Google AI (Gemini)接入指南
子洋丶 2024-06-25 11:01:11 阅读 81
前言
在前文中,我们探讨了如何利用 AI 自动化修复 Bug 的实现思路。当时为了避免内容杂乱,我们并未深入讨论 Google AI 的接入方法,本篇我们详细了解该如何接入 Google AI。
Gemimi 介绍
Google 在 2023 年发布的 Gemini 人工智能模型旨在实现真正的通用人工智能。作为一个多模态模型,Gemini 能够跨多种模态无缝对话并提供最佳响应。它是 Google 迄今为止打造的最大、最强大的模型,能够理解我们周围的世界,处理各种类型的输入和输出,不仅限于文本,还涵盖代码、音频、图像和视频。在测试中,Gemini的性能在许多方面匹及甚至超越领域专家。
Gemini提供三个版本的人工智能模型:
Gemini Ultra:用于处理高度复杂的任务。Gemini Pro:适用于广泛的任务。Gemini Nano:特别为设备端任务设计。
最近刚宣布的 Gemini Advanced 模型目前还在内测中,需加入等待名单才能体验。尽管 Gemini Advanced 目前还不能用,不过其他三个AI模型的使用不受影响,Gemini 的 API 接口目前开放免费调用。
申请 API Key
首先进行 Google AI Studio 创建一个 API Key
Google AI Studio 地址:https://aistudio.google.com/app/apikey
首先点击左侧菜单中的 Get API key然后点击页面中的 Create API key 按钮
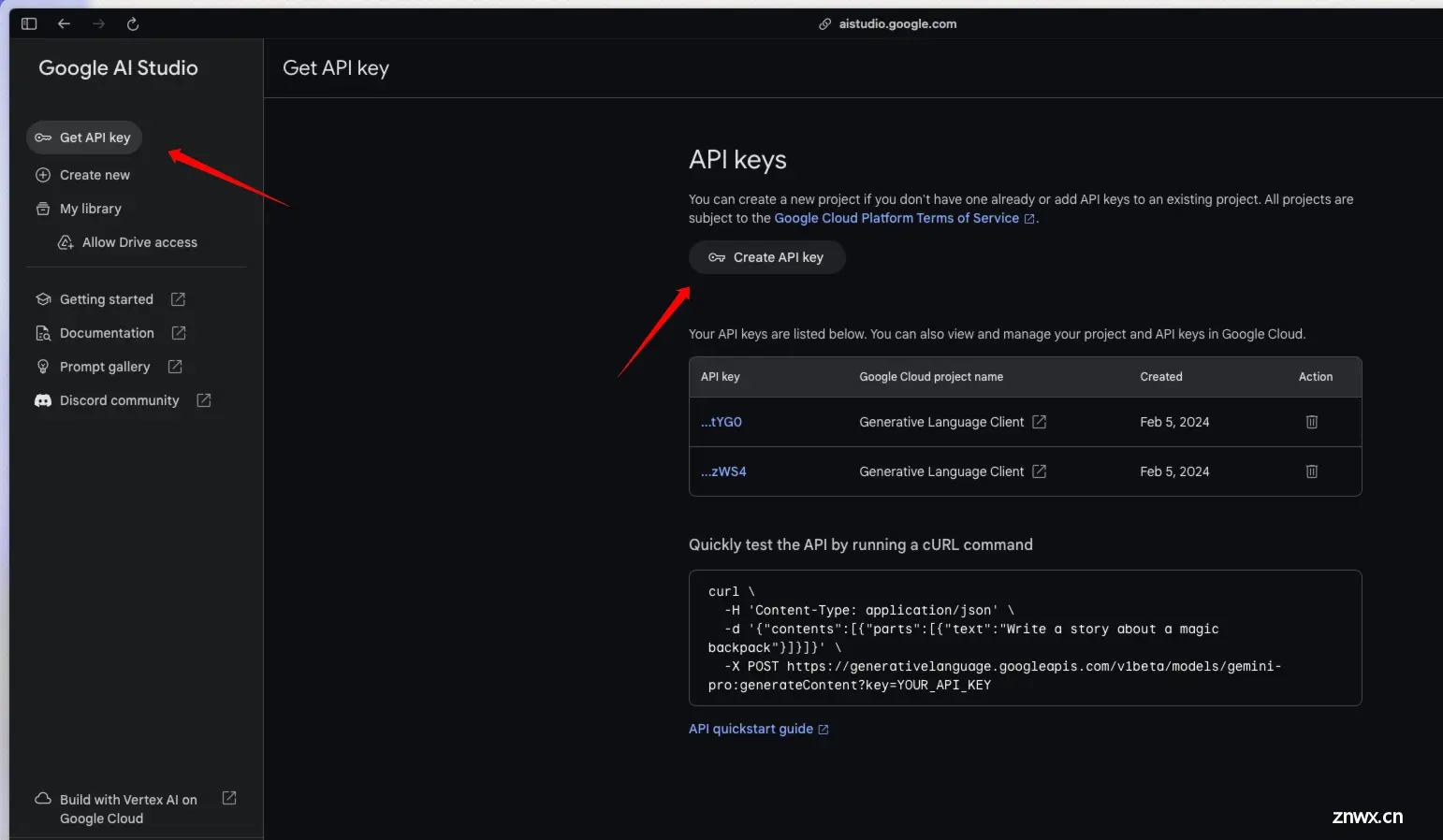
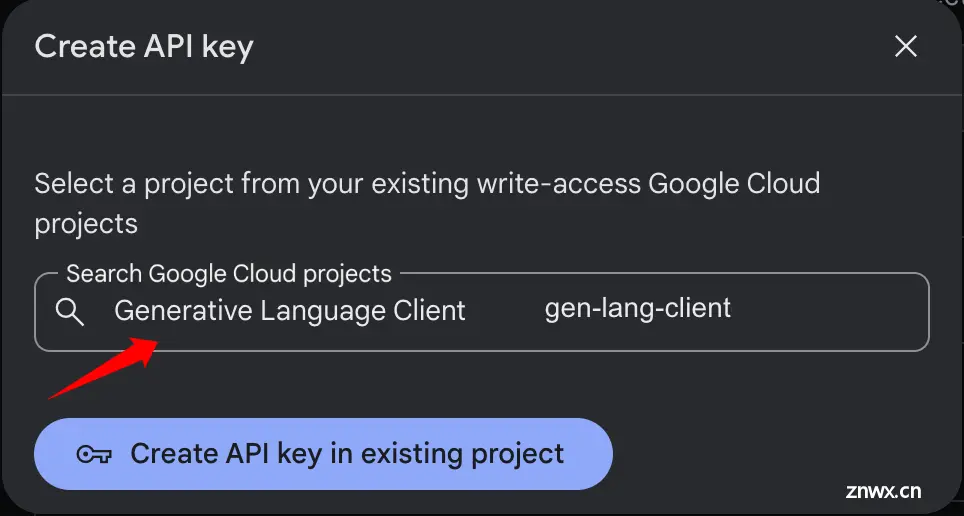
点击创建按钮后会出现一个弹窗,选择一个 Google Cloud Project, 这里应该会默认有一个 Generative Language Client, 如果有的话直接选择就可以了,即便没有也可以上 Google Cloud 创建一个空项目就可以。选择后点击 Create API key in existing project 创建 API Key
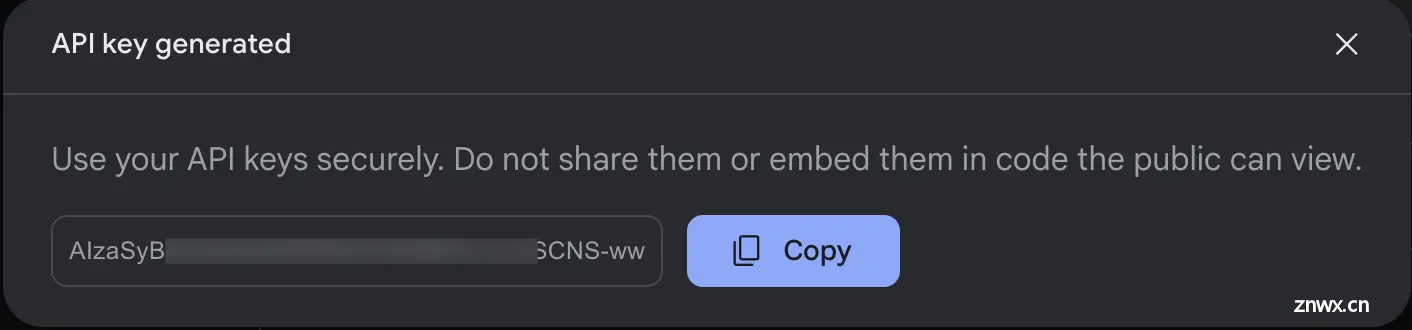
生成之后会弹出一个弹窗,我们复制出这个 api key 后续备用即可额外说一点,如果这个 api key 忘记了,也可以在页面点击那条 Api key 再次查看
Gemini API
Gemini API 提供了多个语言的 SDK,例如:Python、Go、Node.js 等等,此外允许 API 调用者直接通过接口地址进行调用。
设置
安装Python SDK
包中包含 Gemini API 的 Python SDK google-generativeai。使用 pip 安装依赖项:
pip install -q -U google-generativeai
导入包
在使用时导入 google.generativeai 这个包即可
import google.generativeai as genai
设置 API 密钥
这里就用到我们上文中创建的 API Key 了,设置秘钥有两种方式:
将密钥放入GOOGLE_API_KEY环境变量中(SDK 会自动从那里获取)。将密钥传递给genai.configure(api_key=...)
# 方式一:将 GOOGLE_API_KEY 设置环境变量(或者直接加入系统变量)
import os
os.environ["GOOGLE_API_KEY"] = "<你的API Key>"
# 方式二:通过 genai.configure 设置 api Key
genai.configure(api_key=GOOGLE_API_KEY)
注意:以上两种方式只用选一种即可。
接口调用
Gemini 目前提供了三种模型,对于纯文本提示我们使用 gemini-pro 即可。
model = genai.GenerativeModel('gemini-pro')
通过 generate_content 方法,Gemini 模型能够处理包括多轮对话和跨模态输入在内的多种复杂用例。这意味着无论是单次的直接问答还是一连串的对话,或是需要对图像资料进行分析和描述,Gemini都能提供有效的输出。
为了实现基础的文本提示功能,你只需向 GenerativeModel.generate_content 方法传递一个字符串。例如,要询问生命的意义,代码将如下所示:
response = model.generate_content("什么是生命的意义?")
# 我们通过 `response.text` 可以拿到响应内容
print(response.text)
默认情况下,模型只有在完成整个内容的生成之后才会返回响应,这种方法非常适合于那些不需要即时反馈的场景。然而,在某些情况下,你可能希望能够实时地(更快的)获得模型的每个响应部分,流式传输正是设计用来满足这种需求的。
启用流式传输的方法很简单。只需在调用 generate_content 方法时添加一个 stream=True 参数。这样,你就可以在模型生成响应的同时接收到每一块内容,提供更为动态和互动的体验。
response = model.generate_content("什么是生命的意义?", stream=True)
for chunk in response:
print(chunk.text)
结语
Gemini 还支持处理图片、聊天对话等等,因为之前写工具没有涉及到,也没有详细研究,我们这里就不展开讲了,如果感兴趣可以直接前往 Google API 文档查阅,内容很详细。
相关资料
Gemini API 文档: https://ai.google.dev/docsGoogle Gemini 宣传片: https://www.youtube.com/watch?v=jV1vkHv4zq8
上一篇: 【Filmora13】懂AI的影片剪辑软件,剪映再见!让你用AI技术剪辑影片,直接AI生图、AI翻译、AI制作音乐!
下一篇: SpringAI通过Ollama连接大语言模型通义千问
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。