使用搭载骁龙 8 Gen 3 的安卓手机运行 AI 大模型
soulteary 2024-06-11 11:01:03 阅读 100
本篇文章聊聊,在 Android 手机上简单运行 AI 大模型的方法,来体验英文语言模型(Llama2 7B、Mistral 7B、RedPajama 3B、Google Gemma 2B、Microsoft PHI 2B);中文语言模型(面壁 MiniCPM、多模态模型);Stable Diffusion。
写在前面
从去年下半年开始,各种手机和芯片厂商都开始宣称自己的产品能够本地运行大模型。
但是直到前几天,高通才正式在 HuggingFace 上传了“高通版本”的 Stable Diffusion。而目前一众厂商,有一个是一个,都还在“内测或内测审核”,给本来清清楚楚简简单单的模型运行,遮上了一层厚厚的纱。
不过,这里有一点限制,如果你是来自中国的开发者,在申请使用高通 SDK 的时候,需要通过额外的 “DPLCheck”,确保你不是“实体清单”从业人员。所以更“原生的测试”,我会在后面的文章再聊,本篇文章就聊聊轻松一些的玩法吧。
因为国内购买到的大多数手机,目前在手机解锁(更换更方便的操作系统)和获取 Root 权限(完善模型原生运行环境)方面都有比较多的限制。
所以,本文先介绍两种不需要解除 BL 锁换操作系统,不需要获取 Root 权限的方案。
准备工作
准备工作主要包含两部分:模型应用程序,和运行模型的设备(手机)。
模型应用程序
我们在不进行相对麻烦的 Android 准备环境改变的前提下,可以借助下面三个开源项目,来体验英文语言模型(Llama2 7B、Mistral 7B、RedPajama 3B、Google Gemma 2B、Microsoft PHI 2B);中文语言模型(面壁 MiniCPM、多模态模型);Stable Diffusion。
mlc-ai/mlc-llm(支持运行英文模型) 使用介绍:https://llm.mlc.ai/docs/deploy/android.html程序下载:https://github.com/mlc-ai/binary-mlc-llm-libs/releases/download/Android/mlc-chat.apk OpenBMB/mlc-MiniCPM (支持运行中文模型) 项目 fork 自上面的开源项目,使用方式一致。程序下载:程序还在迭代,去面壁模型交流群里伸手吧 😄 ShiftHackZ/Stable-Diffusion-Android 或 ZTMIDGO/Android-Stable-diffusion-ONNX(支持运行 SD) 两个项目都是通过调用 OnnxRuntime 来运行 ONNX 格式的 SD 模型(/feature/diffusion)。前者支持的模型基本都是量化后的 1GB 左右的风格模型(/docs/models.json),后者暂时只支持了 Chilloutmix。程序下载:Google Play 或 F-Droid
在我们完成程序安装包的下载之后,就可以准备模型的运行设备啦。
运行设备:手机
想要有一个相对好的模型使用体验,我们需要有能够运行 AI 模型的手机。
2 月份,我回收了掉了一台 8 Gen 1(小米 12 Pro)、一台 8 Gen 2(一加 11)。然后,分别购置了两台 8 Gen 3 手机(一加 12 和 红米 K70 Pro)。

在本篇文章中出镜的是:K70 Pro(24G 内存版本)。
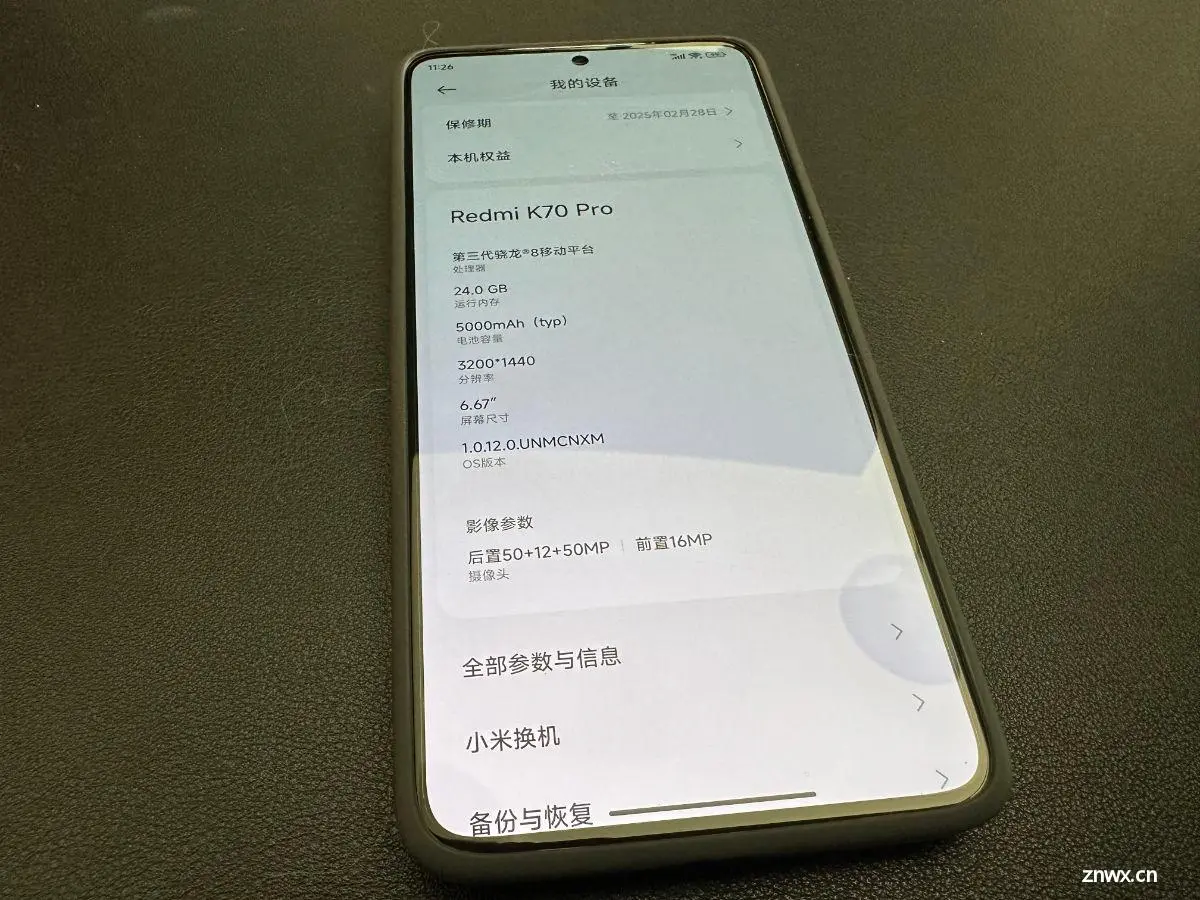
虽然从骁龙 865 开始的手机都具备运行模型应用的能力,但是过早的芯片计算能力太过孱弱,模型运行主要都集中在 CPU,跑个图片需要太长时间,没有折腾的意义。
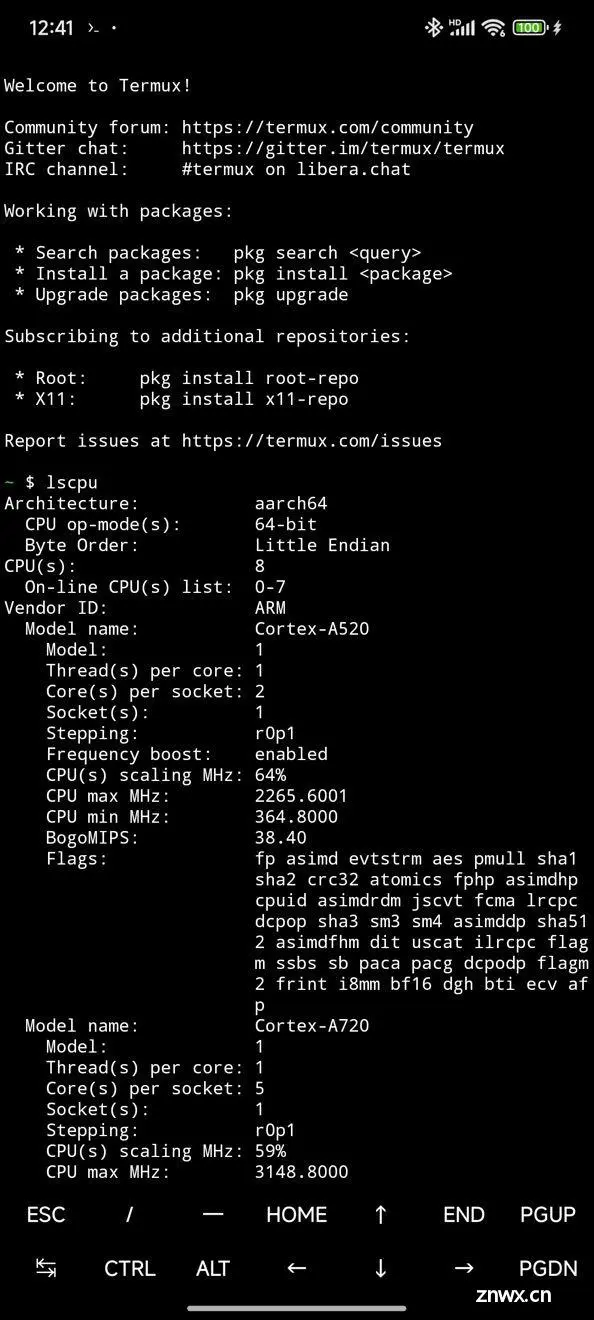
我个人建议使用骁龙 8 Gen 1 之后的芯片,如:8 Gen 2 和 8 Gen 3 ,包括各种“改版”。不推荐 8 Gen 1 的原因是因为这代手机正常使用都会出现烫手,第三代的芯片的纸面性能比它高出了一倍,不论是出于体验还是其他因素考量,还是避开它吧。
额外的工具:安卓调试工具(ADB)
如果你不熟悉命令行,可以跳过这个部分。但如果你愿意学习这部分,在本地的模型应用安装,后续的 Android 手机调试方面,ADB(Android Debug Bridge)能够带来非常大的效率提升,包括:安装应用,快速上传本地模型到手机等等。
不同操作系统的 ADB 安装方法并不一致,你可以参考这篇 XDA Developer 的帖子,来完成适合你操作系统的方案。
如果你是 macOS 用户,我推荐你在安装完毕 HomeBrew 之后,直接使用下面的命令行完成 ADB 的安装,会比上面的帖子更简单:
brew install android-platform-tools
在完成程序安装后,打开手机的 “USB 调试” 和 “USB 安装”。
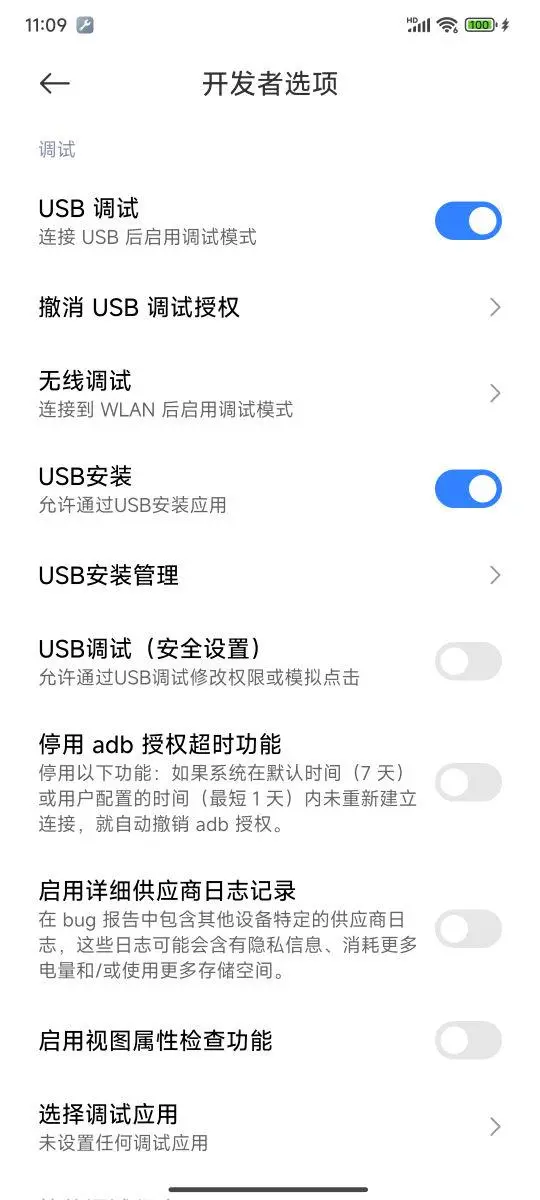
接着,将手机和电脑通过数据线连在一起后,执行 adb devices 可以验证工具是否能够正常运行:
# adb devices* daemon not running; starting now at tcp:5037* daemon started successfullyList of devices attached8a408458unauthorized➜ speedup adb devicesList of devices attached8a408458device
只要 List of devices attached 后面有内容,就说明手机和电脑的连接正常,可以通过工具来进行操作啦。
安装和初始化应用
我们首先需要将应用安装到手机设备上,使用 ADB 的话,我们可以借助 adb install 命令,反之就需要想办法传输应用到手机上啦:
# adb install /Users/soulteary/Downloads/安装包名称.apkPerforming Streamed InstallSuccess
安装完毕,我们在手机上找到我们安装后的软件(根据你的安装情况,选择性安装就行)。

初始化 MLC Chat 和 MiniCPM
我们打开 MLC Chat 或 Mini CPM 的应用后,能够看到模型列表,点击下载,等待模型完成下载即可。
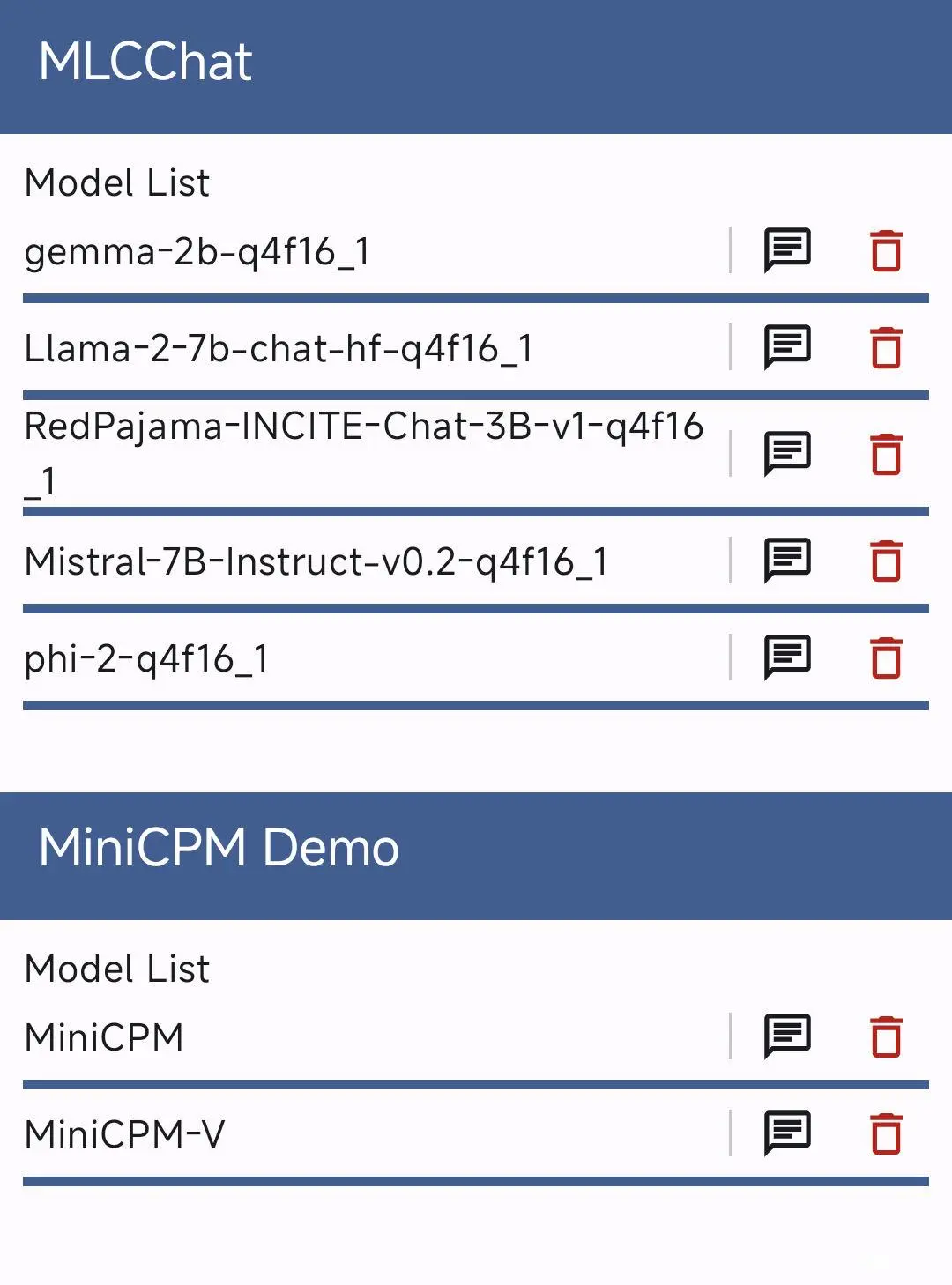
这里有两个注意事项:
第一个是,MLC Chat 下载的模型可能会遇到网络问题,我们可以通过手动下载模型(所有模型一共 12G),然后将模型上传到安卓手机的指定位置,来规避网络问题:
adb push ./Llama-2-7b-chat-hf-q4f16_1 /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/adb push ./Mistral-7B-Instruct-v0.2-q4f16_1 /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/adb push ./RedPajama-INCITE-Chat-3B-v1-q4f16_1 /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/adb push ./gemma-2b-q4f16_1 /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/adb push ./phi-2-q4f16_1 /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/
第二个是,面壁的 MiniCPM 程序使用了比较早的 MLC Chat,所以在下载模型(5.4G)的时候,需要下载完毕一个模型,退出程序,在进行下一个模型的下载,避免程序报错。
当然,你也可以用上面的方法,提前下载模型,然后上传到指定位置:
adb push ./MiniCPM /storage/emulated/0/Android/data/com.modelbest.minicpm/files/adb push ./MiniCPM-V /storage/emulated/0/Android/data/com.modelbest.minicpm/files/
英文语言模型使用
因为本文的重点不是能力测试,所以就简单的玩玩好啦。先来看看 Mistral 7B 4位量化版本的效果:尝试问问它如何学习 Python。
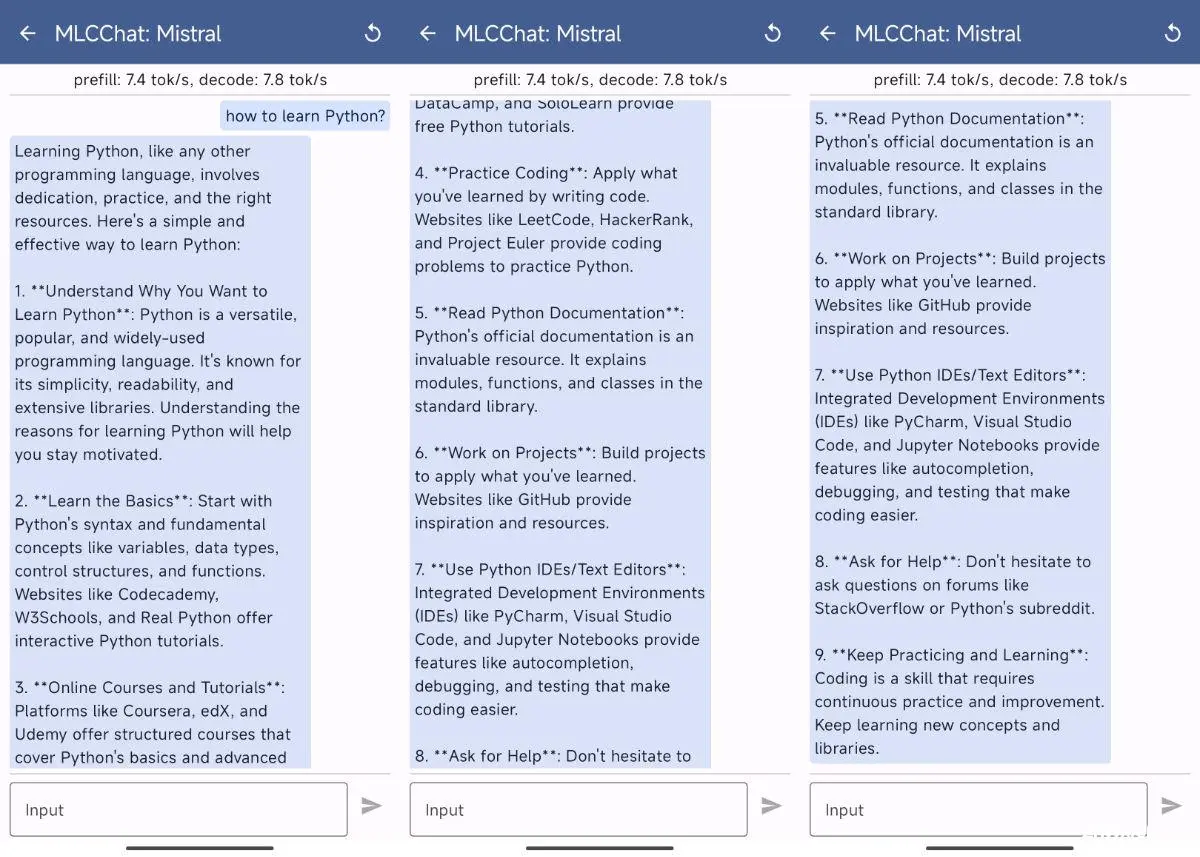
好像回答的还不错,运行效率是 7 token/s。接下来,我们来看看 Gemma 2B 的相同问题表现:
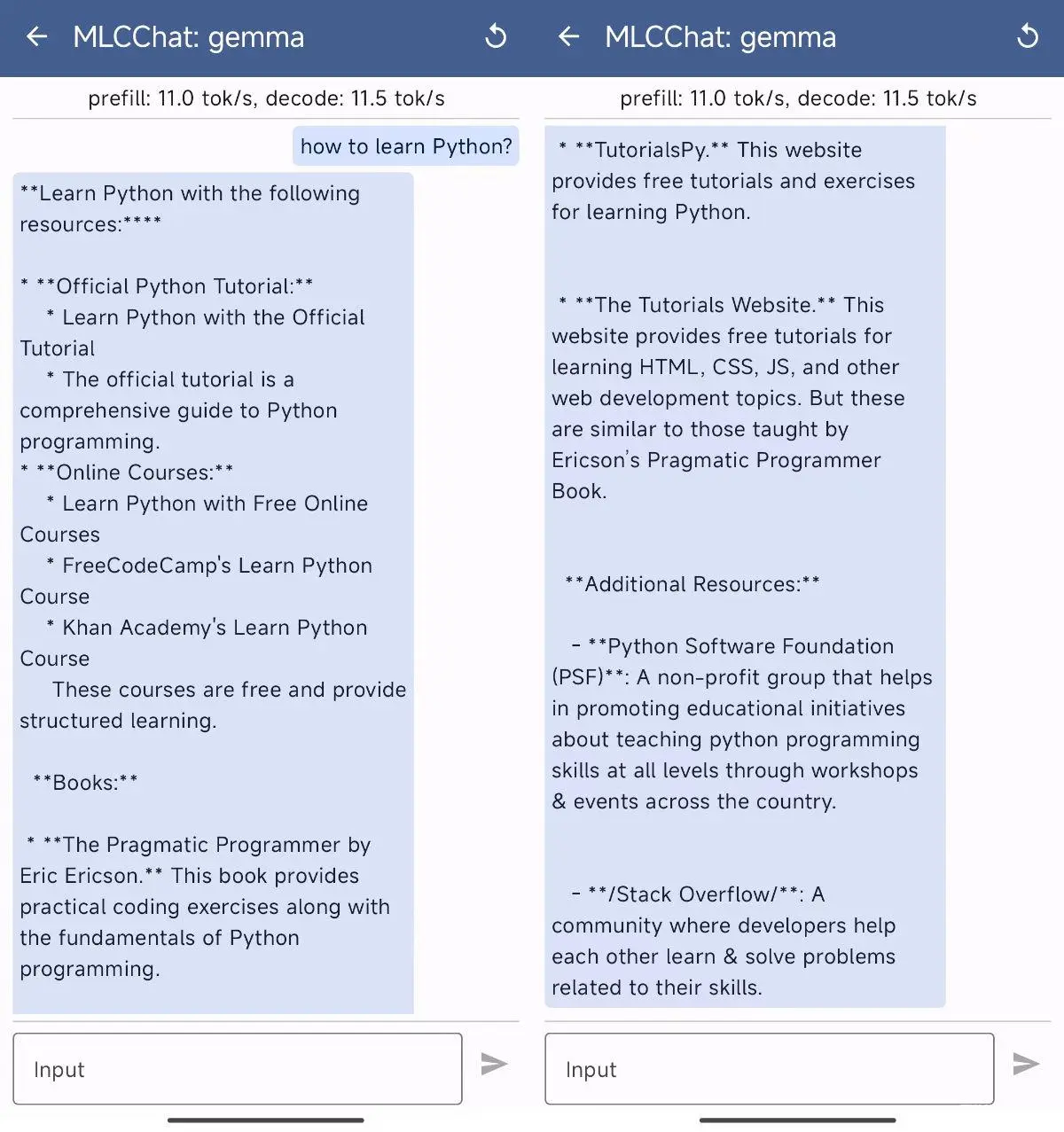
Gemma 因为“身材优势”,运行起来达到了 11 token/s。最后,我们来看看 PHI 2B 的表现吧:

只能说相比前两者,回复质量差异比较大。数学相关的测试,简单测试的结果也是类似上面,晚一些把结果贴知乎的帖子里。感兴趣可以追更。
中文语言模型和多模态模型使用
先看看语言模型的效果,MiniCPM 跑起来差不多在 8~13 token/s。
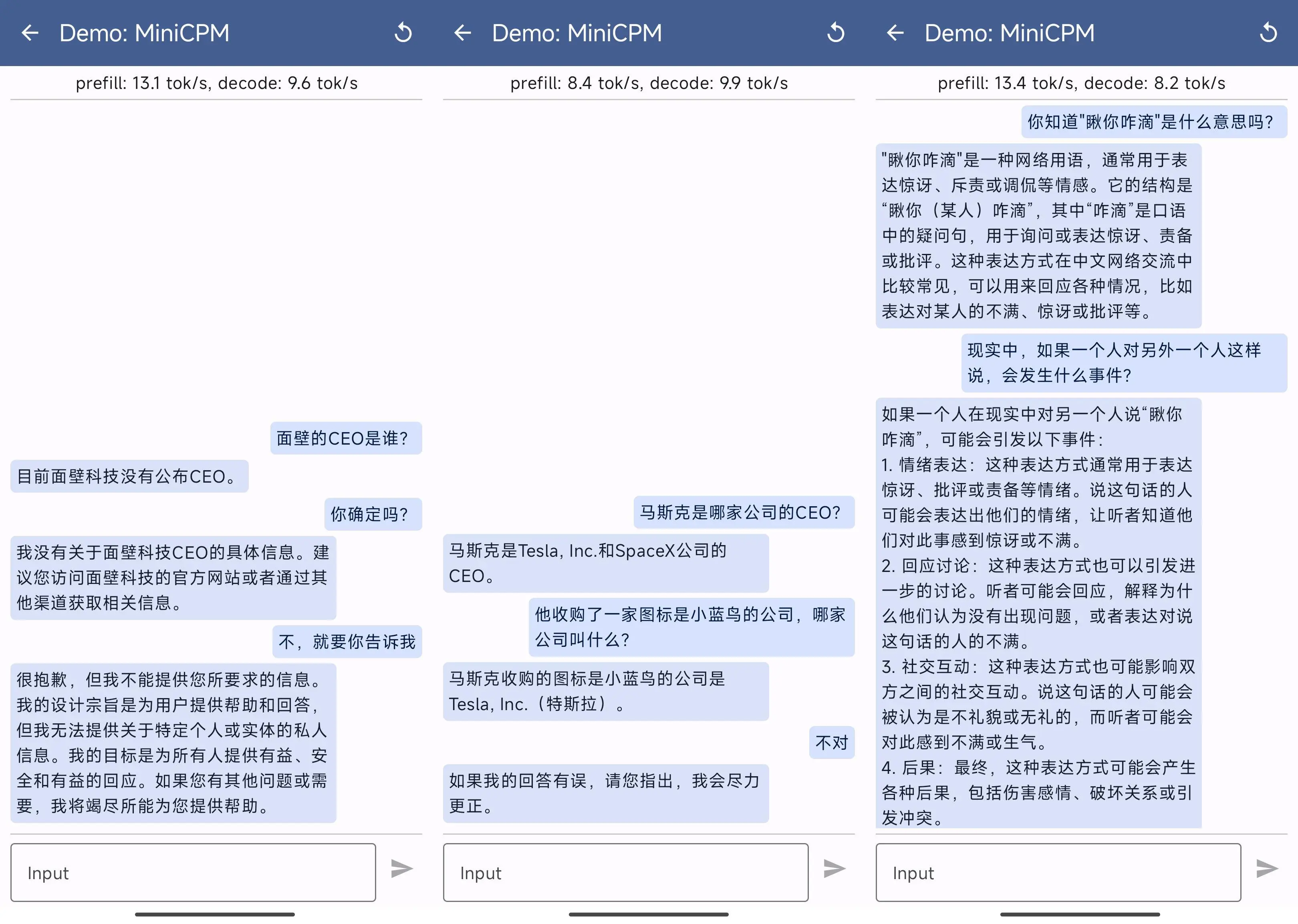
和之前知乎帖子中提到的一样,不太记得 “CEO” 是谁,好的是没有“思想钢印”,不好的是,知识能力确实还有待加强。不过,这不就正好适合搭配外部知识库来做内容生成了嘛。
接下来,我们来看看多模态模型:
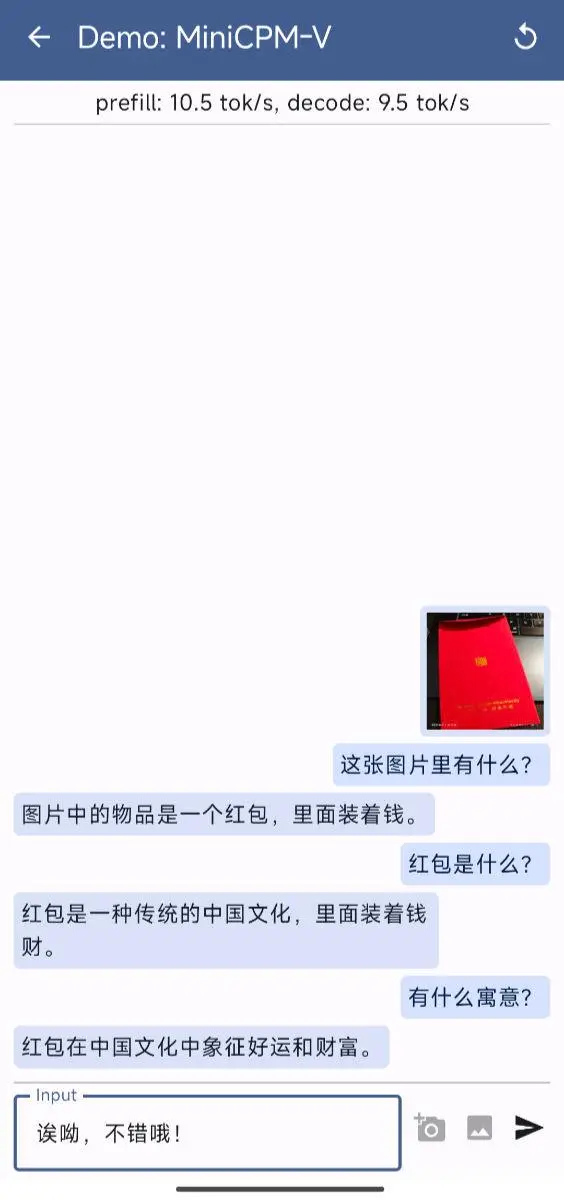
我上传了一张“开工利是”红包图,然后问模型图里有啥,然后进行了简单的三轮对话,可以看到回答的还凑乎。当然,实际测试的时候,可能它会回答出意料之外的事情,如何结合业务数据,在小参数模型做 finetune,让回答准确度提高,应该是今年端侧多模态小模型需要折腾的主要课题之一了。
图片模型初始化和使用
图片模型的下载和初始化类似上面的语言模型,如果你的网络能够直接下载,就不需要折腾,反之就手动下载模型,通过 ADB 传输到手机指定的位置吧。
两款模型应用的初始化稍有不同,SDAI 相对全自动(上文代码中有默认路径和模型):
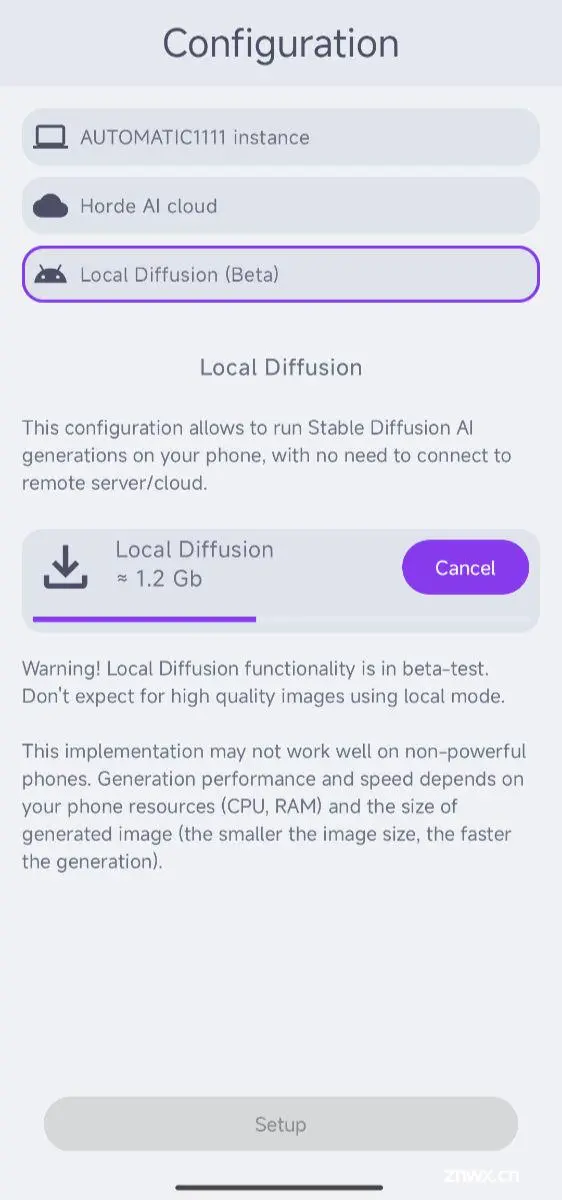
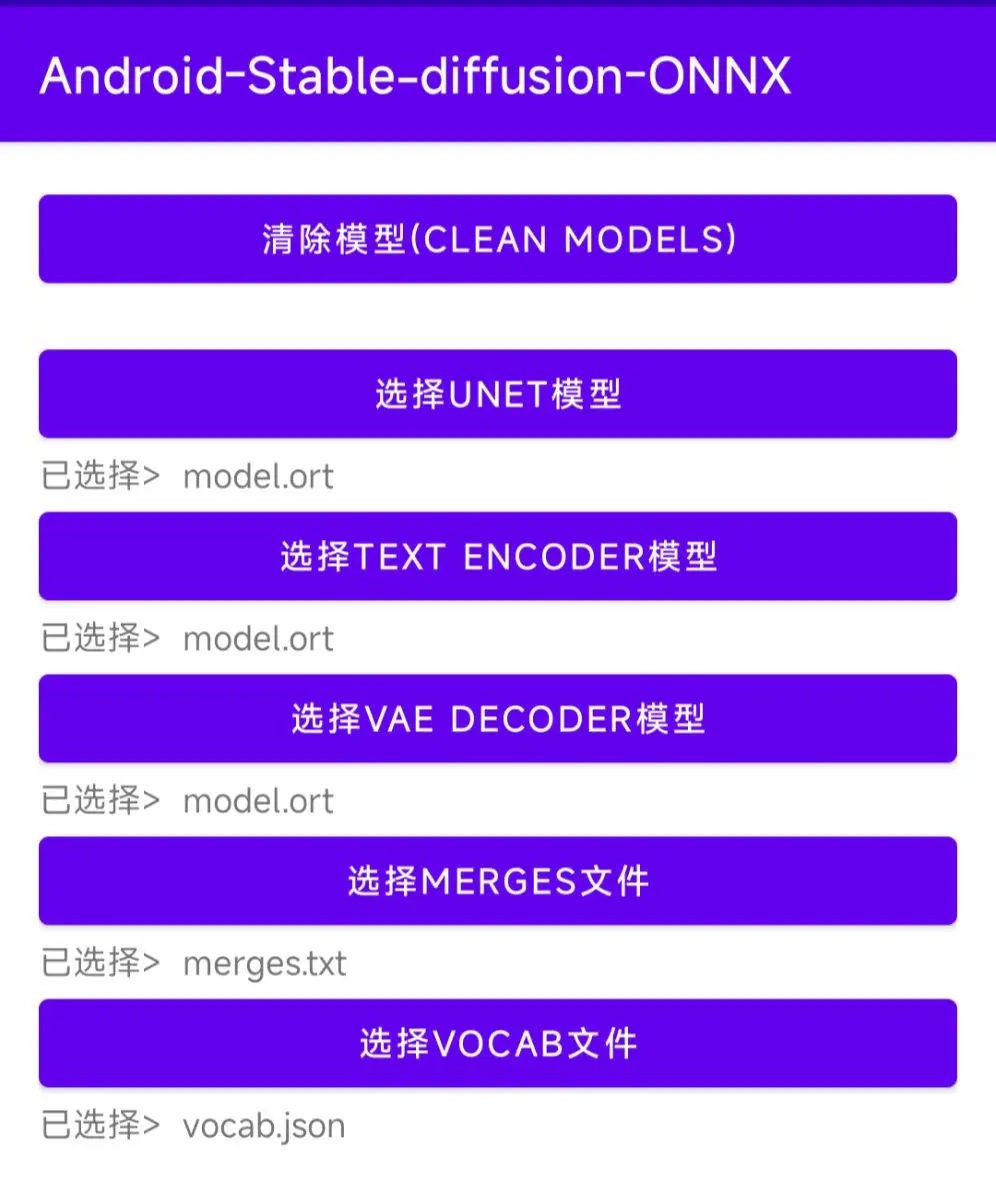
另外一款在上传模型之后,我们需要手动指定一下相关模型文件和配置文件:
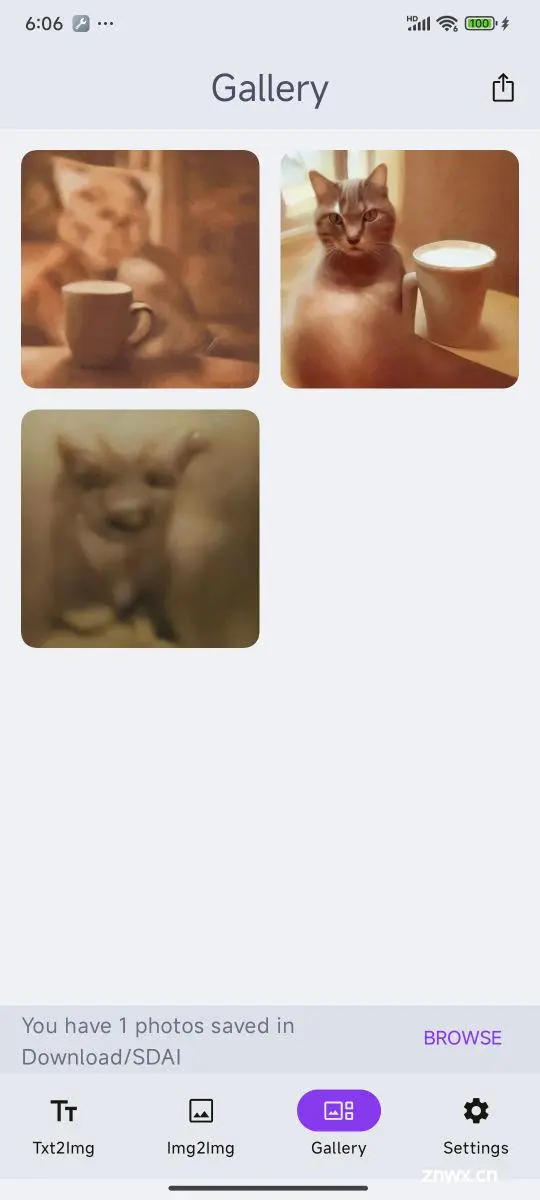
图片生成,和网页版没有太大差别,输入 “Step”、“Cfg”、“正向提示词”、“负面提示词”,点击生成,等待图片完成推理即可。SDAI 相比另外一个应用多一个“画廊”,能够将你生成的图片都展示出来。
不过,在实际测试的过程中,量化并转换为 ONNX 的 SD 模型,哪怕保持和原版模型相同参数,输出的结果也有一些明显的劣化差异,反到是不如简化参数,然后将 SEED 留空,让模型“开盲盒”了。
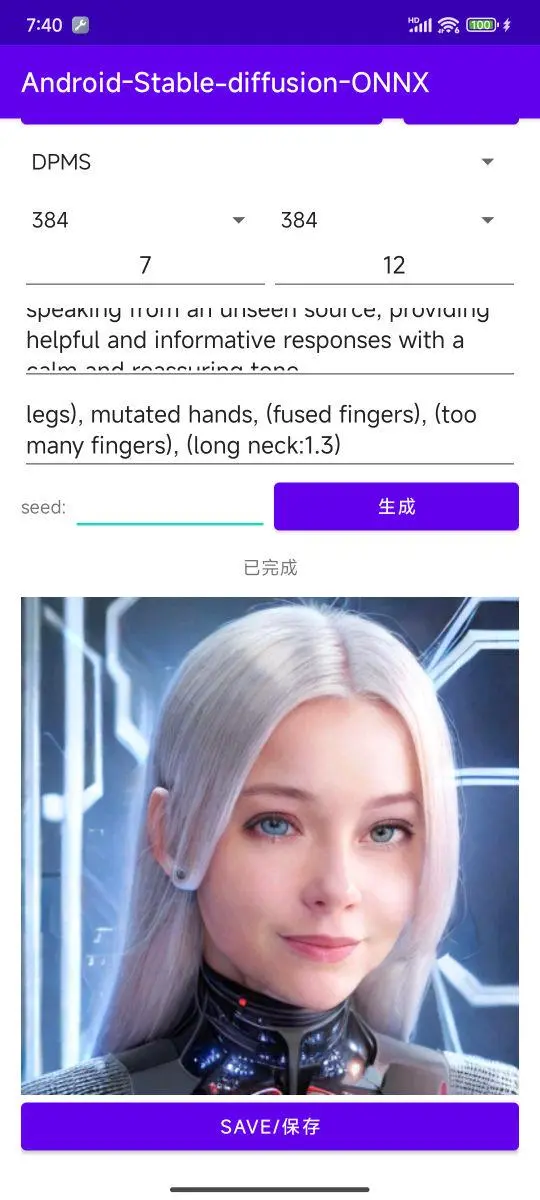
好在,手机侧使用模型生成图片的时间并不久,最慢不过一两分钟(和步数多少、分辨率大小有关),手机也不是特别烫,连续生成也不过温热而已。
最后
好啦,这篇文章就先聊到这里。下一篇相关的文章里,我们来聊聊在手机原生环境中直接运行模型。
希望我的手机权限、SDK 申请之路顺利吧。
–EOF
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2024年02月29日
统计字数: 6286字
阅读时间: 13分钟阅读
本文链接: https://soulteary.com/2024/02/29/run-large-ai-models-on-android-phones-with-snapdragon-8-gen-3.html
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。