18_特征金字塔网络FPN结构详解
江畔柳前堤 2024-10-12 09:01:05 阅读 65
1.1 简介
在深度学习领域,尤其是计算机视觉和目标检测任务中,Feature Pyramid Networks (FPN) 是一种革命性的架构设计,它解决了多尺度特征检测和融合的关键问题。FPN最初由何凯明等人在2017年的论文《Feature Pyramid Networks for Object Detection》中提出,自那以后,它成为了许多现代目标检测框架的核心组件。
FPN的核心思想
FPN的核心思想在于构建一个特征金字塔,这个金字塔能够同时利用深度卷积网络中不同层级的特征。传统的卷积网络往往只能在某个固定的特征层级进行预测,这限制了它们对多尺度目标的有效检测。FPN通过引入自顶向下的路径和横向连接,巧妙地融合了高层的语义信息(丰富的类别信息但空间分辨率较低)与底层的空间细节信息(高分辨率但语义信息较少),从而在不同的尺度上都能实现高效且准确的目标定位。
架构特点
自顶向下的路径:FPN首先将深层(高语义级别但低分辨率)特征图通过上采样(例如双线性插值)逐级上移,使其尺寸与浅层特征图匹配。
横向连接:在每个上采样后的特征图与其对应的浅层特征图之间添加横向连接,通过1x1卷积来调整通道数,并将两者相加,以此结合深层次的语义信息与浅层次的空间细节信息。
多尺度预测:在每个融合后的特征图上都设置预测头(例如用于分类和回归的任务头),这样可以在每个层级上都对不同大小的目标进行检测,提高了对小物体检测的准确性。
应用与影响
FPN的提出显著提升了目标检测系统的性能,尤其是在处理不同尺度物体检测方面,减少了小物体的漏检率,同时保持了对大物体的高检测精度。它的有效性不仅限于目标检测,还被广泛应用于实例分割、语义分割以及其他需要多尺度特征分析的视觉任务中。
总结
FPN通过其创新的特征融合机制,为深度学习中的多尺度目标检测问题提供了一个优雅且高效的解决方案。它不仅提升了检测系统的准确性和效率,还促进了后续一系列基于特征金字塔结构的改进和发展,成为了现代计算机视觉架构设计中不可或缺的一部分。

1.2 FPN的原理
原理
核心挑战:在目标检测任务中,目标可能出现在图像的不同位置和不同尺度上。传统方法如图像金字塔或单独使用高层(高语义但低分辨率)或低层(高分辨率但低语义)特征图往往不能有效同时解决多尺度问题。
解决方案:FPN通过创建一个特征金字塔来合并不同尺度的特征,这个金字塔包含了从细粒度到粗粒度的所有尺度信息。它利用了骨干网络(如ResNet、VGG等)生成的多层特征图,通过自顶向下和横向连接的方式融合这些特征。
流程
自下而上(Bottom-Up Pathway):
输入图像通过骨干网络(如ResNet的C1至C5层),每经过一层卷积和池化,特征图的尺寸减小(分辨率降低),但通道数(特征维度)增加。这个过程提取了从低级到高级的特征,高级特征富含语义信息但空间分辨率较低。
构建顶层特征:
从骨干网络的最后一层特征(例如C5)开始,使用1x1卷积来减少通道数,生成一个高层次特征图,标记为P5。这个操作既降低了计算复杂度,也为后续上采样操作做准备。
自顶向下路径(Top-Down Pathway):
对P5进行上采样(常用双线性插值或最近邻插值),使其尺寸与下一层特征图(例如C4)匹配,然后通过横向连接与C4特征图相加。这里的横向连接先用1x1卷积调整C4的通道数,确保与上采样后的P5具有相同数量的通道,之后相加得到新的特征图P4。这个过程递归进行,直到覆盖所有需要的尺度。
特征融合与输出:
在每个融合后的特征图(P2至P5)上,可以附加额外的卷积层来生成最终的预测,比如边界框的回归和类别的分类得分。这样,FPN能够在每个尺度上直接预测目标,适应不同大小的目标检测。
优势
多尺度特征融合:通过自顶向下和横向连接,FPN能够在不同尺度上综合语义信息和空间细节,提高了对小目标的检测能力。高效计算:相比图像金字塔,FPN复用了同一输入图像的特征,避免了多次运行骨干网络的高昂计算成本。灵活性:FPN结构易于集成到现有的目标检测框架中,如Faster R-CNN、Mask R-CNN等,提升了整体性能。
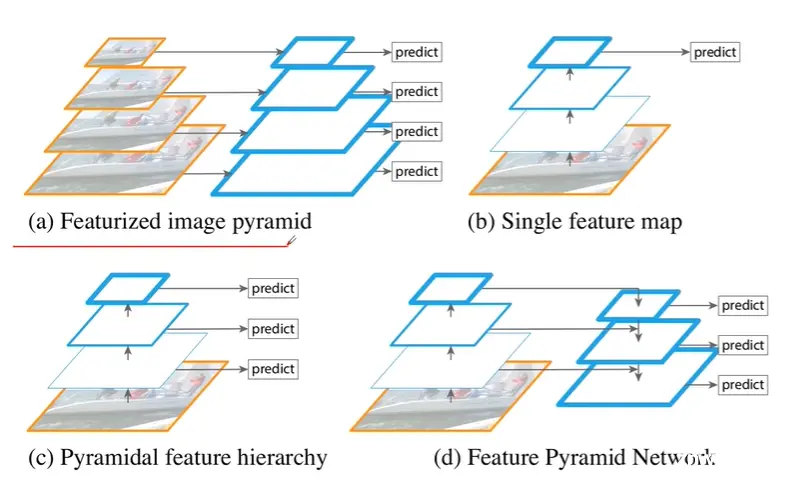
下图中的(d)就是FPN结构。我们先看一下abc,对于a是将不同尺度的图片生成的特征图都做一次预测,这样做明显速度非常慢。b是将图片最后的特征图做一次预测,c是同一尺度的图片生成的不同尺度的特征图都做一次预测。
对于FPN,它并不是在我们backbone上不同特征图进行一个预测,而是会将我们不同特征图上的特征去进行一个融合,然后在我们融合之后的特征图上再进行一个预测。通过论文的实验我们可以了解到,这样做确实有助于我们提升网络的检测效果。

1.3 FPN的具体细节
特征图大小的选取是有规则的,即自底向上依次除以2,假如最底层是28x28,那么上面一层就是14x14,在上面一层是7x7.
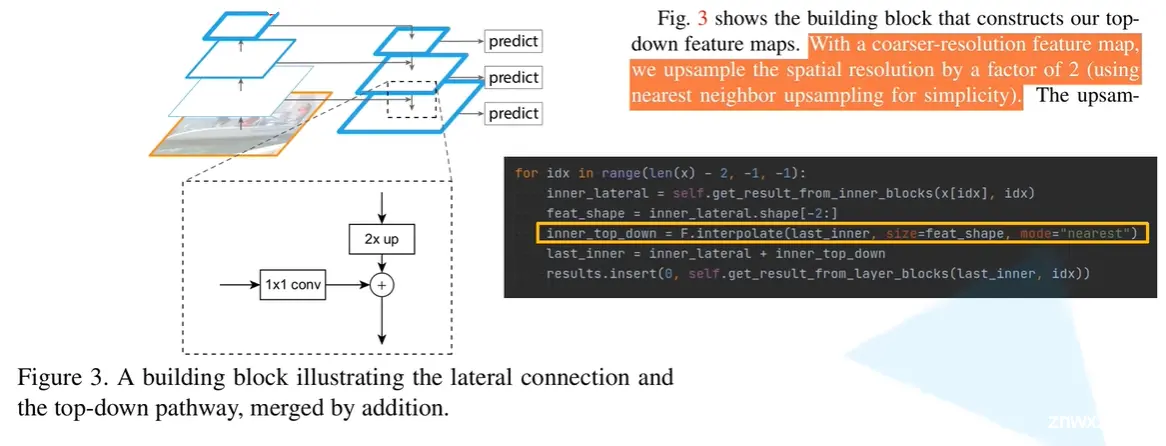
针对每一个特征图,我们都会先去使用一个1x1的卷积层进行处理(调整channel保证一致),因为不同特征图对应的channel一般情况下是不一样的。
那么高层(上面)的特征图如何与下面的特征图进行融合的呢?就是将上面的特征图进行一个2倍的上采样后,与1x1卷积之后的那个较大的特征图进行一个add的操作。
那么2倍上采样是怎么实现的呢?论文里使用的就是“临近插值算法”。
临近插值算法
临近插值算法(Nearest Neighbor Interpolation),又称最近邻插值,是一种简单且计算效率高的图像缩放方法。在数字图像处理中,当需要改变图像的尺寸,特别是放大图像时,临近插值算法通过直接复制最近的像素值来估算新像素的位置值,不涉及像素值的混合或计算。
原理
定义: 当需要从一个低分辨率图像创建一个高分辨率图像时,新图像中的每个像素都需要从原图像中找到一个对应的值。在临近插值中,新图像中的每个像素值直接取自原图中距离最近的已知像素点的值。
操作步骤:
首先,确定新图像的尺寸和原始图像的尺寸之间的比例关系。对于新图像中的每一个像素位置,计算该像素在原始图像中的对应位置。由于尺寸变化,这个对应位置通常是浮点数,而非整数坐标。取这个浮点坐标的整数部分,即找到了原图中最邻近的像素。将该邻近像素的值直接赋给新图像中的当前位置,忽略小数部分,不进行任何插值计算。
特点
优点:
计算速度快,实现简单,不需要额外的计算资源。保持了原图的锐利边缘,适用于需要保持图像边缘清晰度的场合。
缺点:
图像放大后,由于直接复制像素,会导致图像看起来像素化严重,边缘可能出现明显的阶梯效应,降低了图像的视觉质量。对于含有精细细节或渐变区域的图像,这种插值方法不能很好地恢复细节,可能会丢失重要的图像信息。
应用场景
尽管临近插值因牺牲图像质量而不适合要求高的图像处理任务,但它在某些特定情况下仍非常有用,比如在实时系统中,当处理速度优先于图像质量时,或者在一些算法的初步处理阶段,当需要快速预览结果而不关注细节时。此外,在某些特定的图像处理算法,如一些目标检测或图像分类任务的预处理阶段,如果对图像细节的要求不高,也可能使用临近插值来加速处理过程。
1.4 FPN网络结构
以Resnet50为例,假设输入的图像是640x640x3的RGB图像,我们对每个CONV生成的特征矩阵记为C2、C3、C4、C5,然后将我们得到的特征图进行一个1x1的卷积来调整channel,然后我从再从C5到C2(自顶向下)进行特征图的融合
因为我们最后生成了不同尺度的预测特征层,所以我们可以在不同的预测特征层上去分别针对不同尺度的目标进行预测。
我们之前看Faster R-CNN只有一个预测特征层,所以我们只在那一个层上去生成不同尺度和比例的anchor。
在FPN当中,我们不同的预测特征层会针对不同的面积,例如P2,P2是底层的特征层,它会保留更多的底层细节信息,所以它更适合去预测小型的目标,所以我们会将32²,比例为1:1,2:1,1:2的anchor在P2上进行生成。同理P3使用64²,P4使用128²,P5使用256²,P6使用512²。
至于不同的预测特征层,是否需要针对每一个特征层都去使用RPN和FastRCNN的模块呢?在论文里作者也进行了实验,在原论文当中,实验结果发现我们在不同的预测特征层上共用同一个RPN和FastRCNN和我们分别用,效果或者说检测精度几乎没有什么差异,所以共享是更好的,这样做能够减少训练参数和网络的大小,提升训练速度。
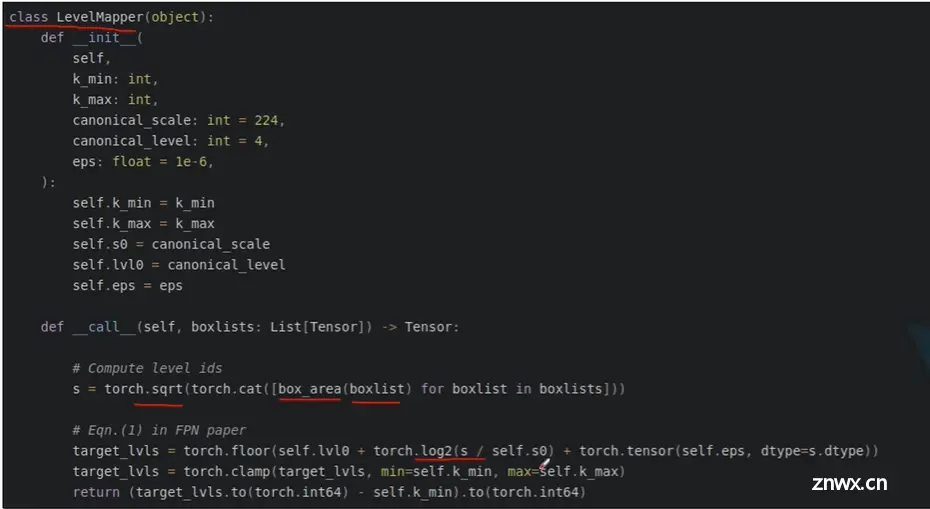
1.5 RPN生成的proposal如何映射到对应的预测特征层上
w,h对应的是PRN预测得到的一系列proposal它在原图上的宽高,k0=4,k代表之前提到的P2-P5。
举个例子proposal在原图上的宽高是112x112,那么log2括号内的值为1/2,log2(1/2)应为-1,加上k0后等于3,再向下取整还是3,那么就对应在我们的P3特征预测层上进行预测。

pytorch官方实现
1.6 有哪些网络用到了FPN
特征金字塔网络(FPN)自从被提出以来,因其在物体检测和语义分割任务中显著提升性能的能力,已被广泛应用于多种深度学习网络结构中。以下是一些采用或集成FPN结构的知名网络模型:
Faster R-CNN with FPN:FPN首次被提出时,就是作为 Faster R-CNN 模型的一部分,用于改进候选区域生成网络(Region Proposal Network, RPN),以及在检测阶段结合多尺度特征。
Mask R-CNN:在Mask R-CNN中,FPN也被用来改善实例分割任务的表现,通过在FPN的不同层上进行预测,提高了对不同尺度物体的分割精度。
RetinaNet:这是与FPN一同发表的另一项工作,它结合FPN结构设计了一个新的单阶段物体检测器,利用FPN的多尺度特性来解决物体检测中的类别不平衡问题,并且使用了Focal Loss。
YOLOv3/YOLOv4:YOLO(You Only Look Once)系列的后期版本,如YOLOv3和YOLOv4,也采用了特征金字塔网络的思想来处理多尺度检测,以提高对不同大小目标的检测能力。
EfficientDet:这是一个高效的目标检测模型系列,它结合了BiFPN(即改进的特征金字塔网络)来优化特征融合和多尺度特征处理,从而在保持较高精度的同时显著提高了运行效率。
Panoptic FPN:这是为了解决全景分割任务而提出的,它在FPN的基础上进一步发展,旨在统一实例分割和语义分割,提供一个全面的分割输出。
COCO-DRN:Deep Residual Network(DRN)结合FPN用于COCO数据集上的目标检测任务,展示了FPN在不同网络架构上的泛化能力。
除了这些,还有许多研究者在自己的定制化网络结构中融入了FPN的理念,以期在不同的视觉任务上取得更好的性能。FPN因其灵活性和有效性,已成为现代物体检测和分割网络设计中的一个标准组件。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。