数据挖掘(2.4)--数据归约和变换
码银 2024-08-01 08:01:01 阅读 89
目录
1.数据归约
1.1数据立方体聚合
1.2特征选择
1.3数据压缩
1.4其他数据归约方法
回归分析
直方图
聚类
简单随机采样(SAS)
2.数据离散化
2.1基于信息增益的离散化
2.2基于卡方检验的离散化
2.3基于自然分区的离散化
3.概念层次生成
1.数据归约
在实际应用中,数据仓库可能存有海量数据,在全部数据上进行复杂的数据分析和挖掘工作所消耗的时间和空间成本巨大,这就催生了对数据进行归约的需求。
数据归约可以从几个方面入手:
如果对数据的每个维度的物理意义很清楚,就可以舍弃某些无用的维度,并使用平均值、汇总和计数等方式来进行聚合表示,这种方式称为数据立方体聚合;如果数据只有有些维度对数据挖掘有益,就可以去除不重要的维度,保留对挖掘有帮助的维度,这种方式称为维度归约;如果数据具有潜在的相关性,那么数据实际的维度可能并不高,可以用变换的方式,用低维的数据对高维数据进行近似的表示,这种方式称为数据压缩;另外一种处理数据相关性的方式是将数据表示为不同的形式来减小数据量,如聚类、回归等,这种方式称为数据块消减。
归约后:

1.1数据立方体聚合
数据立方体是一种数据表示和分析的工具,它将数据表示为多维的矩阵,可以对数据进行聚合运算如计数、求和和求平均值等操作。
1.2特征选择
特征选择在数据预处理和迭代调整的学习中都有较多的使用,目的是对于给定数据挖掘任务,选择效果较好的较小特征集合。
在预处理中,特征选择通常希望能使得在选择出的特征集合下的类别的概率分布能够尽量接近于在全部特征下的类别的概率分布,这是为了权衡空间复杂度、时间复杂度和数据挖掘效果的折中。
在原始的特征有N维的情况下,特征子集的可能情况有2^N种情形
通常使用启发式的特征选择方法如:
前向特征选择是通过选择新的特征添加到特征集合中,使得扩充后的特征集合具有更好的特性。后向特征消减是通过从特征集合中取出最差的特征,使得新的特征集合具有更好的特性。决策树归纳方法进行特征选择是借助决策树构建来选择较小特征集合的方法。
1.3数据压缩
数据压缩是在尽量保存原有数据中信息的基础上,用尽量少的空间表示原有的数据。数据压缩分为有损压缩和无损压缩,
有损压缩后的数据信息量少于原有的数据,因而无法完全恢复成原有的数据,只能以近似的方式恢复。
无损压缩没有这限制,从压缩后的数据可以完全恢复原有数据。无损压缩一般用于字符串的压缩,被广泛应用在文本文件的压缩中。【霍夫曼提出的具有理论意义的Huffman编码,以及广泛使用于gzip,deflate 等软件中的LZW算法】
在图像和音视频压缩中通常使用有损压缩,在图像压缩中常见的离散小波变换就是一种有损压缩,仅仅保存很少一部分较强的小波分量,可以在图像质量无明显下降的情况下获得相当高的压缩率。
主成分分析(PCA)是一种正交线性变换,它将数据通过正交变换到新的坐标系中,其中第一个分量有最大的方差,第二个分量有第二大的方差,依此类推,数据主要的能量集中在前几个分量中。【通常在处理维数较多的数值型数据中进行应用】
1.4其他数据归约方法
参数式方法和非参数式方法
回归分析
回归分析是一种典型的参数式方法,回归分析的一般表达式如下:
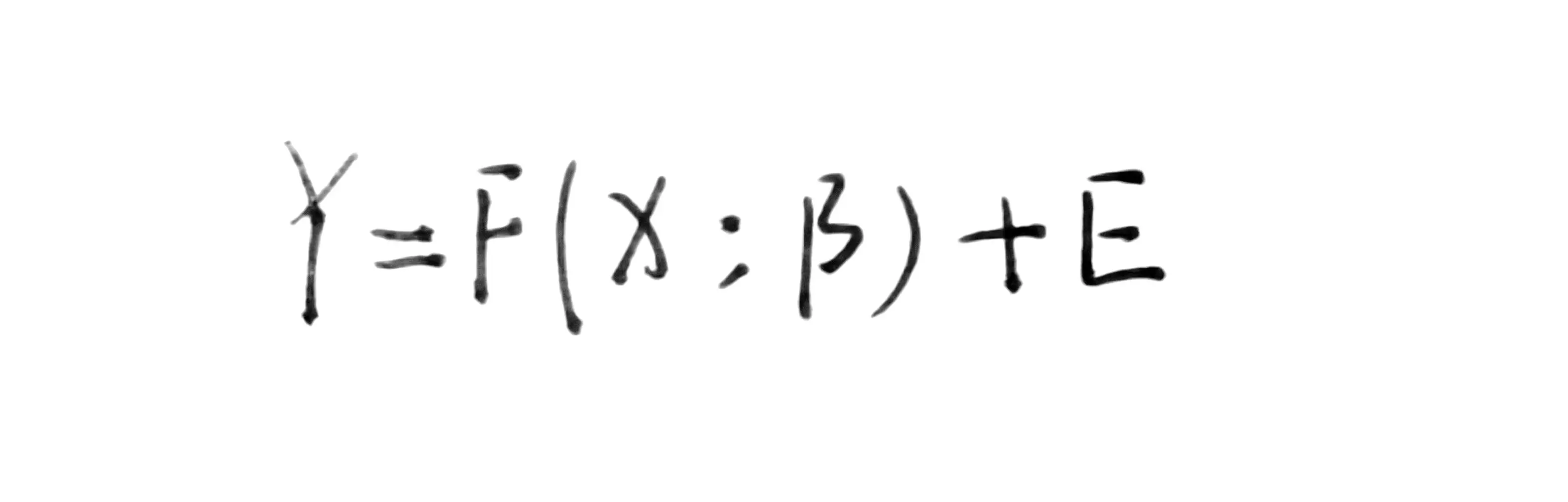
其中,F为模型的表达式,X为自变量,Y为因变量,β为模型的未知参数,E为误差,X、Y、β、E都可以是标量或矢量。回归分析的目的就是在一定条件下估计最好的参数β。根据不同
直方图
聚类
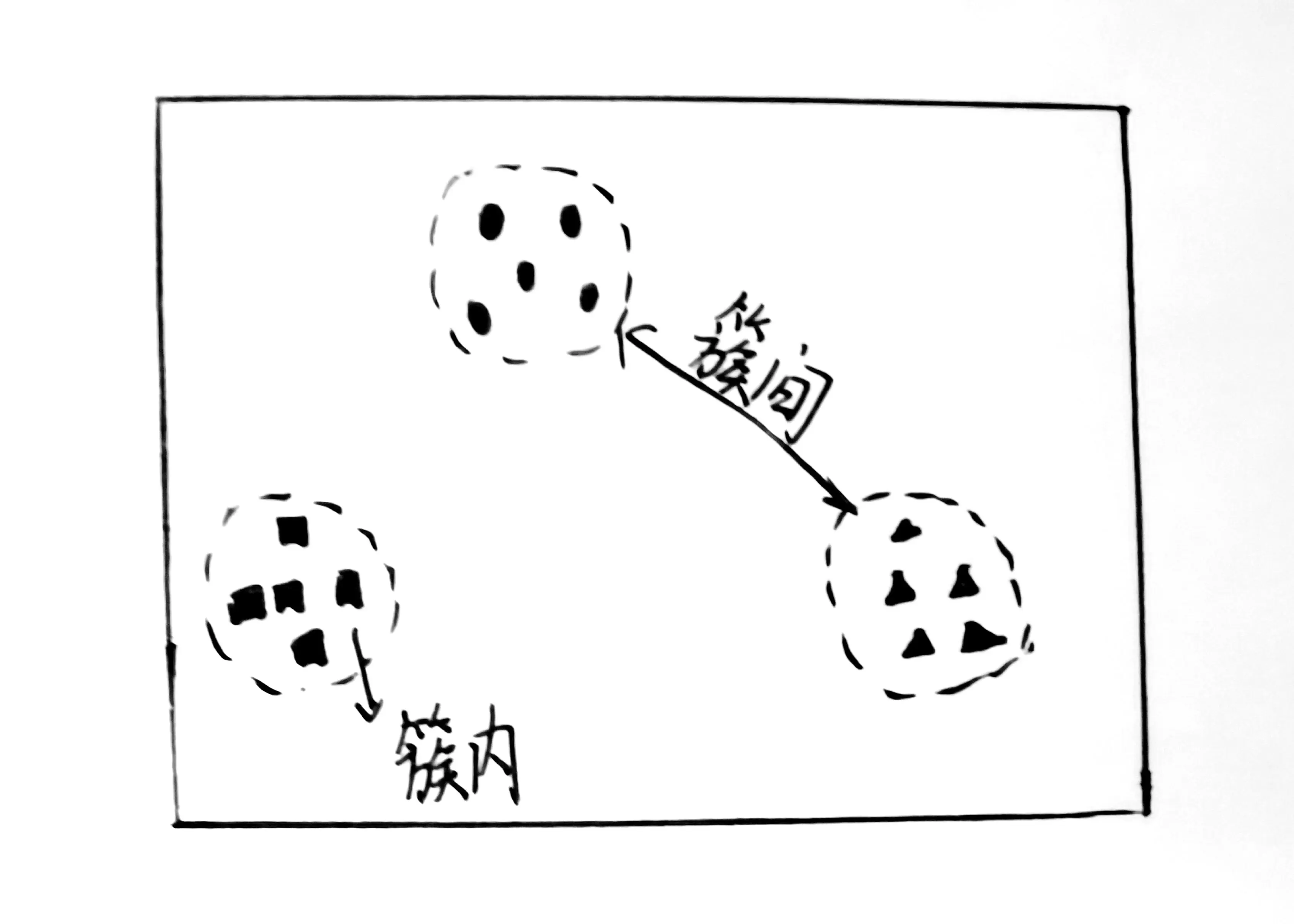
聚类是根据数据相似性将数据聚成簇的方法
简单随机采样(SAS)
随机地从所有N个数据中抽取M个数据,简单随机采样分为有放回的简单随机采样(SRSWR)和无放回的简单随机采样(SRSWOR),两者的差别在于从总体数据中拿出一个数据后,是否将这个数据放回。
2.数据离散化
计算机存储器无法存储无限精度的值,计算机处理器也不能对无限精度的数进行处理,因此在数据预处理中需要进行数据的离散化。另外,某些数据挖掘方法需要离散值的属性,这也催生了对数据进行离散化的需要。
通常每种方法都假定待离散化的值已经控递增序排序
2.1基于信息增益的离散化
在进行数据离散化的过程中,如果关注点主要在于属性值的离散化能够有助于提高分类的准确性,那么可以使用信息增益来进行数据离散化。这种离散化方法是一种自顶向下的拆分方法。
2.2基于卡方检验的离散化
卡方检验是通过两个变量的联合分布来衡量它们是否独立的一种统计工具。在数据离散化中也可以引入这种思想,对于一个属性的两个相邻的取值区间,“属性值处于哪一个的区间”与“数据属于哪一个类别”这两个变量的独立性可以表明是否应该合并两个区间。如果两个变量独立,那么属性值在哪个区间是不影响分类的,意味着这两个区间可以合并。因此可以提出如下自底向上的区间合并算法来对数据进行离散化:每次寻找相关性最小的两个相邻区间进行合并,循环运行直到停止条件。
2.3基于自然分区的离散化
在实际问题中有时也会采用一些经验性的方法,如自然分区法,即3-4-5规则。这种方法将数值型的数据分成相对规整的自然分区。
规则如下:
(1)如果一个区间包含的不同值的数量的最高有效位是3,6,7或9,将该区间等宽地分为3个区间;(2)如果最高有效位是2,4或8,将该区间等宽地分为4个区间;(3)如果最高有效位是1,5或10,将该区间等宽地分为5个区间。
3.概念层次生成
由用户或专家在模式级显式地说明属性的偏序
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。