个
OpenAI客户端实例。这个基础URL指向了阿里云的一个服务,可能是为了兼容或测试目的而设置的。
设置模型和消息:指定了要使用的模型(
qwen-plus,这很可能是一个自定义或特定于服务的模型)和初始聊天消息(包括一个系统消息和一个用户消息,用户消息请求推荐电影)。
发起聊天请求:使用客户端的
chat.completions.create方法(尽管这个方法路径在OpenAI官方库中可能不同)来发起聊天请求。通过设置stream=True,请求以流式方式接收响应,这允许在生成大量文本时逐步处理结果。
处理响应:代码遍历流式响应,并尝试从每个响应块(
chunk)中提取生成的文本。然而,提取文本的路径(chunk.choices[0].delta.content)是特定于这个服务或API的,并不符合OpenAI官方API的响应格式。对于每个非空的文本块,它都被添加到结果字符串中并打印出来。
总结来说,这段代码是一个使用自定义或第三方服务进行聊天机器人文本生成的示例,尽管它使用了类似OpenAI API的术语和方法名,但实际上是针对特定服务进行适配的。
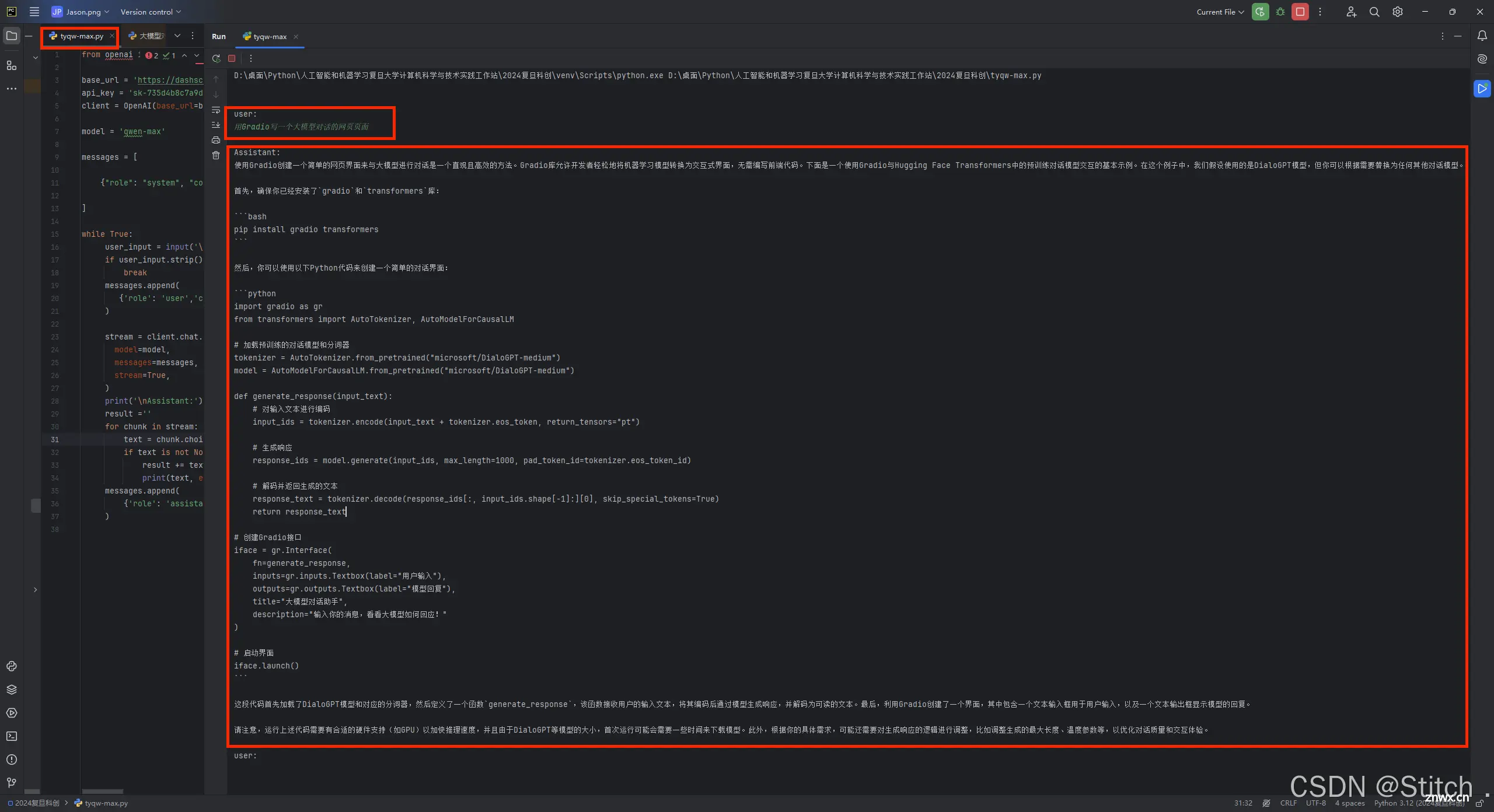
小试牛刀2:
from openai import OpenAI
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
api_key = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxx' # 填自己的API_KEY
client = OpenAI(base_url=base_url, api_key=api_key)
model = 'qwen-max'
messages = [
{"role": "system", "content": '你是一个能力很强的AI'},
]
while True:
user_input = input('\n\nuser: \n')
if user_input.strip().lower()== 'exit':
break
messages.append(
{'role': 'user','content': user_input}
)
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
)
print('\nAssistant:')
result =''
for chunk in stream:
text = chunk.choices[0].delta.content
if text is not None:
result += text
print(text, end='')code>
messages.append(
{'role': 'assistant','content': result}
)
用Gradio写一个大模型对话的网页页面
这段代码试图使用类似OpenAI的API(但实际上通过自定义的<code>base_url和
api_key连接到了一个非OpenAI的服务,这里看起来像是阿里云的一个兼容模式服务dashscope.aliyuncs.com),来创建一个简单的文本聊天机器人。不过,有几个关键点需要注意,因为代码中有一些假设和潜在的错误。
代码简述
导入和初始化:
从假定的
openai库中导入OpenAI类(但通常OpenAI的库是openai,这里可能是自定义的或者是对实际库的误解)。设置自定义的base_url和api_key来连接到非标准的API服务。创建一个OpenAI类的实例client,用于与API服务交互。设置初始对话:
定义了一个
model变量,这里假设为'qwen-max',这看起来像是自定义模型或服务的名称。初始化一个messages列表,包含一个系统消息,告诉AI它的角色和能力。用户输入循环:
使用一个无限循环来不断获取用户输入。如果用户输入
exit(不区分大小写),则退出循环。将用户的输入添加到messages列表中,标记为'user'角色。与AI交互:
使用
client.chat.completions.create方法(这假设是API服务提供的一个方法,用于生成对话的完成)发送当前的对话历史(messages列表)到服务。设置stream=True,这可能意味着服务将以流的形式返回结果,允许逐步处理大型响应。遍历返回的流,提取每个块(chunk)中的第一个选择(choices[0])的增量内容(delta.content),并将其拼接成完整的响应。打印AI的响应,并将该响应作为AI('assistant'角色)的消息添加到messages列表中。
潜在问题和注意事项
库和API的兼容性:代码假设存在一个与OpenAI API相似的
openai库,但实际上使用的是阿里云的服务。这要求该服务确实提供了类似的方法和响应结构。API的响应结构:代码假设每个chunk都有一个choices列表,且列表的第一个元素(choices[0])有一个delta.content属性。这必须与服务实际返回的响应结构相匹配。错误处理:代码中没有错误处理逻辑,如网络错误、API限制、无效的API密钥等。安全性:硬编码的api_key可能带来安全风险,特别是如果代码被公开或泄露。无限循环:除非用户输入exit,否则循环将无限进行,这可能导致资源耗尽或其他问题。API服务的限制:频繁请求API可能会受到速率限制或其他限制,这需要在代码中适当处理。代码的可读性和维护性:使用更具描述性的变量名和注释可以帮助提高代码的可读性和维护性。
五、How to Create a Chatbot with GradioCreating A Chatbot Fast (gradio.app)
https://www.gradio.app/guides/creating-a-chatbot-fast
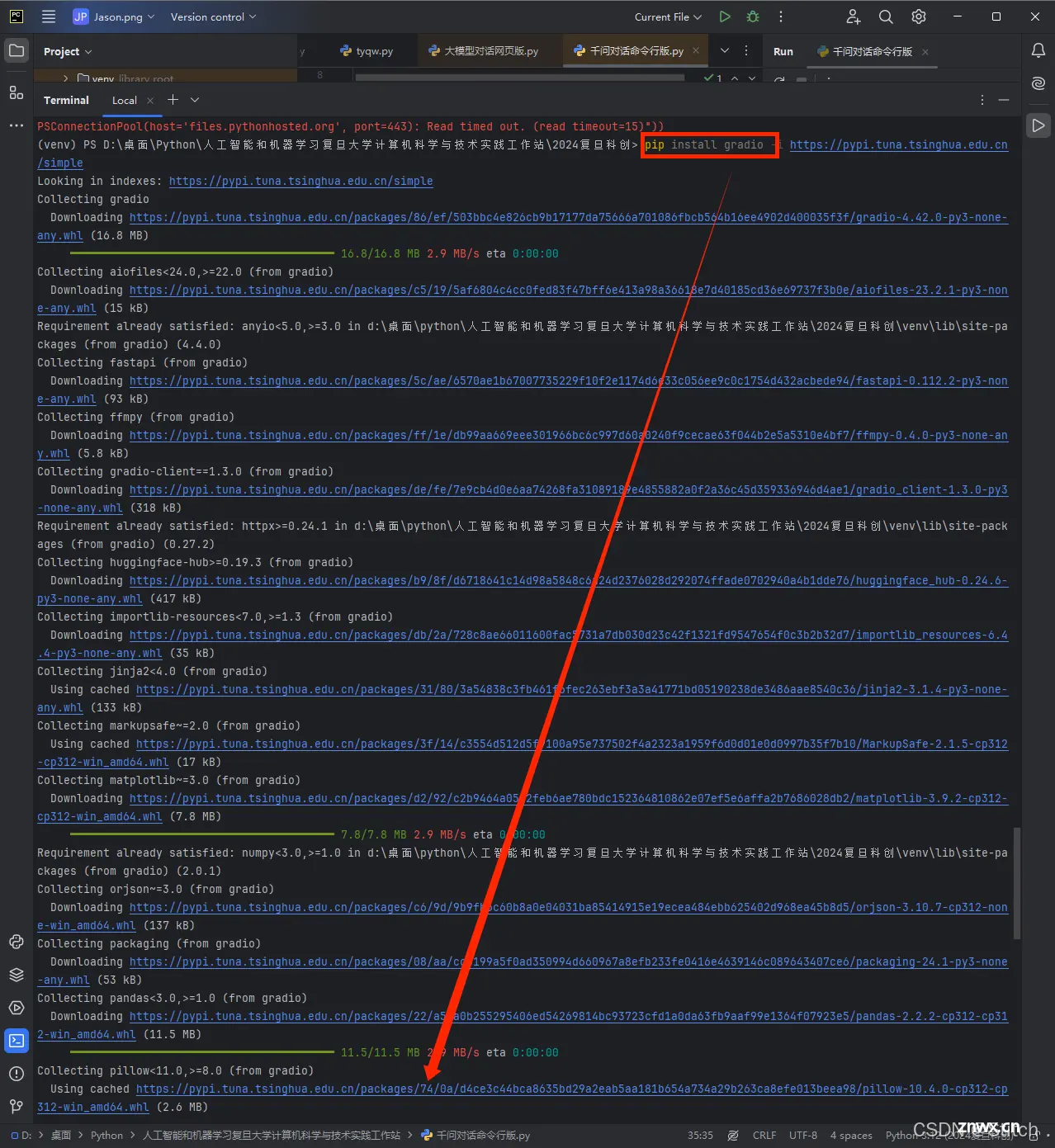
(万能解决办法)使用镜像源:
由于直接访问 PyPI 有时可能很慢或不稳定,你可以尝试使用国内的镜像源来加速包的下载。例如,你可以使用清华大学、阿里云等提供的镜像。
你可以通过修改 pip 的配置文件(pip.conf 或 pip.ini)来设置镜像源,或者使用命令行参数来临时指定镜像源。例如,使用清华大学的 pip 镜像源安装 gradio:
<code>pip install gradio -i https://pypi.tuna.tsinghua.edu.cn/simple
这个命令会告诉 pip 从清华大学的镜像源下载 gradio 包及其依赖。
解释-下CNN的原理,详细点:
举个简单的使用例子(栗子):
千问封装:
写一篇科幻小说
<code>from openai import OpenAI
def qwen(prompt):
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
api_key = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 填自己的API_KEY
model = 'qwen-max'
client = OpenAI(base_url=base_url,api_key=api_key)
messages = [
{"role": "system", "content": '你是一个能力很强的AI'},
{"role": "user", "content": prompt},
]
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
)
result = ''
for chunk in stream:
text = chunk.choices[0].delta.content
if text is not None:
result += text
print(text, end='')code>
return result
if __name__=='__main__':
qwen('写一篇科幻小说')
大模型对话网页版完整代码:
<code>from openai import OpenAI
import gradio as gr
base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1'
api_key = 'sk-xxx' # 填自己的API_KEY
client = OpenAI(base_url=base_url, api_key=api_key)
model = 'qwen-max'
def predict(message, history):
print('\n\nUser:')
print(message)
messages = []
for human, assistant in history:
messages.append({"role": "user", "content": human})
messages.append({"role": "assistant", "content": assistant})
messages.append({"role": "user", "content": message})
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
)
print('\nAssistant:')
result = ''
for chunk in stream:
text = chunk.choices[0].delta.content
if text is not None:
result += text
print(text, end='')code>
yield result
gr.ChatInterface(predict).launch()
这段代码试图结合使用 Gradio 库来创建一个聊天界面,以及一个自定义的
OpenAI客户端(尽管这里的OpenAI类很可能是虚构的或来自一个非官方的库,因为标准的 OpenAI Python SDK 通常不使用OpenAI作为类名,而是使用openai模块),以与某个自定义的聊天模型(在这个例子中是'qwen-max')进行交互。不过,有几个问题和潜在的误解需要澄清。
代码简述
导入和初始化:
导入 Gradio 库和(假设的)
OpenAI类。设置连接到自定义 API 服务的base_url和api_key。创建一个OpenAI类的实例client,用于与 API 交互。定义要使用的模型名称model。定义预测函数:
predict函数接收两个参数:message(当前用户的消息)和history(之前的对话历史,作为(human, assistant)对的列表)。函数内部,首先打印出用户的消息。然后,它创建一个空的messages列表,用于构建发送给 API 的完整对话历史。遍历history,将每对(human, assistant)消息添加到messages列表中,分别标记为'user'和'assistant'角色。将当前用户的消息也添加到messages列表中。使用client.chat.completions.create方法(这假设是 API 提供的一个方法)发送对话历史到服务,并设置stream=True以逐步接收响应。遍历返回的流,拼接 AI 的响应,并实时打印和通过生成器yield返回(但这里的使用方式可能不符合 Gradio 的预期,因为 Gradio 通常期望一个最终的结果,而不是一个生成器)。创建和启动 Gradio 聊天界面:
使用
gr.ChatInterface(predict)创建一个聊天界面,该界面将使用predict函数作为其后端。调用.launch()方法启动聊天界面。
潜在问题和注意事项
OpenAI类的使用:如上所述,这里的OpenAI类很可能是虚构的或来自非标准库。标准的 OpenAI Python SDK 使用的是openai模块,而不是OpenAI类。生成器的使用:在 Gradio 的上下文中,predict函数应该返回一个完整的结果,而不是一个生成器。Gradio 不会自动处理生成器,因此这种方式可能不会按预期工作。API 响应结构:代码假设了 API 响应的特定结构(如chunk.choices[0].delta.content),这必须与 API 实际返回的响应结构相匹配。安全性:硬编码的api_key可能导致安全风险。错误处理:代码中没有错误处理逻辑,如网络错误、API 限制等。API 服务的限制:频繁请求 API 可能会受到速率限制或其他限制。
改进建议
确认
OpenAI类的来源和用法,或改用标准的 OpenAI Python SDK(如果适用)。修改predict函数以返回一个完整的结果字符串,而不是生成器。添加适当的错误处理和日志记录。考虑使用缓存或其他机制来减少对 API 的请求次数。如果 API 支持,考虑使用异步请求来提高性能。



下一篇: AI:243-YOLOv8主干改进涨点 | 集成LSKNet提升遥感目标检测性能的探索与实现
本文标签
人工智能和机器学习5 (复旦大学计算机科学与技术实践工作站)语言模型相关的技术和应用、通过OpenAI库 并进行反复询问等功能加强 调用千问大模型
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。