【人工智能Ⅰ】实验9:BP神经网络
MorleyOlsen 2024-06-21 11:31:10 阅读 68
实验9 BP神经网络
一、实验目的
1:掌握BP神经网络的原理。
2:了解BP神经网络的结构,以及前向传播和反向传播的过程。
3:学会利用BP神经网络建立训练模型,并对模型进行评估。即学习如何调用Sklearn中的BP神经网络。
4:学会使用BP神经网络做预测。
5:通过截图和模型评估等方法对结果进行分析,分析不同数据中学习率和隐层神经元对与输出结果的影响。
二、实验内容
1:第一部分:
利用BP神经网络实现对鸢尾花的分类和预测,对数据进行可视化,分析数据的特点,建立模型,并对模型进行评估。数据可通过下述代码获取。
| pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
|
2:第二部分:
用BP神经网络做一个手写数字的识别和预测,实验可以先从小样本尝试训练和测试,然后再用大样本进行训练和测试,观察两者结果的差异性。本次实验给出的数据集是:mnist_train_100.csv(大样本),mnist_test_10.csv(小样本);mnist_train.csv, mnist_test.csv。数据椎间中每行是一个样本,第一个元素是标签,后面784个元素是由28*28的图片数据reshape为一行组成的。
三、实验结果与分析
1:第一部分(BP神经网络对鸢尾花进行分类和预测)
【1:加载和预处理数据】
在任务1中,通过pandas库读取鸢尾数据集的信息,并将各列属性存入df.columns中,并提取特征和标签。通过train_test_split功能,以7:3的比例划分训练集和测试集,并对其进行标准化操作。整体代码如下图所示。

【2:数据可视化和分析】
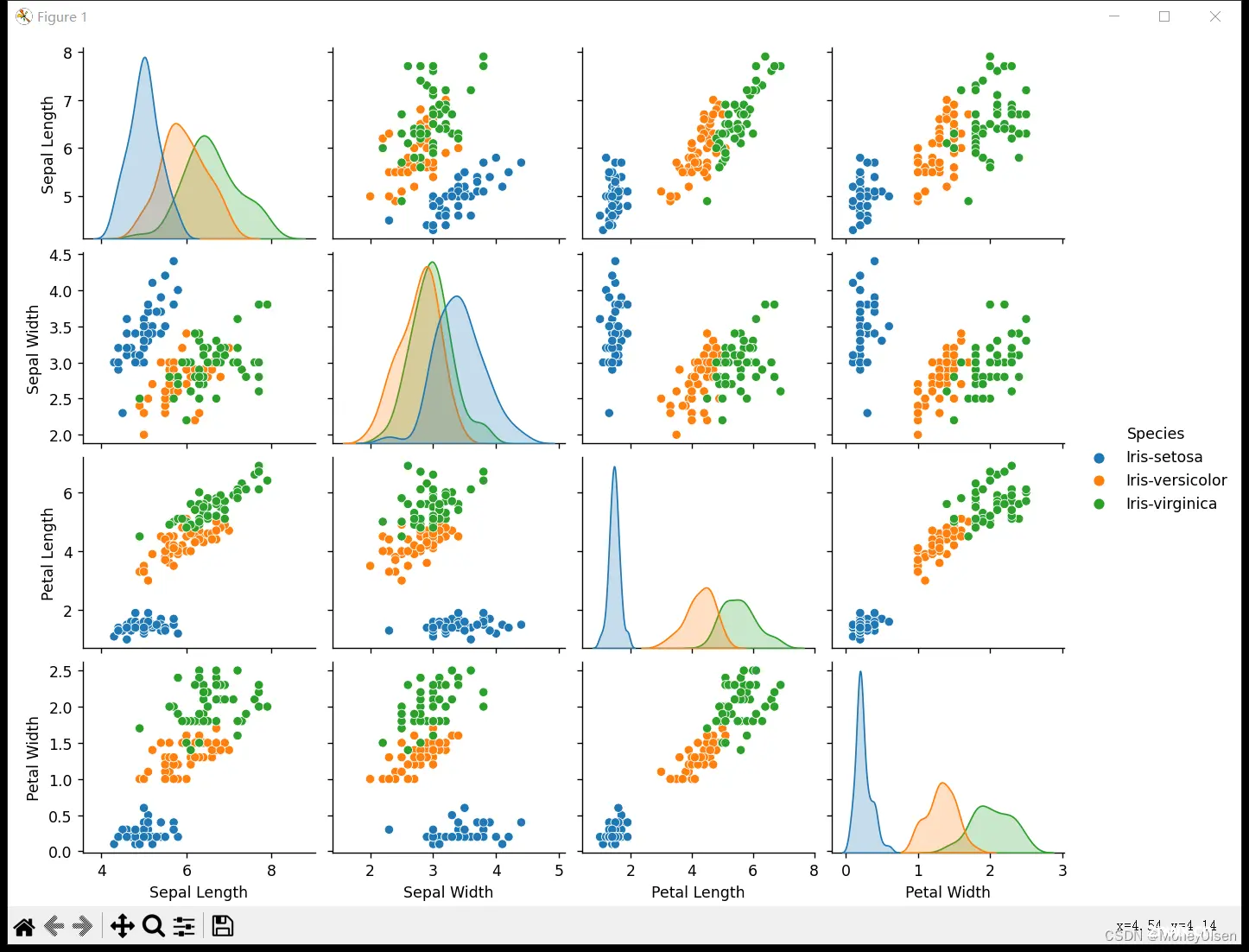
在任务2中,通过调用seaborn库对特征进行对比,并画出每两个特征之间的二维分布关系图和各类鸢尾在当前特征下的分布情况。整体代码和数据集可视化结果如下图所示,其中图1为整体代码,图2为数据集可视化结果。
(图1)

(图2)
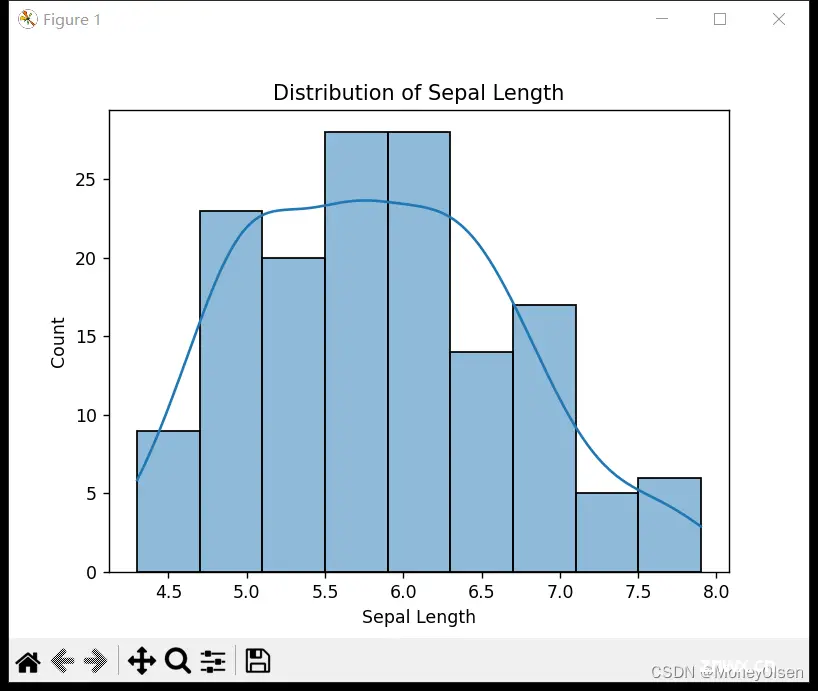
同时,在任务2中创建了各个特征的直方图,以验证上图中的数据分布是否正确。整体代码和直方图可视化结果如下图所示,其中图1为整体代码,图2为花萼长度直方图,图3为花萼宽度直方图,图4为花瓣长度直方图,图5为花瓣宽度直方图。
(图1)
(图2)
(图3)

(图4)
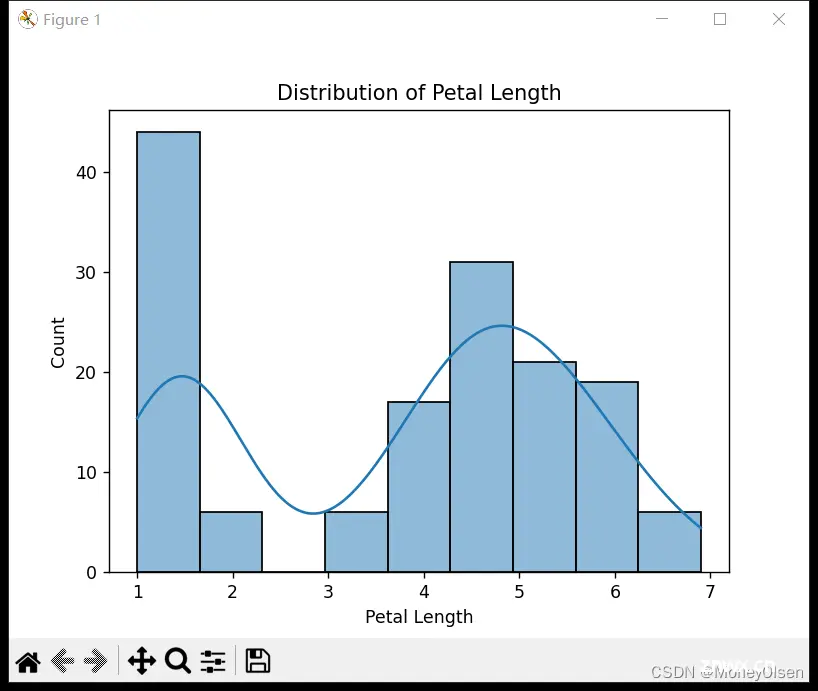
(图5)
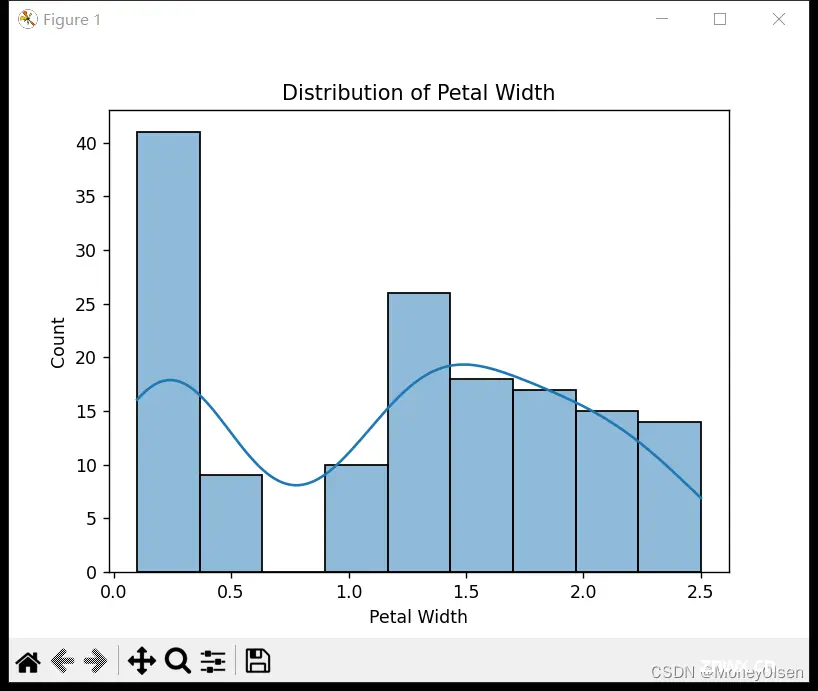
【3:构建神经网络模型】
在任务3中,调用sklearn库中的多层感知器分类器(Multilayer Perceptron Classifier),创建BP神经网络模型。在神经网络中,设置初始学习速率为0.001,最大迭代次数为1000,设置2层神经元个数均为10的隐藏层。整体代码如下图所示。

【4:训练模型】
在任务4中,调用fit来使用训练集对该模型进行训练。整体代码如下图所示。

【5:评估模型】
在任务5中,计算该模型在训练集上的准确率和在测试集上的准确率,并输出相应的计算结果。整体代码和输出结果如下图所示,其中图1为整体代码,图2为程序输出的计算结果(训练集准确率为98%,测试集准确率为98%)。
(图1)
(图2)
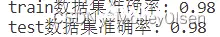
2:第二部分(BP神经网络对小规模手写数字数据集进行识别和预测)
【0:导入参考实验代码】
在任务0中,导入neuralNetwork类中的相关代码。
【1:设置模型参数】
在任务1中,人工填入BP神经网络模型的输入节点数、隐藏节点数、输出层节点数、学习速率。整体代码如下图所示。

【2:创建神经网络实例】
在任务2中,调用neuralNetwork类,传入各类模型参数后赋给变量n,进行模型的存储。整体代码如下图所示。

【3:加载MNIST训练数据集】
在任务3中,打开存储训练集信息的csv文件,并加载到training_data_list中。整体代码如下图所示。

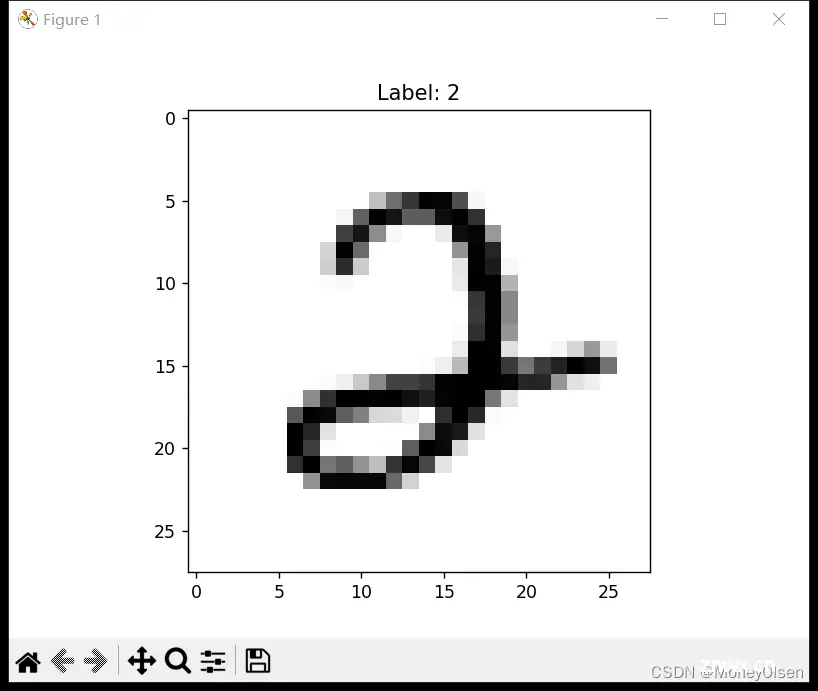
【4:数据集抽样可视化】
在任务4中,利用随机种子抽取一个样本数据,然后调用matplotlib库进行图像展示,并标注其真实的标签类别。整体代码如下图所示,其中图1为整体代码,图2为抽样输出结果。
(图1)

(图2)
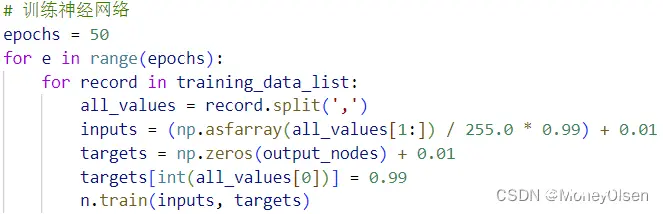
【5:训练神经网络】
在任务5中,首先设置模型训练的迭代次数epochs,然后通过外层for循环训练每一代模型。内存for循环遍历每一个训练集数据,输入特征首先转换为浮点数,然后归一化到0.01到1.00的范围内,以便准备神经网络的输入。同时,将输出结果的标记正确的分类任务输出节点,最后调用神经网络类中的train()函数进行训练。整体代码如下图所示。
【6:加载MNIST测试数据集】
在任务6中,打开存储测试集信息的csv文件,并加载到test_data_list中。整体代码如下图所示。

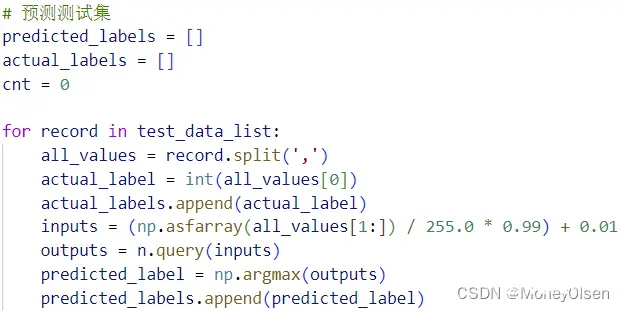
【7:预测测试集】
在任务7中,初始化预测的标签集合predicted_labels、数据点真实的标签集合actual_labels和模型预测正确的个数cnt。在for循环中,遍历每一个测试集数据,并对输入和输出做预处理,然后调用神经网络类中的query()函数进行预测,最后将预测结果的标签加入predicted_labels中。整体代码如下图所示。
【8:计算准确率】
在任务8中,对比predicted_labels和actual_labels中的每一个标签,如果对应相等则cnt自增1,表明该数据点预测正确。最后计算准确率,且公式为:准确率 = 预测正确的个数 / 训练集数据的总数。整体代码和准确率计算结果如下图所示,其中图1为整体代码,图2为计算的准确率结果(分类的准确率为0.7)。
(图1)

(图2)
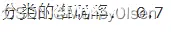
【9:输出混淆矩阵】
在任务9中,调用sklearn库中的混淆矩阵(confusion matrix),对测试集上的预测结果进行可视化显示。其中,x轴为模型预测的标签值,y轴为真实数据的标签值。整体代码、标签对比结果和混淆矩阵结果如下图所示,其中图1为整体代码,图2为程序输出的标签对比结果,图3为程序输出的混淆矩阵结果。
(图1)

(图2)

(图3)
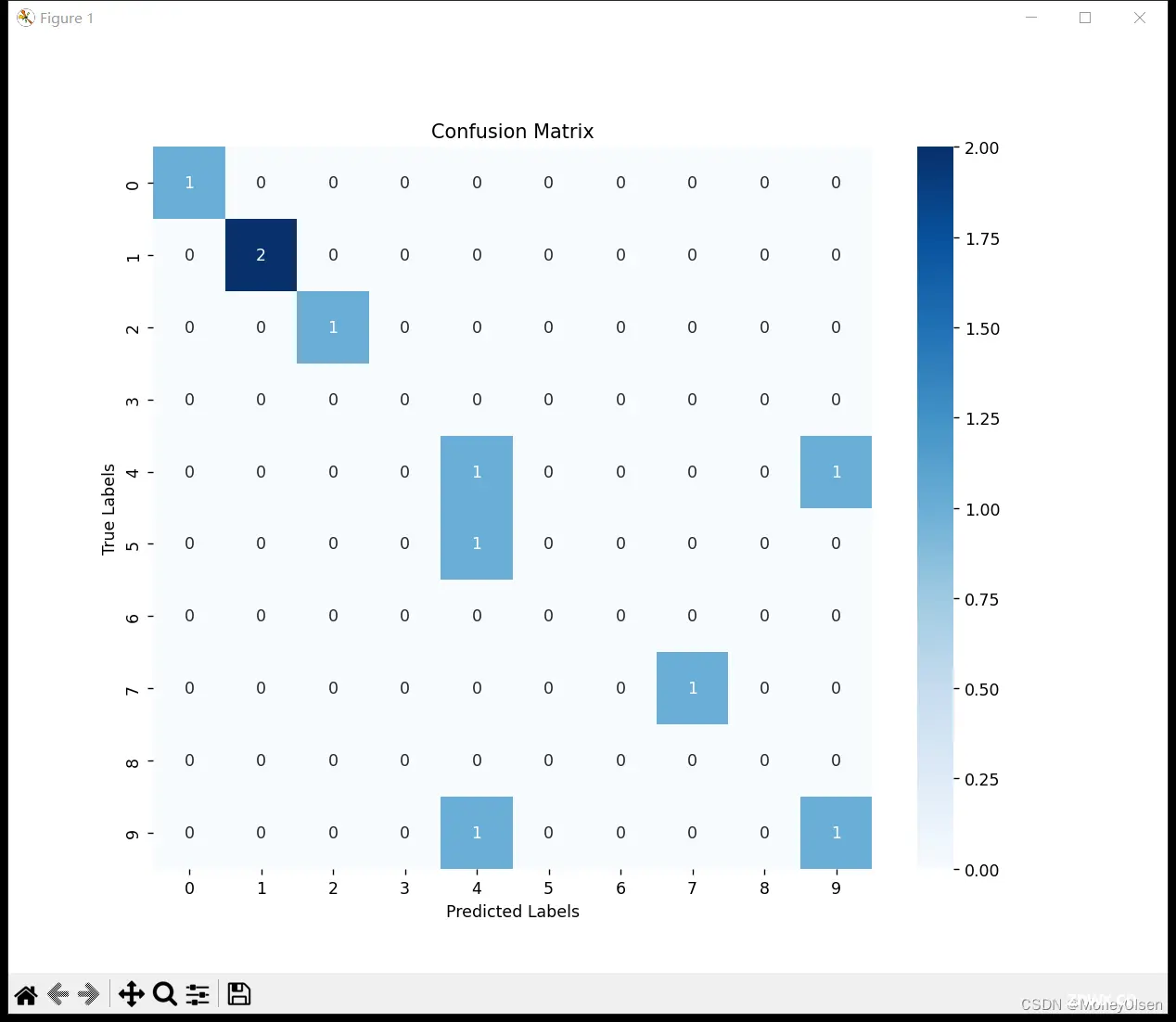
由混淆矩阵可知,对角线上的结果均为预测正确的结果。预测错误的结果有以下3个情况:5被预测为4、4被预测为9、9被预测为4。由此可知,5和4、4和9之间的手写数据集容易被误判。
2:第三部分(BP神经网络对大规模手写数字数据集进行识别和预测)
【数据集】
在本部分中,只需要修改csv文件路径即可,因此不再赘述各部分操作。训练集和测试集路径的修改如下表所示。
| 训练集路径
|
| training_data_file = open(r"C:\Users\86158\Desktop\mnist_train.csv")
|
| 测试集路径
|
| test_data_file = open(r"C:\Users\86158\Desktop\mnist_test.csv")
|
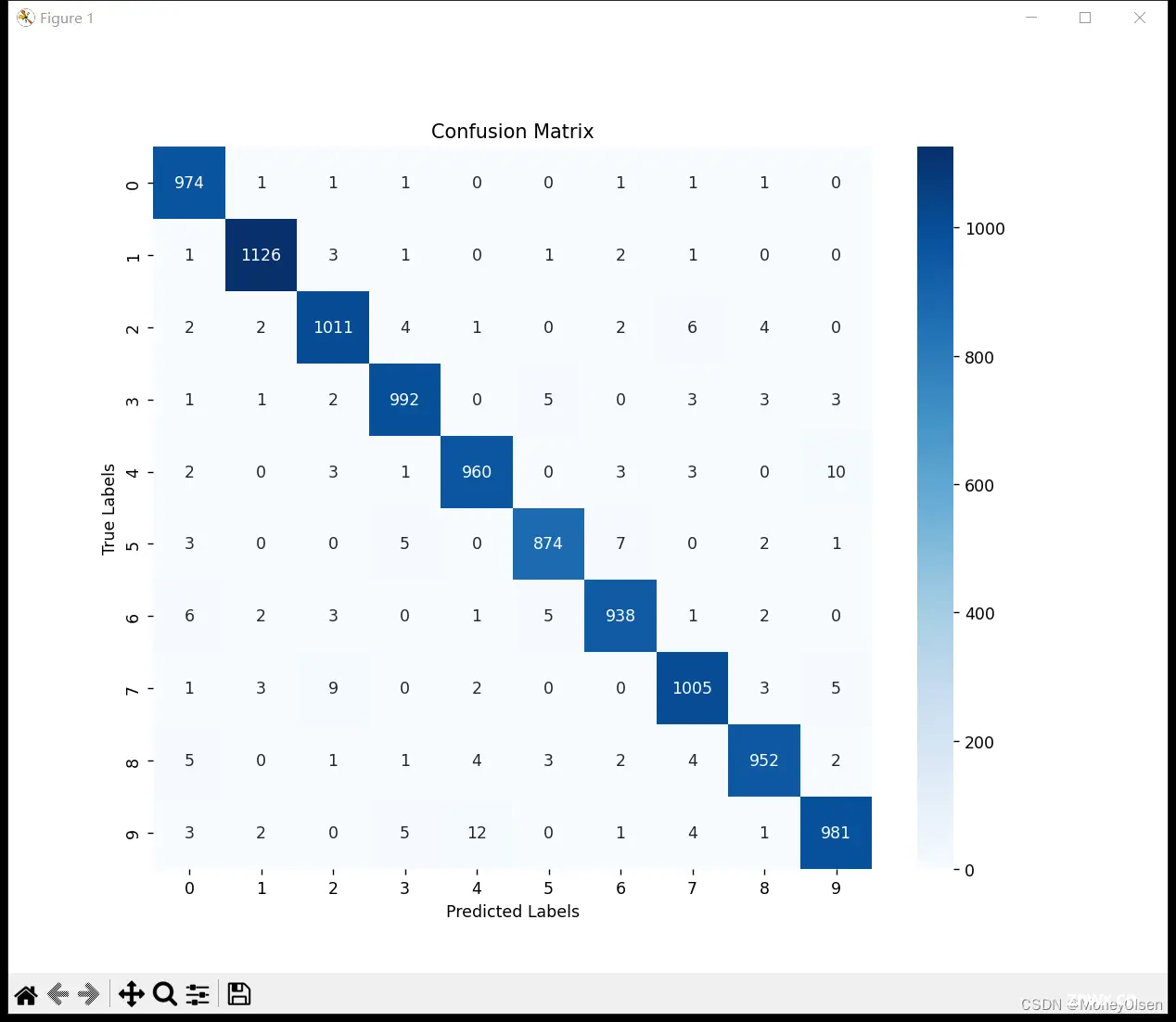
【混淆矩阵】
基于mnist_test.csv文件的测试集数据进行预测,预测的混淆矩阵结果如下图所示。可以发现大部分数据都预测正确,位于混淆矩阵的主对角线上,部分数据存在预测错误的情况。真实值标签预测错误分类不小于5个的有:2=>7、3=>5、4=>9、5=>3、5=>6、6=>0、6=>5、7=>2、7=>9、8=>0、9=>4。
【准确率】
如下图所示,计算的模型分类准确率为98.13%。

整体来说,基于BP神经网络的mnist手写数字数据集分类具有较好的结果,模型的准确度基本达到分类任务的要求。
四、遇到的问题和解决方法
问题1:一开始的混淆矩阵输出错误,无法显示正确的标签值。错误的结果如下图所示。

解决1:上面的情况是由于向confusion_matrix只传入了真实标签集合和预测标签集合,而测试集中没有完全出现0~9这10个数字的数据。因此,需要向confusion_matrix额外传入数据集可能的分类结果集合all_labels。关键代码如下表所示:
| # 生成混淆矩阵
all_labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
cm = confusion_matrix(actual_labels, predicted_labels, labels=all_labels)
# 设置图像大小
plt.figure(figsize=(10, 10))
# 创建热图
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=all_labels, yticklabels=all_labels)
|
五、实验讨论
1:学习率对输出结果的影响
【讨论1】
使用mnist小样本数据集和第二部分实验的代码,固定输入节点数为784、隐藏层节点数为200、输出节点数为10。由学习速率的变化所引起的模型分类准确率的变化,如下表所示。
| 测试编号
| 学习速率
| 模型分类准确率
|
| 1
| 0.01
| 0.6
|
| 2
| 0.05
| 0.7
|
| 3
| 0.1
| 0.7
|
| 4
| 0.5
| 0.7
|

【测试编号1的输出】
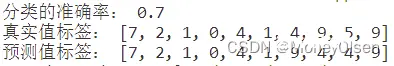
【测试编号2的输出】
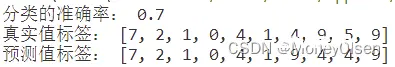
【测试编号3的输出】
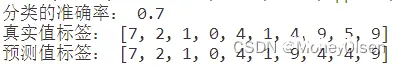
【测试编号4的输出】
【讨论2】
使用鸢尾数据集和第一部分实验的代码,固定隐藏层1点数为10、隐藏层2点数为10、最大迭代次数为1000。由初始学习速率的变化所引起的模型分类准确率的变化,如下表所示。
| 测试编号
| 初始学习速率
| 模型分类准确率
|
| 1
| 0.0001
| 0.62
|
| 2
| 0.0005
| 0.93
|
| 3
| 0.001
| 0.98
|
| 4
| 0.002
| 0.96
|
| 5
| 0.005
| 0.96
|

【测试编号1的输出】

【测试编号2的输出】
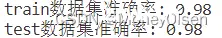
【测试编号3的输出】

【测试编号4的输出】

【测试编号5的输出】
【总结】
在其他参数不变的情况下,随着学习速率的上升,训练集的准确率不断上升,而测试集的准确率先上升后下降。这表明,学习速率会影响训练集的收敛速度和准确率,并且当学习速率过大时会产生过拟合现象,使得模型在测试集上的表现效果较差。
2:隐层神经元对输出结果的影响
【讨论1】
使用mnist小样本数据集和第二部分实验的代码,固定输入节点数为784、学习速率为0.1、输出节点数为10。由隐藏层神经元的变化所引起的模型分类准确率的变化,如下表所示。
| 测试编号
| 隐藏层神经元数
| 模型分类准确率
|
| 1
| 10
| 0.6
|
| 2
| 40
| 0.6
|
| 3
| 60
| 0.7
|
| 4
| 100
| 0.7
|
| 5
| 200
| 0.7
|
| 6
| 1000
| 0.7
|

【测试编号1的输出】
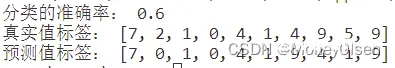
【测试编号2的输出】
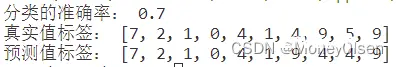
【测试编号3的输出】
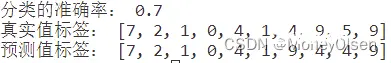
【测试编号4的输出】
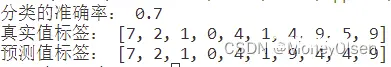
【测试编号5的输出】
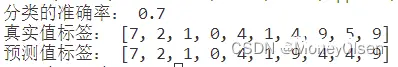
【测试编号6的输出】
【讨论2】
使用鸢尾数据集和第一部分实验的代码,固定初始学习速率为0.001、最大迭代次数为500。由隐藏层神经元的变化所引起的模型分类准确率的变化,如下表所示。
| 测试编号
| 隐藏层数
| 各层的神经元数
| 模型分类准确率
|
| 1
| 1
| 5
| 0.89
|
| 2
| 2
| 5,5
| 0.80
|
| 3
| 1
| 10
| 0.93
|
| 4
| 2
| 10,10
| 0.96
|
| 5
| 1
| 20
| 0.89
|

【测试编号1的输出】

【测试编号2的输出】

【测试编号3的输出】

【测试编号4的输出】

【测试编号5的输出】
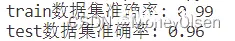
【测试编号6的输出】
【总结】
根据上述讨论可知,过多或过少的神经元都可能不利于模型的训练和性能。隐藏层神经元在神经网络中的影响主要分为以下几点:
(1)捕捉数据复杂性的能力
隐层神经元的数量和层数可以显著影响网络的能力来捕捉数据中的复杂关系和模式。较多的神经元可以提供更强的模型容量,允许网络学习更复杂的函数映射。
(2)过拟合风险
如果隐层神经元过多,可能会导致模型在训练数据上过于完美的拟合,从而降低了模型的泛化能力,即在新数据集上的表现性能不好。
(3)计算成本
更多的隐层神经元需要更多的参数来训练,会增加模型的计算负担,并可能需要更复杂的算法来避免训练中的梯度问题(例如梯度消失或爆炸)。
(4)收敛速度
神经元数量的增加可能会影响梯度下降的速度和稳定性,进而影响模型的收敛速度。
(5)信息丢失与重构
每一层的隐层神经元都在尝试从前一层中提取信息并向下一层传递。如果隐层神经元太少,可能会造成信息的丢失;如果神经元太多,则可能会学习到数据中的噪声。
3:在手写数字的识别和预测中,大样本数据集和小样本数据集的差异
(1)泛化能力
大样本数据集:通常能更好地代表问题的整体分布,帮助模型学习更通用的规律,提高模型在未知数据上的泛化能力。
小样本数据集:可能不足以捕捉数据的所有特征和变化,容易导致模型过拟合,即模型在训练数据上表现良好但在新数据上表现不佳。
(2)训练时间
大样本数据集:模型需要处理更多的数据,会需要更长的时间来训练模型。
小样本数据集:数据量较少,训练时间较短。
(3)性能和准确度
大样本数据集:由于数据量大,模型的性能和准确度通常会更高。
小样本数据集:可能因为数据量不足而难以达到高准确度,特别是在数据分布非常多样化的任务中。
(4)数据多样性和覆盖范围
大样本数据集:通常能覆盖更广泛的样本多样性,包括各种不同的手写风格和变形。
小样本数据集:可能缺乏多样性,限制了模型学习数据的全貌。
六、实验总结
1:BP神经网络是一个前向多层网络,利用误差反向传播算法对网络进行训练。BP神经网络的结构由输入层、隐藏层和输出层构成,结构简单、可塑性强。
2:输入层的节点只起到缓冲器的作用,负责把网络的输入数据传递给第一隐含层,因而各节点之间没有传递函数的功能。BP神经网络的上下层之间实现全连接,而每层神经元之间无连接。
七、程序源代码
1:第一部分
| import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neural_network import MLPClassifier
################# 1:加载和预处理数据 #################
# 加载数据
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
df = pd.read_csv(url, header=None)
df.columns = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width', 'Species']
# 提取特征和标签
X = df.iloc[:, 0:4].values
y = df.iloc[:, 4].values
# 编码标签
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 特征缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
################# 2:数据可视化和分析 #################
# 使用Seaborn对特征进行对比
sns.pairplot(df, hue='Species', vars=df.columns[0:4])
plt.show()
# 特征列表
features = df.columns[:4]
# 创建直方图
for feature in features:
plt.figure()
sns.histplot(df[feature], kde=True)
plt.title(f'Distribution of { feature}')
plt.show()
################# 3:构建神经网络模型 #################
# 创建神经网络模型————多层感知器分类器(Multilayer Perceptron Classifier)
model = MLPClassifier(hidden_layer_sizes=(10, 10), max_iter=1000, learning_rate_init=0.001)
################# 4:训练模型 #################
# 训练模型
model.fit(X_train, y_train)
################# 5:评估模型 #################
# 评估模型
train_accuracy = model.score(X_train, y_train)
print(f"train数据集准确率: { train_accuracy:.2f}")
test_accuracy = model.score(X_test, y_test)
print(f"test数据集准确率: { test_accuracy:.2f}")
|
2:第二部分
| import numpy as np
import scipy.special as S
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
import random
class neuralNetwork:
#初始化神经网络,构造函数
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
#设置每个输入、隐藏、输出层中的节点数
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#链接权重矩阵,wih和who
self.wih = np.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))
self.who = np.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes))
#学习率
self.lr = learningrate
#创建激活函数(函数的另一种定义方法,这样以后可以直接调用)
self.activation_function = lambda x: S.expit(x)
#训练神经网络
def train(self, inputs_list, targets_list):
#将输入列表转换成二维数组
inputs = np.array(inputs_list, ndmin = 2).T
targets = np.array(targets_list, ndmin = 2).T
#将输入信号计算到隐藏层
hidden_inputs = np.dot(self.wih, inputs)
#计算隐藏层中输出的信号(使用激活函数计算)
hidden_outputs = self.activation_function(hidden_inputs)
#将传输的信号计算到输出层
final_inputs = np.dot(self.who, hidden_outputs)
#计算输出层中输出的信号(使用激活函数)
final_outputs = self.activation_function(final_inputs)
#计算输出层的误差:(target - actual)(预期目标输出值-实际计算得到的输出值)
output_errors = targets - final_outputs
#隐藏层的误差:是输出层误差按权重分割,在隐藏节点上重新组合
hidden_errors = np.dot(self.who.T, output_errors*final_outputs*(1.0 - final_outputs))
#反向传播,更新各层权重
#更新隐层和输出层之间的权重
self.who += self.lr*np.dot((output_errors*final_outputs*(1.0 - final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr*np.dot((hidden_errors*hidden_outputs*(1.0 - hidden_outputs)), np.transpose(inputs))
def query(self, inputs_list):
#将输入列表转换成二维数组
inputs = np.array(inputs_list, ndmin = 2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
# 设置输入、隐藏、输出层中的节点数,和学习率
input_nodes = 784 # 根据一开始的图像特征数决定
hidden_nodes = 200
output_nodes = 10 # 根据最后的分类决定
learning_rate = 0.1
# 创建神经网络实例
n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
# 加载MNIST训练数据集
training_data_file = open(r"C:\Users\86158\Desktop\mnist_train_100.csv")
training_data_list = training_data_file.readlines()
training_data_file.close()
# 随机选择一个样本
random_index = random.randint(0, len(training_data_list) - 1)
all_values = training_data_list[random_index].split(',')
image_array = np.asfarray(all_values[1:]).reshape((28,28))
# 可视化选中的样本
plt.imshow(image_array, cmap='Greys', interpolation='None')
plt.title("Label: " + all_values[0])
plt.show()
# 训练神经网络
epochs = 50
for e in range(epochs):
for record in training_data_list:
all_values = record.split(',')
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
targets = np.zeros(output_nodes) + 0.01
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
# 加载MNIST测试数据集
test_data_file = open(r"C:\Users\86158\Desktop\mnist_test_10.csv")
test_data_list = test_data_file.readlines()
test_data_file.close()
# 预测测试集
predicted_labels = []
actual_labels = []
cnt = 0
for record in test_data_list:
all_values = record.split(',')
actual_label = int(all_values[0])
actual_labels.append(actual_label)
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
outputs = n.query(inputs)
predicted_label = np.argmax(outputs)
predicted_labels.append(predicted_label)
# 计算准确率
for i in range(len(predicted_labels)):
if actual_labels[i] == predicted_labels[i]:
cnt += 1
accuracy = float(cnt / len(predicted_labels))
print("分类的准确率:",accuracy)
# 打印标签
print("真实值标签:",actual_labels)
print("预测值标签:",predicted_labels)
# 生成混淆矩阵
all_labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
cm = confusion_matrix(actual_labels, predicted_labels, labels=all_labels)
# 设置图像大小
plt.figure(figsize=(10, 10))
# 创建热图
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=all_labels, yticklabels=all_labels)
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.show()
|
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。