详解 Tree-structured Parzen Estimator(TPE)
None072 2024-07-22 08:01:07 阅读 63
Brief Introduction
TPE(Tree-structured Parzen Estimator),是一种基于树结构的贝叶斯优化算法,用于解决黑盒函数的全局最优化问题。
在每次试验中,对于每个超参,TPE 为与最佳目标值相关的超参维护一个高斯混合模型 l(x),为剩余的超参维护另一个高斯混合模型 g(x),选择 l(x)/g(x)最大化时对应的超参作为下一组搜索值。通过这种方式,TPE 算法能够自适应地调整参数搜索空间的大小,并且能够在尽可能少的迭代次数内找到全局最优解。
主要适用的情景:
x 的维度不是太大,一般会限制在 d<20,x 可以理解为一个超参数序列f(x) 是一个计算起来很消耗时间的函数,例如损失函数对 f(x) 很难求导
与基于 GP 方法的区别
GP 直接对给定输入 x 与输出 y 的后验概率分布
p
(
y
∣
x
)
p(y|x)
p(y∣x) 进行建模。在这种方法中,通过计算训练数据集中的数据点之间的协方差矩阵来定义一个高斯分布,从而建立起输入与输出之间的联合概率分布。这种方法的优点在于可以自适应地学习输入与输出之间的复杂关系,并且可以提供不确定性估计。
TPE 分别对条件概率分布
p
(
x
∣
y
)
p(x|y)
p(x∣y) 和边缘概率分布
p
(
y
)
p(y)
p(y) 进行建模,然后通过贝叶斯公式来计算后验概率分布
p
(
y
∣
x
)
p(y|x)
p(y∣x)。这种方法的优点在于可以更灵活地对不同的因素进行建模,并且可以更好地处理缺失数据和噪声。
Tree-structured
超参数优化问题可以理解为在图结构的参数空间上不断寻找 objective function 最优解的问题。所谓 tree,是提出 TPE 的作者将该优化问题限制在了树状结构上,例如:
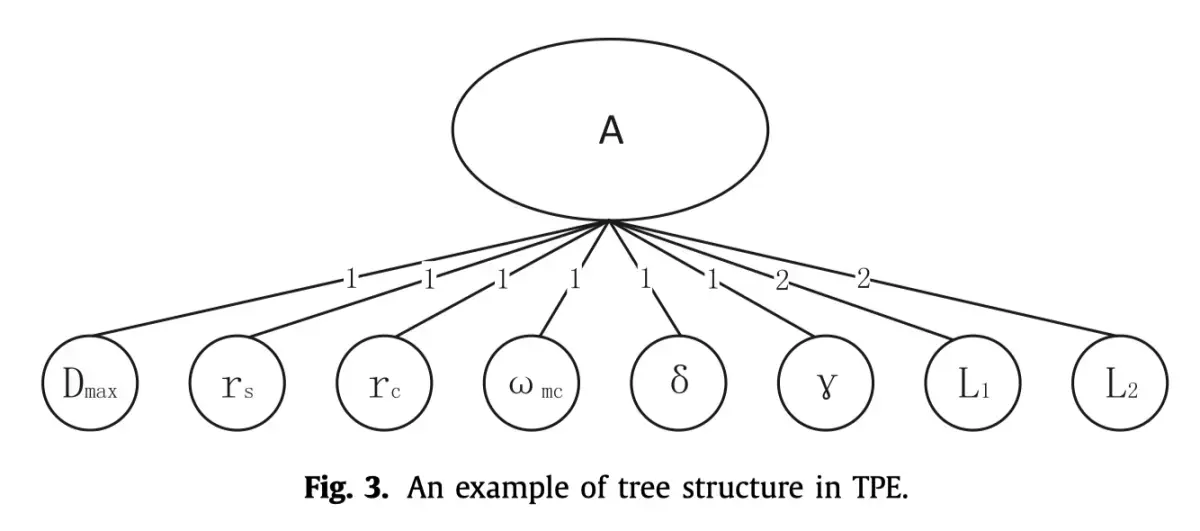
一些超参数只有在其它的超参数确定后才能够进行确认,例如网络的层数与每一层的节点数量,当然这不意味着这两个超参数是相关的。实际上在 TPE 中,要求所估计的超参数必须是相互独立的。
Optimizing EI in the TPE algorithm
TPE 使用两个密度函数来定义
p
(
x
∣
y
)
p(x|y)
p(x∣y):
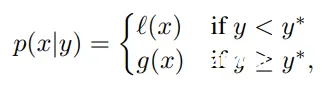
l
(
x
)
l(x)
l(x) 是使用观测空间
{
x
(
i
)
}
\{x ^{(i)}\}
{ x(i)} 来建立的,该观测空间对应的损失
f
(
x
(
i
)
)
f(x ^{(i)})
f(x(i)) 小于
y
∗
y^*
y∗,使用剩下的观测来建立
g
(
x
)
g(x)
g(x)。
基于 GP 的方法偏向更大的
y
∗
y^*
y∗,基于 TPE 的方法取决于比当前所观测到最好的
f
(
x
)
f(x)
f(x) 更大的
y
∗
y^*
y∗,这样一些点就可以用于建立
l
(
x
)
l(x)
l(x)。
TPE 选择期望改进(expected improvement,EI)作为采集函数,由于无法得到
p
(
y
∣
x
)
p(y|x)
p(y∣x),我们使用贝叶斯公式进行如下转换:
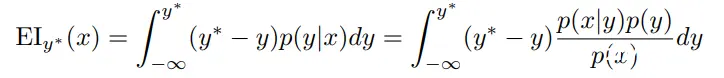
其中,
y
∗
y^*
y∗ 代表阈值,我们令
γ
=
p
(
y
<
y
∗
)
γ = p(y < y^∗ )
γ=p(y<y∗),表示 TPE 算法的一定分位数,用于划分
l
(
x
)
l(x)
l(x) 和
g
(
x
)
g(x)
g(x),范围在(0,1)之间。
采集函数用于确定在何处采集下一个样本点。
为了简化上式,我们首先对分母进行构造:
p
(
x
)
=
∫
p
(
x
∣
y
)
p
(
y
)
d
y
=
γ
l
(
x
)
+
(
1
−
γ
)
g
(
x
)
p(x)=∫p(x∣y)p(y)dy=γl(x)+(1−γ)g(x)
p(x)=∫p(x∣y)p(y)dy=γl(x)+(1−γ)g(x)
假设我们有 100 个观测值,
γ
\gamma
γ 设置为 0.2,意味着我们将使用 20 个最佳观测值来构建好的分布,其余的 80 个用于构建坏的分布。
其次,对于分子,我们可以得到
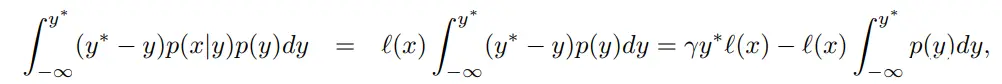
最后,EI 可以化简为
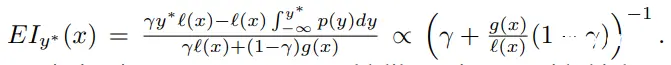
最后一个表达式表明,为了最大化 EI,我们希望在点 x 下
l
(
x
)
l(x)
l(x) 概率高的同时
g
(
x
)
g(x)
g(x) 概率低。在每次迭代中,算法返回具有最大 EI 的候选
x
∗
x^*
x∗:
x
∗
=
a
r
g
m
a
x
E
I
y
∗
(
x
)
x^*=argmax\ EI_{y^*}(x)
x∗=argmax EIy∗(x)
Optimizing EI 例子
下面是一个例子,解释了上述迭代过程。来自 https://www.youtube.com/watch?v=bcy6A57jAwI,这个视频对 TPE 讲述得非常透彻,推荐观看。
假设 f (蓝线)是我们要估计的黑盒函数(例如神经网络中的损失函数),我们的目的是要找出最小的损失函数值所对应的超参数。首先根据设定好的一定分位数
γ
\gamma
γ,将我们事先采样到的一些观测分类。如下图所示,高于阈值的值意味着我们的损失过大,因此对应的点被划分到 bad group,剩下的就被划分为 good group。
然后,分别计算 good group 和 bad group 的概率密度函数
l
(
x
)
,
g
(
x
)
l(x),g(x)
l(x),g(x)。具体的计算方法在下一节会进行解释。之后,将
l
(
x
)
,
g
(
x
)
l(x),g(x)
l(x),g(x) 代入之前提到的 EI 公式,我们得到了 EI 函数的表达式。求该函数极大值所对应的参数,即期望改进最大处的超参数,将其作为新采样点进入下一次迭代,然后将这个新采样点加入 good group 或 bad group,如此反复迭代。
(下面这个图的虚线标注有一些错误,应该和 EI 的极值点重合)
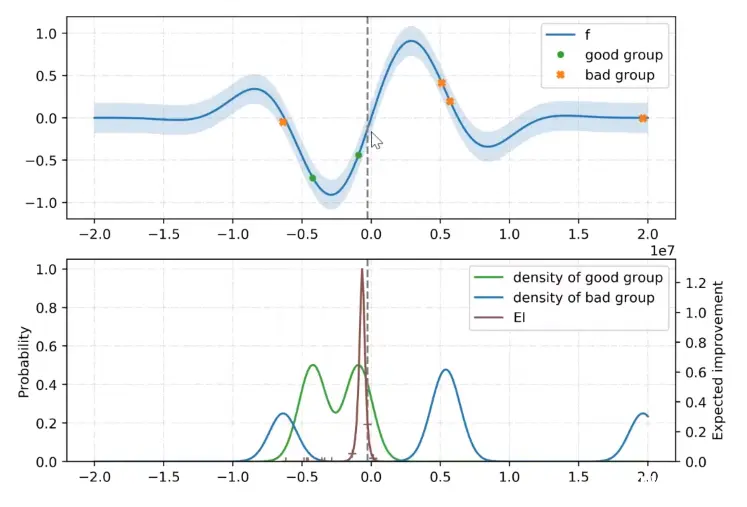
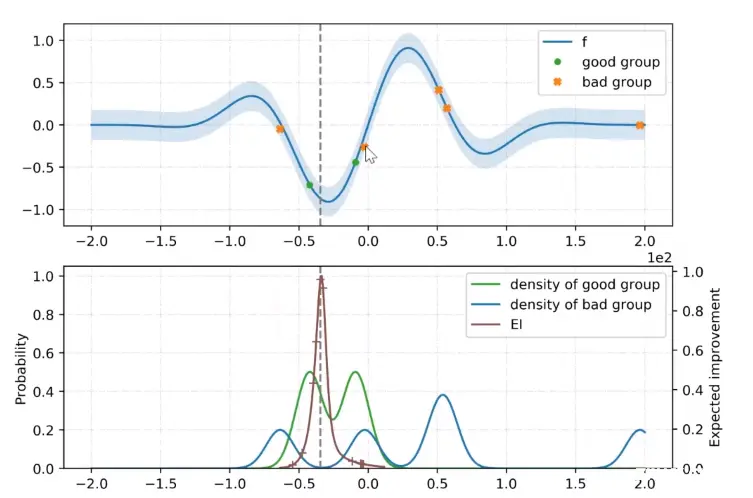
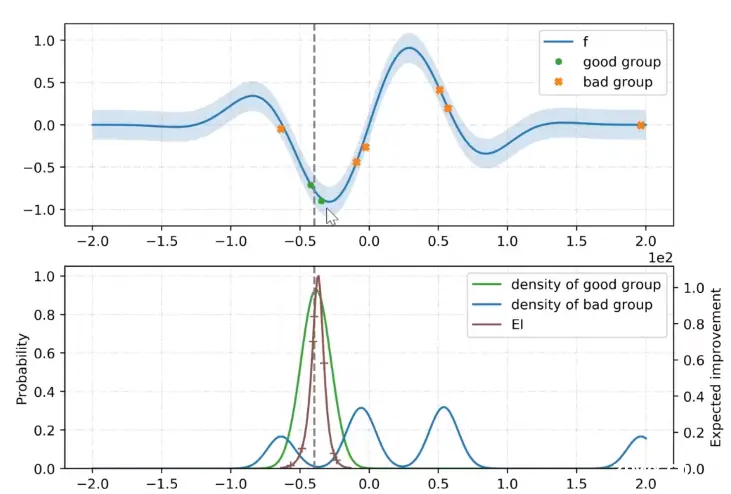
Parzen Window
如何使用核密度估计器来分别建模黑盒函数中较差和较好参数的概率分布(即如何得到
l
(
x
)
,
g
(
x
)
l(x),g(x)
l(x),g(x)),TPE 算法使用 Parzen Window 来实现。
Parzen–Rosenblatt window (Parzen 窗)是在核密度估计问题(Kernel density estimation)中,由 Emanuel Parzen 和 Murray Rosenblatt 提出的能够根据当前的观察值和先验分布类型,估计估计值的概率密度。
Parzen window 的概率密度估计公式为:
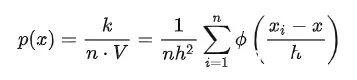
计数函数
ϕ
(
x
i
−
x
h
)
\phi(\frac{x_i-x}{h})
ϕ(hxi−x) 也被称作窗函数,也可以使用高斯函数作为窗函数,即距离
x
i
x_i
xi 越近则计数权重越大:
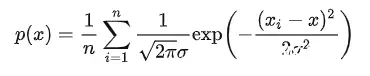
且满足
∫
p
(
x
)
d
x
=
1
\int p(x)dx=1
∫p(x)dx=1。明显看出,上式与高斯混合模型(GMM)类似。因此,在有关 TPE 的大部分文章中,都将 Parzen window 当作 GMM 来解释。
Gaussian Mixture Model 和 使用高斯函数作为窗函数的 Parzen window 有什么联系?
Gaussian Mixture Model(GMM)和使用高斯函数作为窗函数的 Parzen window 是两种不同的概率密度估计方法,但它们都可以被看作是在数据集上使用一些基函数(如高斯函数)进行加权求和来估计未知概率密度函数。
具体来说,GMM 是一种将多个高斯分布加权组合成一个更复杂分布的方法。在 GMM 中,我们假设数据是由若干个高斯分布的加权和组成的,每个高斯分布对应一个聚类中心(也称为“高斯混合成分”)。这些聚类中心的均值和协方差可以通过最大似然估计来确定。通过这种方式,GMM 可以很好地建模复杂的数据分布,因为它可以适应不同的聚类和变异度。
与此相反,使用高斯函数作为窗函数的 Parzen window 方法是一种非参数密度估计方法。在这种方法中,我们首先选择一个核函数(如高斯函数),然后将它放在每个数据点上,计算每个数据点周围的核函数的加权和来估计该点的密度。具体来说,窗口的大小可以通过调整核函数的带宽来控制。这种方法的优点是可以适应不同的数据分布,但是由于它需要计算每个数据点周围的核函数的加权和,因此计算复杂度较高。
需要注意的是,当高斯函数作为 Parzen 窗口的核函数时,它与 GMM 中的高斯分布非常相似。在这种情况下,高斯函数的带宽可以看作是 GMM 中高斯分布的协方差矩阵的平方根。因此,可以将 GMM 视为一种具有固定带宽的 Parzen 窗口方法。
(回答来自 ChatGPT)
在超参数优化中,对于不同类型的超参数,应该使用什么分布?
类别——类别分布(Categorical Distribution)
实数/整数——
在原始空间采样——截断高斯混合模型 Mixture of Truncated Gaussian在对数空间采样——对数空间的截断高斯混合模型
为什么使用截断高斯混合模型?
因为在随机搜索中,我们实际上指定了搜索值的范围。我们想在 TPE 中也实现这样的操作,因此将超过范围的值强制设置为 0。并且我们认为,每个点(超参数)对应一个高斯分布,所以使用截断高斯混合模型。
**Mixture of Truncated Gaussian(截断高斯混合模型)**是一种概率分布模型,它由多个截断高斯分布组成,每个分布的参数可能不同。在这个模型中,每个高斯分布都是被截断的,也就是说,它们的密度函数在某些范围之外为零。这个范围通常是指定为一个有限的区间,超出该区间的值的概率被定义为零。截断高斯混合模型通常用于对数据集建模,特别是当数据集包含多个不同的子集,每个子集都服从不同的高斯分布时。在这种情况下,截断高斯混合模型可以有效地对数据集进行建模,并且能够捕获多个高斯分布的特征。这个模型可以应用于许多领域,例如模式识别,数据挖掘和机器学习。
Parzen Window 例子
假设现在有三个观测值,每个观测值对应一个高斯分布(红色虚线)
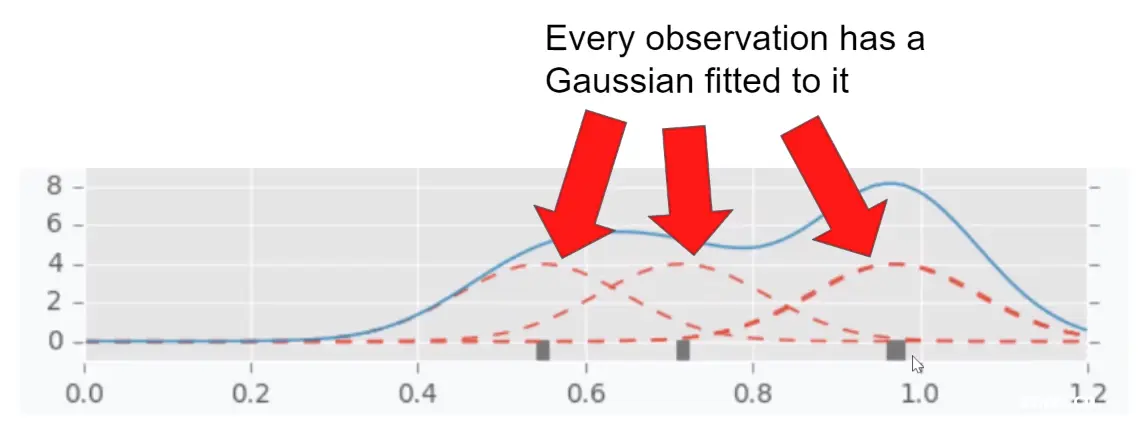
现在按顺序将这些高斯分布的标准差设为左右邻居间的最大距离,有了不同的高斯分布,然后将这些分布混合成 single distribution(蓝色曲线)。
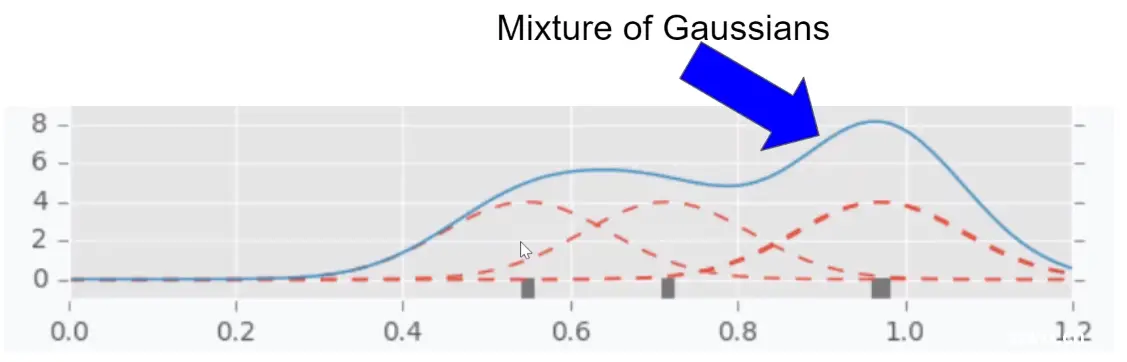
在混合高斯分布中,如何计算某个点的概率密度?
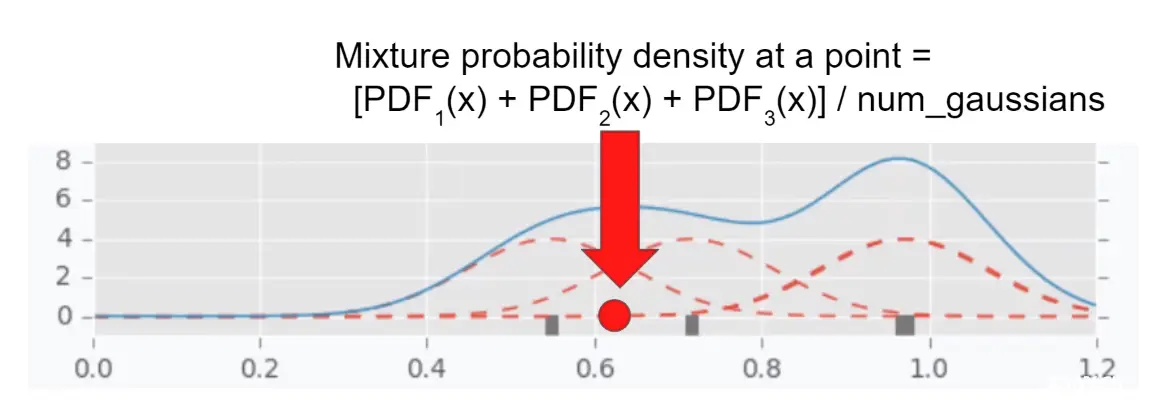
对于上述的例子,该点的概率为每个分布上概率之和除以分布数量。
参考文献
贝叶斯超参数优化Bergstra, James, et al. "Algorithms for hyper-parameter optimization." Advances in neural information processing systems 24 (2011).https://en.wikipedia.org/wiki/Kernel_density_estimationAutomated Machine Learning - Tree Parzen Estimator (TPE)https://blog.csdn.net/lly1122334/article/details/88345256#t7https://blog.csdn.net/jose_M/article/details/106214842Parzen window 密度估计——一种非参数概率密度函数估计方法
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。