【讯飞星火大模型AI】SpringBoot项目快速接入讯飞星火API
嗯mua. 2024-07-02 17:31:03 阅读 74
【讯飞星火大模型AI】SpringBoot项目快速接入讯飞星火API
文章目录
【讯飞星火大模型AI】SpringBoot项目快速接入讯飞星火API1. 介绍2. 快速入门2.1 配置2.2 创建类
3. 测试
1. 介绍
讯飞官网:讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)
新用户认证之后可以免费领取二百万token,有效期一年,免费薅羊毛。
2. 快速入门
认证完成后,创建一个应用(很简单),点点点就能完成。
2.1 配置
创建完成之后,去github上找到讯飞开放平台的sdk,推荐下面这个:
<dependency>
<groupId>io.github.briqt</groupId>
<artifactId>xunfei-spark4j</artifactId>
<version>1.2.0</version>
</dependency>
github地址:仓库地址
在项目当中引入这个依赖,然后在yml文件当中进行配置:
# 讯飞星火配置
xunfei:
client:
appid: xxx
apiSecret: xxx
apiKey: xxx
关于这几个值的填写,可以进入控制台-讯飞开放平台 (xfyun.cn)查看,如下图方框框起的数据就是。
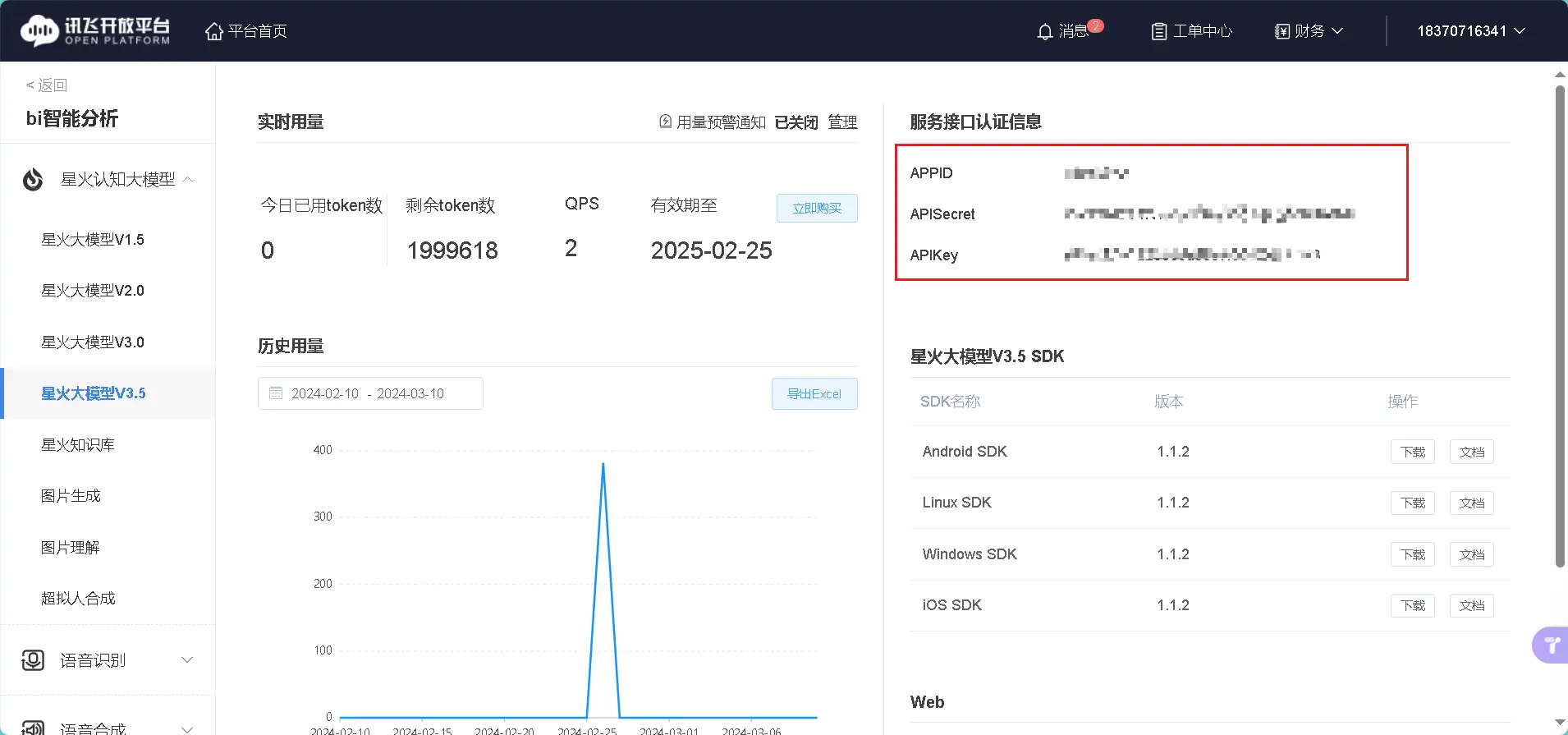
2.2 创建类
首先创建一个配置类来读取配置信息:
@Configuration
@ConfigurationProperties(prefix = "xunfei.client")
@Data
public class XingHuoConfig {
private String appid;
private String apiSecret;
private String apiKey;
@Bean
public SparkClient sparkClient() {
SparkClient sparkClient = new SparkClient();
sparkClient.apiKey = apiKey;
sparkClient.apiSecret = apiSecret;
sparkClient.appid = appid;
return sparkClient;
}
}
再创建一个SparkManager类,用来调用星火AI,在这里我们让AI扮演一名数据分析师,根据我们的输入,做出预设的反应:
@Component
@Slf4j
public class SparkManager {
@Resource
private SparkClient sparkClient;
/**
* AI生成问题的预设条件
*/
public static final String PRECONDITION = "你是一个数据分析师和前端开发专家,接下来我会按照以下固定格式给你提供内容:\n" +
"分析需求:\n" +
"{数据分析的需求或者目标}\n" +
"原始数据:\n" +
"{csv格式的原始数据,用,作为分隔符}\n" +
"请根据这两部分内容,按照以下指定格式生成内容(此外不要输出任何多余的开头、结尾、注释)\n" +
"【【【【【\n" +
"{前端 Echarts V5 的 option 配置对象js代码,合理地将数据进行可视化,不要生成任何多余的内容,比如注释}\n" +
"【【【【【\n" +
"{明确的数据分析结论,越详细越好,不要生成多余的注释\n}" +
"最终格式是:【【【【【前端代码【【【【【分析结论";
/**
* 向星火AI发送请求
*
* @param content
* @return
*/
public String sendMesToAIUseXingHuo(final String content) {
// 消息列表,可以在此列表添加历史对话记录
List<SparkMessage> messages = new ArrayList<>();
messages.add(SparkMessage.systemContent(PRECONDITION));
messages.add(SparkMessage.userContent(content));
// 构造请求
SparkRequest sparkRequest = SparkRequest.builder()
// 消息列表
.messages(messages)
// 模型回答的tokens的最大长度,非必传,默认为2048
.maxTokens(2048)
// 结果随机性,取值越高随机性越强,即相同的问题得到的不同答案的可能性越高,非必传,取值为[0,1],默认为0.5
.temperature(0.2)
// 指定请求版本
.apiVersion(SparkApiVersion.V3_5)
.build();
// 同步调用
SparkSyncChatResponse chatResponse = sparkClient.chatSync(sparkRequest);
String responseContent = chatResponse.getContent();
log.info("星火AI返回的结果{}", responseContent);
return responseContent;
}
}
当然,对于AI的角色和用户的提问都是可以随意进行设置的。
3. 测试
我们创建一个测试类:
@SpringBootTest
public class SparkManagerTest {
@Resource
private SparkManager sparkManager;
private final String userInput =
"分析需求:\n" +
"分析网站用户的增长情况\n" +
"请使用:折线图\n" +
"原始数据:\n" +
"日期,用户数\n" +
"1号,10 \n" +
"2号,20\n" +
"3号,30";
@Test
public void testApi() {
String result = sparkManager.sendMesToAIUseXingHuo(userInput);
System.out.println(result);
}
}
运行这个测试方法,输出如下所示:
【【【【【
{
"title": {
"text": "网站用户增长情况"
},
"tooltip": {
"trigger": "axis"
},
"legend": {
"data": ["用户数"]
},
"xAxis": {
"data": ["1号", "2号", "3号"]
},
"yAxis": {},
"series": [{
"name": "用户数",
"type": "line",
"data": [10, 20, 30]
}]
}
【【【【【
从折线图可以看出,该网站在1号至3号期间,用户数量呈明显上升趋势,每天的用户增长率为100%,显示出良好的增长势头。
那么我们就能够根据AI给出的回答进行一个截取,得到我们想要的数据。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。