【AI辅助设计】全村人的希望!FLUX.1模型(附录下载地址)
AI极客菌 2024-08-20 11:01:24 阅读 51
、
在开源AI出图领域,SD3并没有像预期那样好,也没预期那么开放,正当整个开源界都为此惆怅不已的时候,昨晚FLUX.1模型重磅发布,瞬间引爆了整个开源社区。

FLUX.1介绍
该项目是由原Stablity AI 公司的Robin 带着全新组织 Black Forest Labs,开源的一个AI生图模型。FLUX.1 模型套件为不同用户群体提供了灵活的选择,无论是追求极致性能的商业用户,还是希望探索 AI 技术的开发者和研究者,都能找到合适的版本。其强大的性能和丰富的功能,使其成为当前最先进的文本到图像模型之一,并将推动生成式 AI 技术的进一步发展。

版本一览
FLUX.1 模型套件包含三个版本,分别针对不同的用户群体和应用场景:
| 版本 | FLUX.1 [pro] | FLUX.1 [dev] | FLUX.1 [schnell] |
|---|---|---|---|
| 「目标用户」 | 商业用户 | 开发者/研究者 | 个人用户/本地开发 |
| 「权重获取」 | API 访问 | HuggingFace 开放下载 | HuggingFace 开放下载 |
| 「许可证」 | 商业许可 | 非商业许可 | Apache 2.0 |
| 「用途」 | 商业应用 | 非商业应用/研究 | 个人使用/研究 |
| 「质量」 | 最佳 | 接近 pro 版本 | 针对速度优化 |
「共同特点:」
「训练参数:」 120 亿参数 (12B parameters)
「训练架构:」 基于多模态和并行扩散 Transformer 块的混合架构,并结合了流匹配、旋转位置嵌入和并行注意力层等技术。
「支持分辨率:」 支持 0.1 和 2.0 兆(2K)像素的多种纵横比和分辨率。
「突出优势:」 在图像细节、提示遵循、风格多样性和场景复杂性方面均达到业界领先水平,超越了 Midjourney v6.0、DALL·E 3 (HD) 和 SD3-Ultra 等流行模型。
「版本区别:」
「FLUX.1 [pro]:」 性能最佳的版本,提供最先进的图像生成能力和最丰富的功能,适用于对图像质量和功能要求最高的商业用户。
「FLUX.1 [dev]:」 性能接近 pro 版本,但权重开放下载,适用于非商业用途的开发者和研究者。
「FLUX.1 [schnell]:」 速度最快的版本,针对个人用户和本地开发进行了优化,开源且免费使用。
「与竞品的差别:」
「更高的图像质量和细节:」 FLUX.1 模型在图像质量和细节方面超越了现有的大多数文本到图像模型,能够生成更逼真、更精细的图像。
「更强的提示遵循能力:」 FLUX.1 模型能够更准确地理解和遵循用户的文本提示,生成更符合用户意图的图像。
「更丰富的风格多样性:」 FLUX.1 模型能够生成更多样化的图像风格,满足用户不同的创作需求。
「更强的场景复杂性处理能力:」 FLUX.1 模型能够更好地处理复杂的场景,生成更具层次感和细节的图像。
官方公告
Black Forest Labs 正式发布!
我们非常激动地宣布 Black Forest Labs 的成立!作为扎根于生成式人工智能研究领域的团队,我们的使命是开发和推进用于图像、视频等媒体的尖端生成式深度学习模型,并不断突破创造力、效率和多样性的边界。我们坚信,生成式 AI 将成为未来所有技术的基石。通过将我们的模型开放给广大用户,我们希望让每个人都能受益于这项技术,普及 AI 知识,并增强公众对这些模型安全性的信心。我们的目标是打造生成式媒体的行业标杆。今天,作为迈向这一目标的第一步,我们隆重推出 FLUX.1 模型套件,它将引领文本到图像合成的新方向。
Black Forest 团队
我们汇聚了一批杰出的人工智能研究人员和工程师,他们在学术界、工业界和开源领域都拥有开发基础生成式 AI 模型的卓越成就。我们的创新成果包括 VQGAN、Latent Diffusion,以及 Stable Diffusion 系列模型(Stable Diffusion XL、Stable Video Diffusion、Rectified Flow Transformers),以及用于超快速实时图像合成的 Adversarial Diffusion Distillation。
我们坚信,广泛 accessible 的模型不仅能够促进研究社区和学术界的创新与合作,更能提升透明度,从而建立信任并推动技术的广泛应用。我们的团队致力于开发最高质量的技术,并将其惠及最广泛的用户群体。
融资
我们荣幸地宣布,我们已成功完成 3100 万美元的种子轮融资。本轮融资由我们的主要投资者 Andreessen Horowitz 领投,并得到了包括 Brendan Iribe、Michael Ovitz、Garry Tan、Timo Aila 和 Vladlen Koltun 等知名天使投资人以及其他 AI 研究和公司建设领域专家的鼎力支持。此外,我们还获得了来自 General Catalyst 和 MätchVC 的后续投资,这将助力我们实现将源自欧洲的尖端 AI 技术带给全球用户的使命。
同时,我们很高兴地宣布我们的顾问委员会成员,其中包括在内容创作行业拥有丰富经验的 Michael Ovitz,以及神经风格迁移的先驱和欧洲开放式 AI 研究的领军人物 Matthias Bethge 教授。
Flux.1 模型系列
我们隆重推出 FLUX.1 文本到图像模型套件,它在图像细节、提示遵循、风格多样性和场景复杂性方面树立了文本到图像合成的新标杆。
为了兼顾易用性和模型性能,FLUX.1 提供了三种版本:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]:
「FLUX.1 [pro]:」 FLUX.1 的旗舰版本,提供最先进的图像生成性能,具备一流的提示遵循、视觉质量、图像细节和输出多样性。您可以通过我们的 API 注册使用 FLUX.1 [pro]。FLUX.1 [pro] 也可通过 Replicate 和 fal.ai 获取。此外,我们还提供专门定制的企业级解决方案 - 请通过 flux@blackforestlabs.ai 联系我们。
「FLUX.1 [dev]:」 FLUX.1 [dev] 是一个开放权重的指导蒸馏模型,适用于非商业用途。它直接继承了 FLUX.1 [pro] 的优良特性,在保持高质量和提示遵循能力的同时,比同等规模的标准模型更加高效。FLUX.1 [dev] 的权重可在 HuggingFace 上获取,并可直接在 Replicate 或 Fal.ai 上进行测试。如有商业用途需求,请联系 flux@blackforestlabs.ai。
「FLUX.1 [schnell]:」 这是我们速度最快的模型,专为本地开发和个人使用而设计。FLUX.1 [schnell] 基于 Apache2.0 许可证开源发布。与 FLUX.1 [dev] 类似,其权重可在 Hugging Face 上获取,推理代码可在 GitHub 和 HuggingFace 的 Diffusers 中找到。此外,我们很高兴地宣布,FLUX.1 [schnell] 已与 ComfyUI 实现第一天集成。

Transformer 驱动的规模化流模型
所有公开发布的 FLUX.1 模型都基于多模态和并行扩散 Transformer 块的混合架构,并扩展至 120 亿参数规模。我们通过引入流匹配技术改进了现有的扩散模型。流匹配是一种通用的、概念简单的训练生成模型的方法,它将扩散模型视为一种特例。此外,我们还结合了旋转位置嵌入和并行注意力层,进一步提升了模型性能和硬件效率。我们将在近期发布更详细的技术报告。
图像合成的新基准
FLUX.1 为图像合成领域树立了新的标杆。我们的模型在各自的类别中均达到了业界领先水平。FLUX.1 [pro] 和 [dev] 在视觉质量、提示遵循、尺寸/纵横比可变性、排版和输出多样性等方面均超越了 Midjourney v6.0、DALL·E 3 (HD) 和 SD3-Ultra 等流行模型。FLUX.1 [schnell] 则是目前最先进的 few-step 模型,其性能不仅超越了同类竞争对手,甚至可以媲美 Midjourney v6.0 和 DALL·E 3 (HD) 等强大的非蒸馏模型。我们的模型经过精心微调,以保留预训练的全部输出多样性。与现有技术相比,它们提供了显著的改进,如下所示:
所有 FLUX.1 模型版本均支持 0.1 和 2.0 兆像素的多种纵横比和分辨率,如下例所示:
展望未来:面向所有人的尖端文本到视频技术
今天,我们发布了 FLUX.1 文本到图像模型套件。凭借其强大的创作能力,这些模型将为我们即将推出的具有竞争力的生成式 文本到视频系统 奠定坚实基础。我们的视频模型将实现高清、高速的精确视频创作和编辑。我们致力于持续引领生成式媒体的未来。
ComfyUI实测
既然是开源的爱好者,我们的测试仅限于dev和schnell版本,而据各位前方大佬的报道,本地家用硬件,最高可以跑dev版本,效果直逼pro版,所以我们就来看看dev的效果吧。在此之前,先贴一下网友们的样张。





多重曝光效果也不错~


使用方法
❝
注意:对显存要求有点高,目测只有4090或者3090等,24G显存以上显卡才能跑🥱
❞
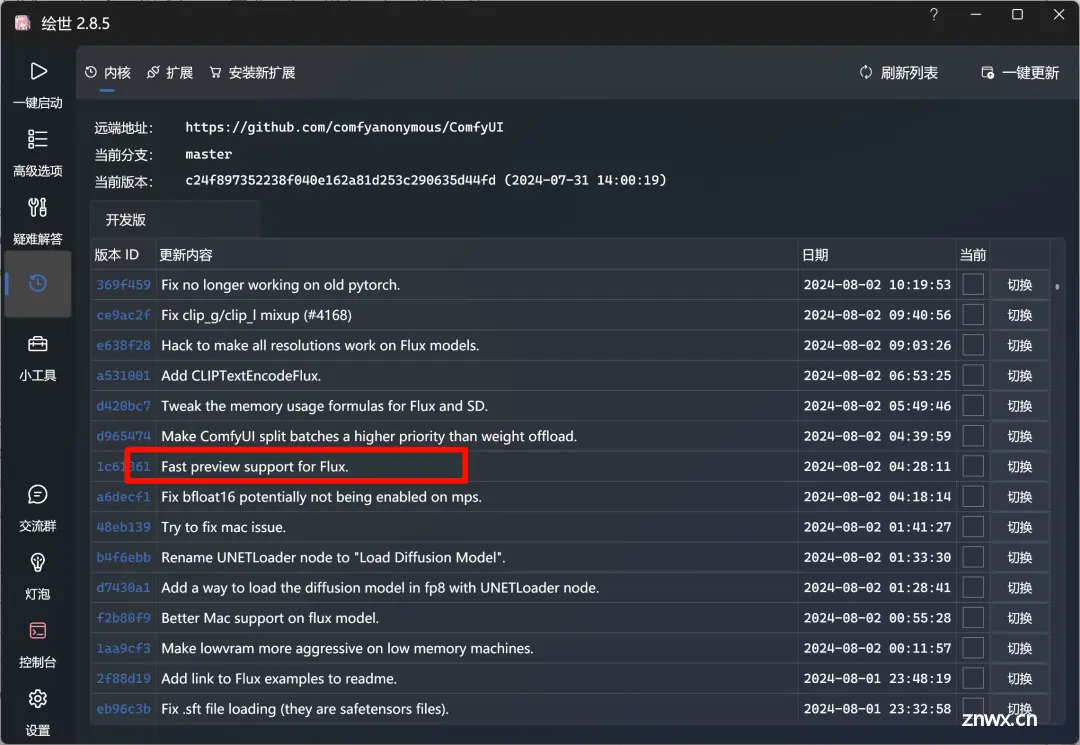
更新ComfyUI
ComfyUI本体已经可以支持FLUX.1,所以直接更新即可。使用秋叶管理器,直接切换,其他版本,可以在ComfyUI目录下,打开终端,运行git pull即可。
下载ComfyUI官方工作流
(需要的同学可以自行扫描获取)

PixPin_2024-08-02_15-05-37.jpg
下载模型
官方模型地址:1.t5xxl_fp16.safetensors和clip_l.safetensors。放在: ComfyUI/models/clip/文件夹。https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main2.flux1-dev.sft。放在:ComfyUI/models/unet/文件夹。https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main
对比测试
我们使用同样的提示词,分别测试Midjourney的6.1模型和FLUX.1,大家对比看看。
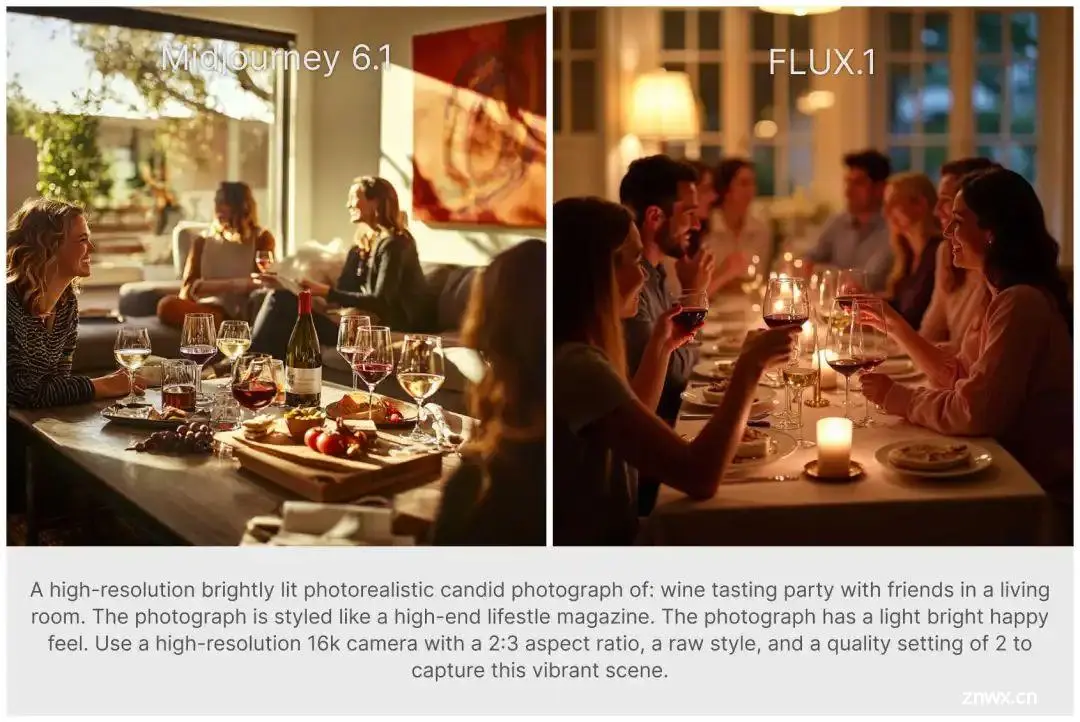



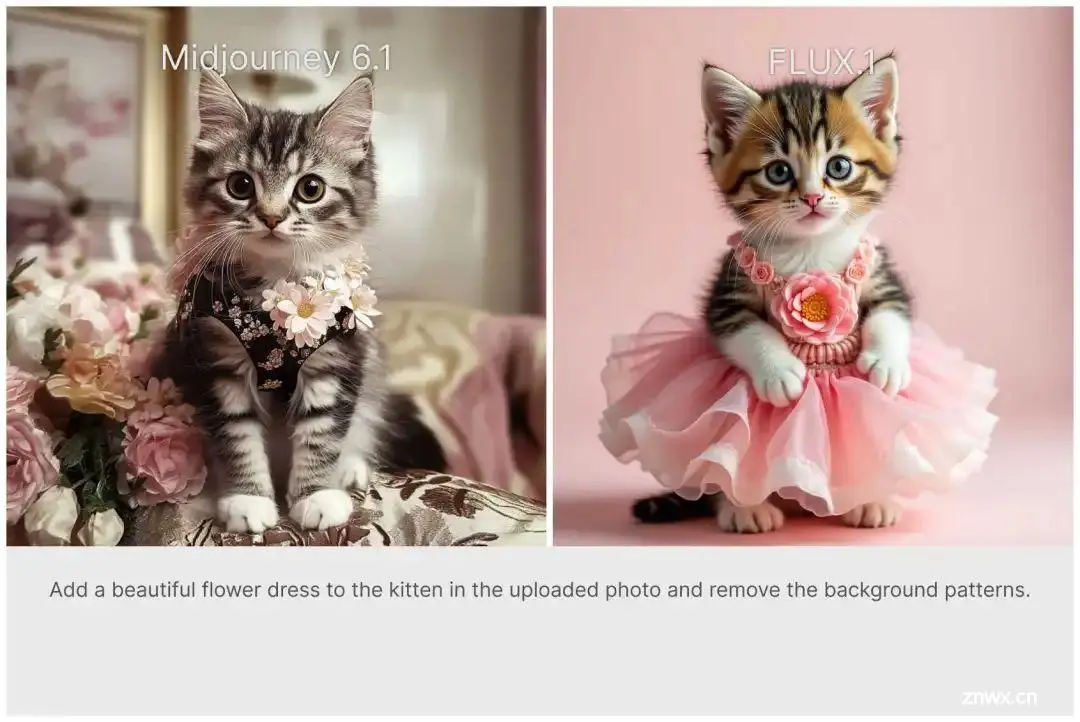
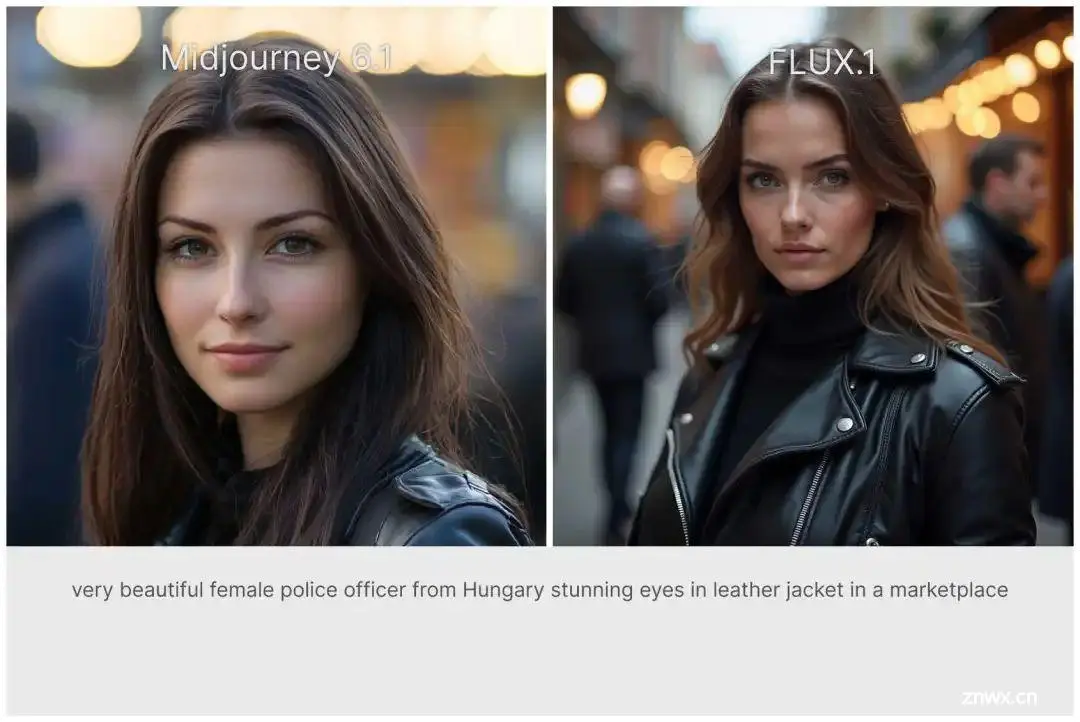





❝
总结,我个人感觉,从艺术性和细节丰富程度看,Midjourney v6.1还是领先一筹,可能需要等待FLUX的微调模型出来吧,像基于SDXL的playground模型一样,增强其艺术感。
不过,从总体的质量看,开源模型,FLUX.1目前最优,大家不妨下载看看~😆。
❞
===
对字体的理解
英文的理解正确率很高,基本能写出提示语的字。





提示语引导词
提示词:
在一张胡桃木的桌子上,左边放着一个镀铬圆球,中间放着一个蓝色的陶瓷立方体,右边摆着一个黄色的水磨石圆锥体。远处是一直可爱的小猫在偷看。

对语义的理解挺到位的,材质都对了。
细节
我们来看一个特写。
提示语
Wrist accessory, light pink gradient, French lace, large butterfly wings,on a girl's hand, gold thread, pearls, waves, embroidery, weaving, tassel

注意手部的结构和细节。


❝
总结,我个人感觉,从艺术性和细节丰富程度看,Midjourney v6.1还是领先一筹,可能需要等待FLUX的微调模型出来吧,像基于SDXL的playground模型一样,增强其艺术感。
不过,从总体的质量看,开源模型,FLUX.1目前最优,大家不妨下载看看~😆。
❞
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

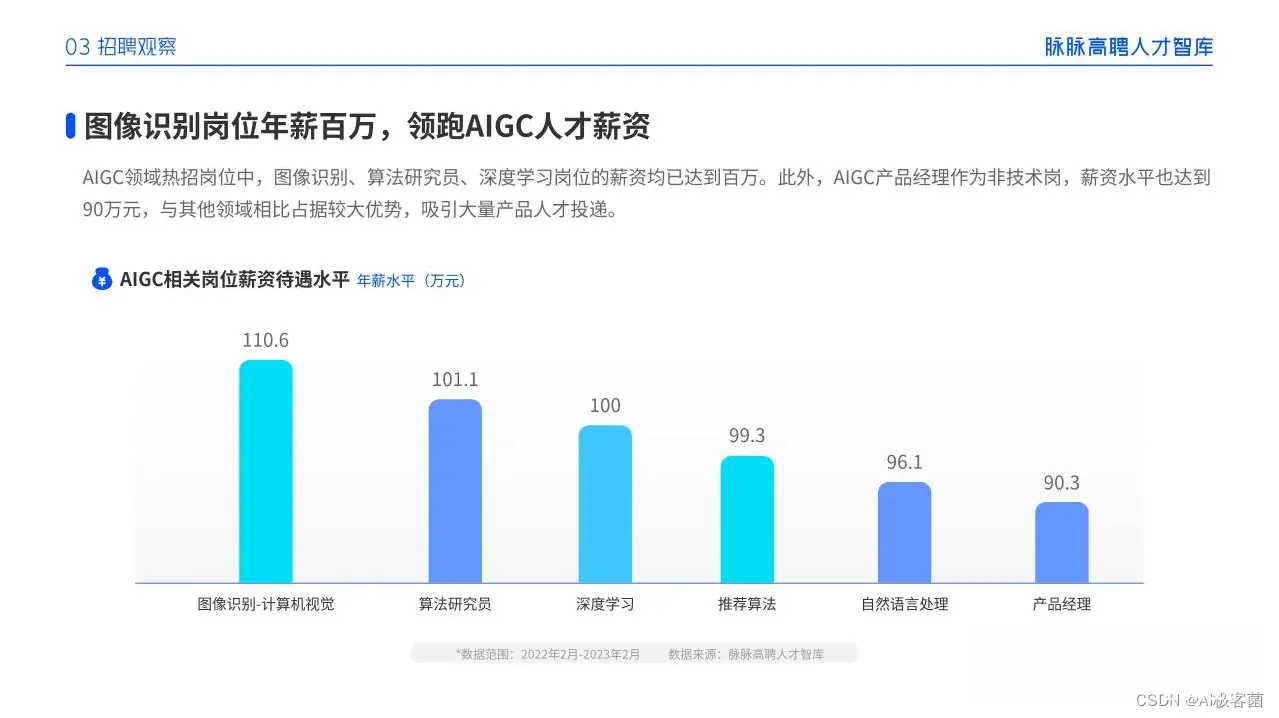
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
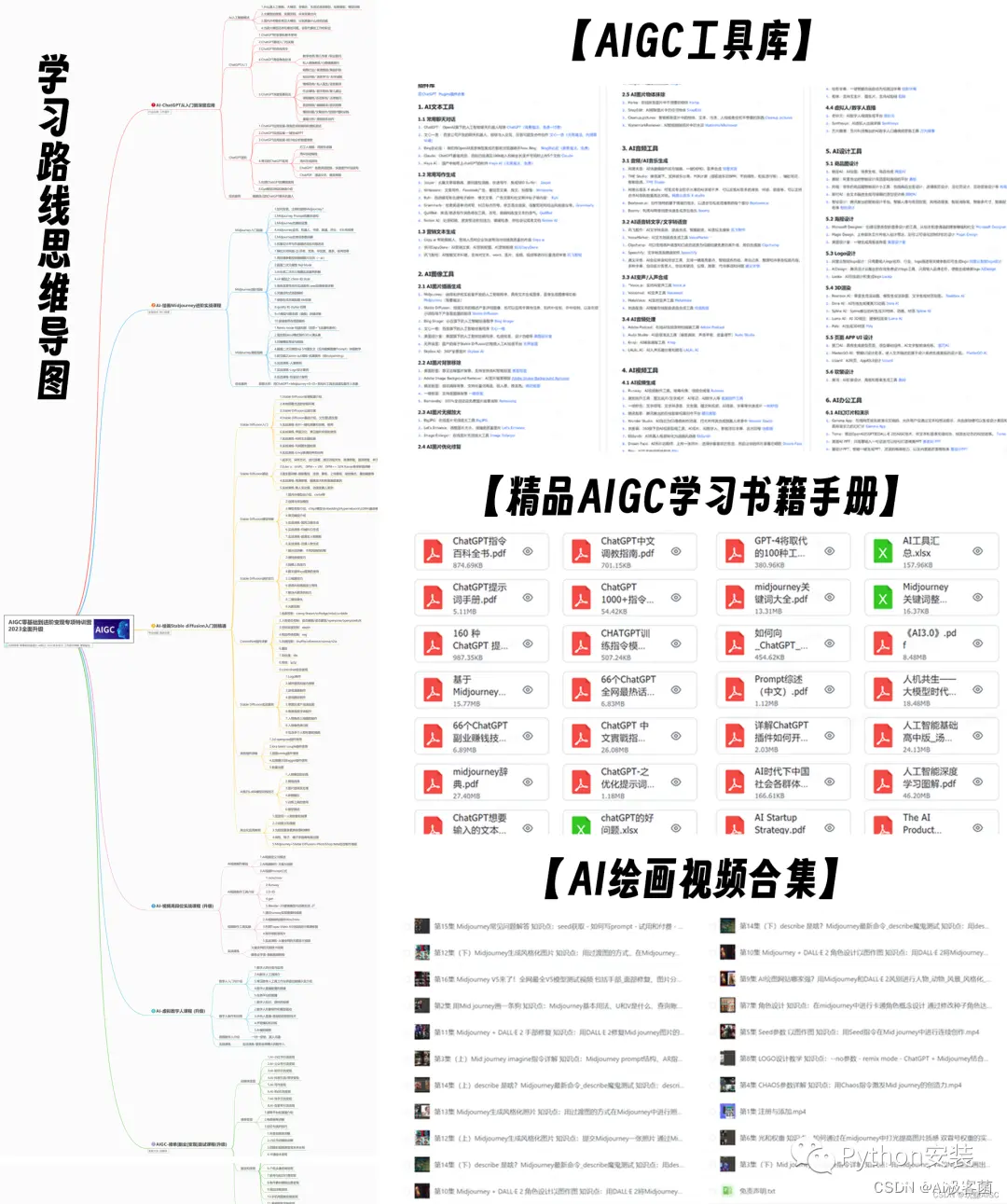
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。