[自动驾驶技术]-6 Tesla自动驾驶方案之硬件(AI Day 2021)
行置水穷处 2024-06-26 16:01:03 阅读 52
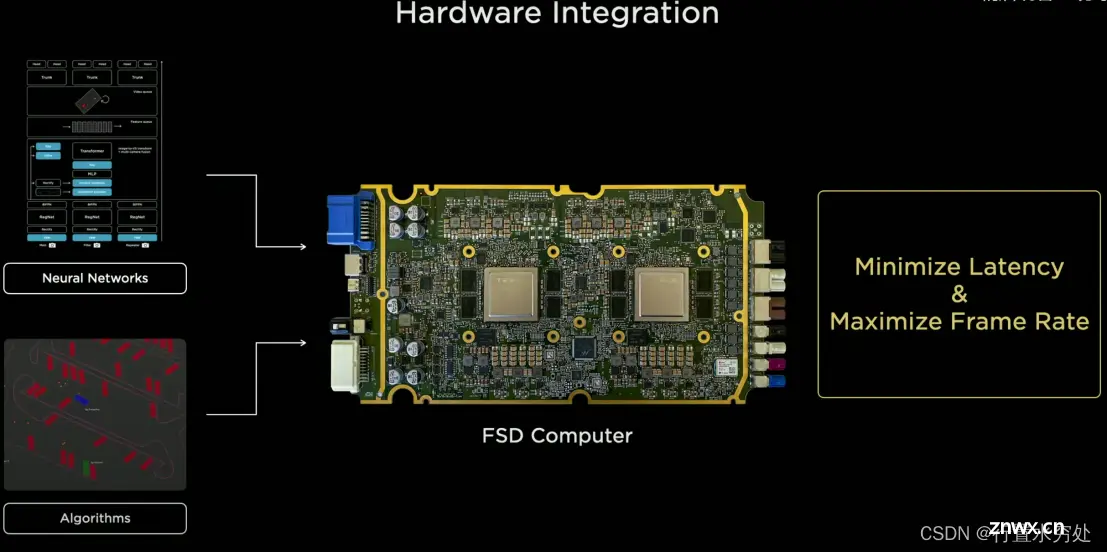
1 硬件集成
特斯拉自动驾驶数据标注过程中,跨250万个clips超过100亿的标注数据,无论是自动标注还是模型训练都要求具备强大的计算能力的硬件。下图是特斯拉FSD计算平台硬件电路图。

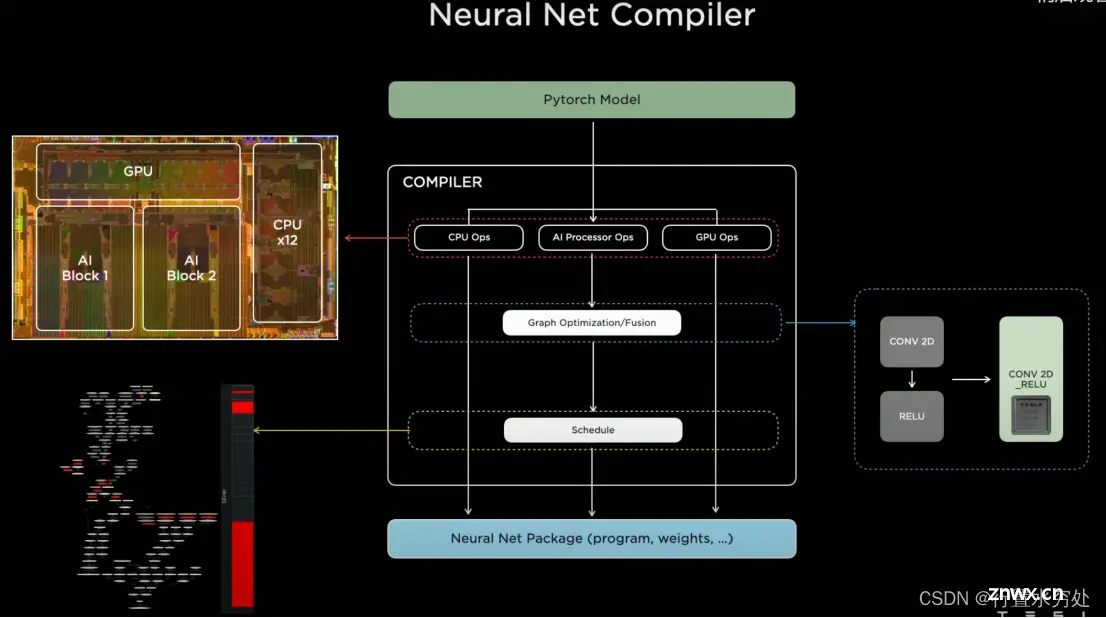
1)神经网络编译器
特斯拉AI编译器主要针对PyTorch框架,结合之前介绍过的编译器内容,特斯拉的自动驾驶算法模型需要通过编译器,生成硬件可执行的机器指令,才能在CPU、GPU或者AI芯片上运行。上图主要展示了AI编译器的计算图优化(算子融合:将CONV 2D和RELU算子融合为1个CONV 2D_RELU算子,这基本是常规标配做法),调度。
2)FSD计算平台

特斯拉FSD硬件计算平台集成了2颗SoC芯片,SOC-1输出最终的控制指令,SOC-2作为扩展计算。
3)AI模型评估中心

特斯拉的AI模型评估基础设施中心,可支持每周超过百万的评估计算,运行在超过3000个FSD计算平台上。
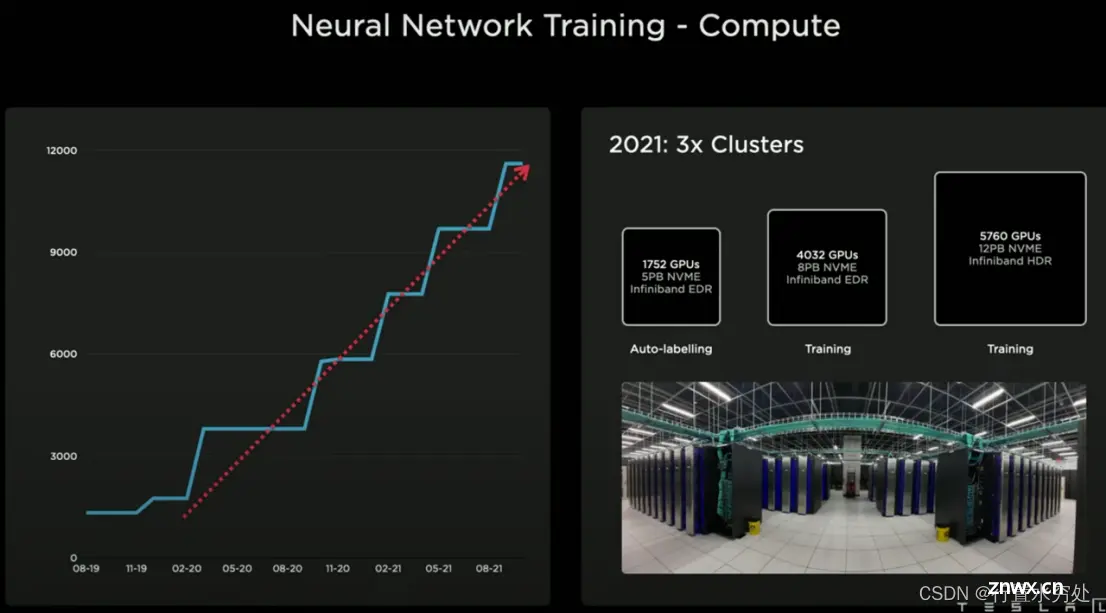
特斯拉的训练网络计算中心,2021年具备3个集群1组用于自动标注,2组用于模型训练。
2 DOJO项目
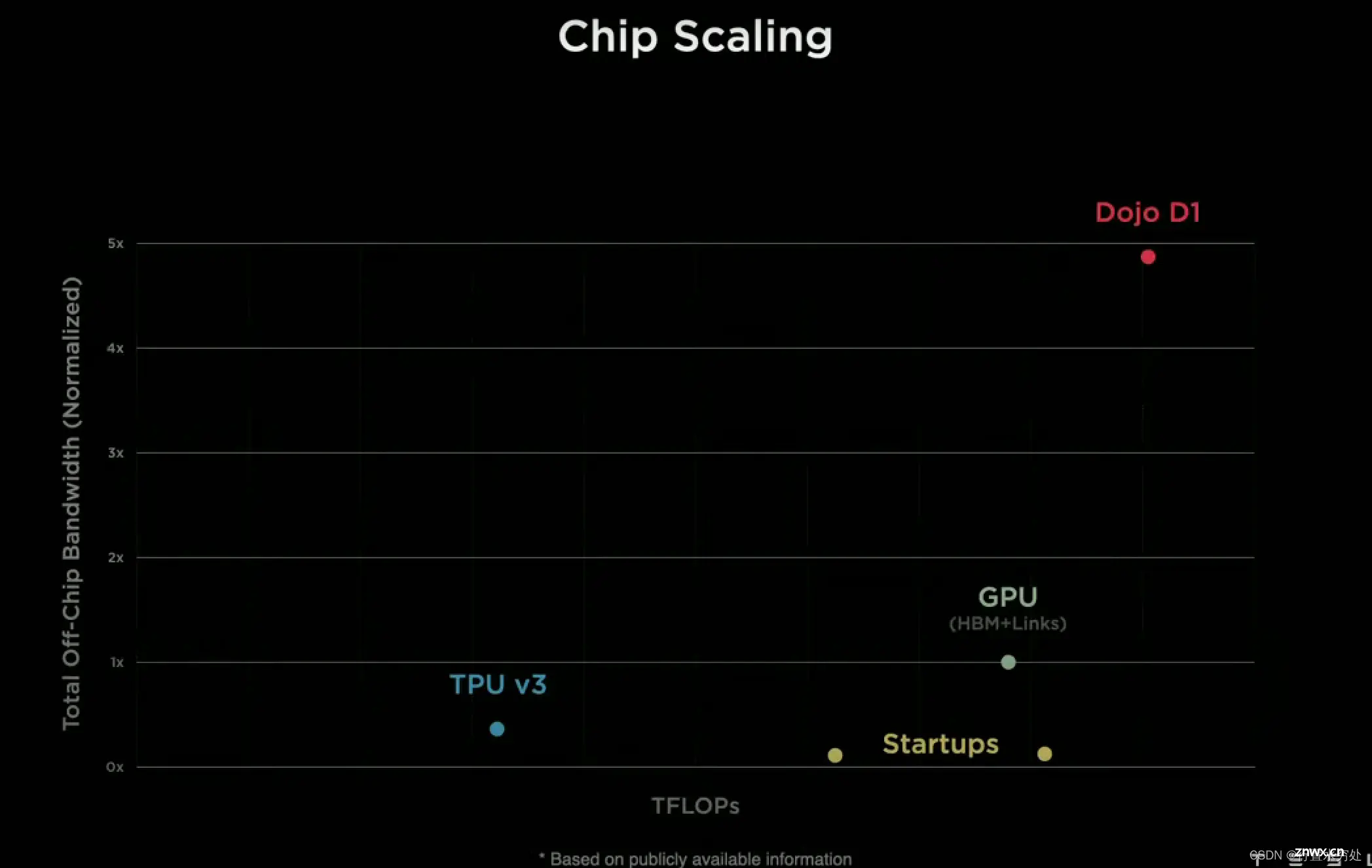
Ganesh说:“计算能力容易扩展,但带宽扩展较为困难,而降低延迟则极其困难。”
现代CPU、GPU和AI加速器通过不断优化架构(如增加核心数、提高时钟速度、优化指令集)来提升性能。特别是GPU和AI加速器,天然适合大规模并行计算,通过增加更多的计算单元,可以显著提升计算能力。
然而无论哪种处理器都很容易受到内存带宽限制: CPU、GPU和AI加速器需要高速访问内存,而内存带宽的提升速度往往跟不上计算能力的提升速度,造成带宽瓶颈,也就是我们常说的内存墙问题。此外,芯片内部的总线架构(如PCIe、NVLink)需要支持高带宽传输,扩展这些总线的带宽需要对芯片封装、功耗管理和信号完整性进行优化,难度较大。在多芯片系统中,不同芯片之间的数据传输也受到带宽限制,需要高速互连技术(如Infinity Fabric、NVLink)来解决,但这些技术实现复杂且成本较高。
降低延迟极其困难:从CPU到GPU或AI加速器的数据传输路径中,每一步都可能增加延迟,例如内存访问延迟、缓存命中率、总线传输延迟等都是难以完全消除的因素。在多任务环境中,任务调度和切换会带来上下文切换延迟和资源争用问题,这些问题在实时性要求高的应用中尤为突出。若想硬件和软件协同优化来减少延迟,涉及复杂的设计流程和大量的调优工作,需要深入理解整个系统的工作机制。

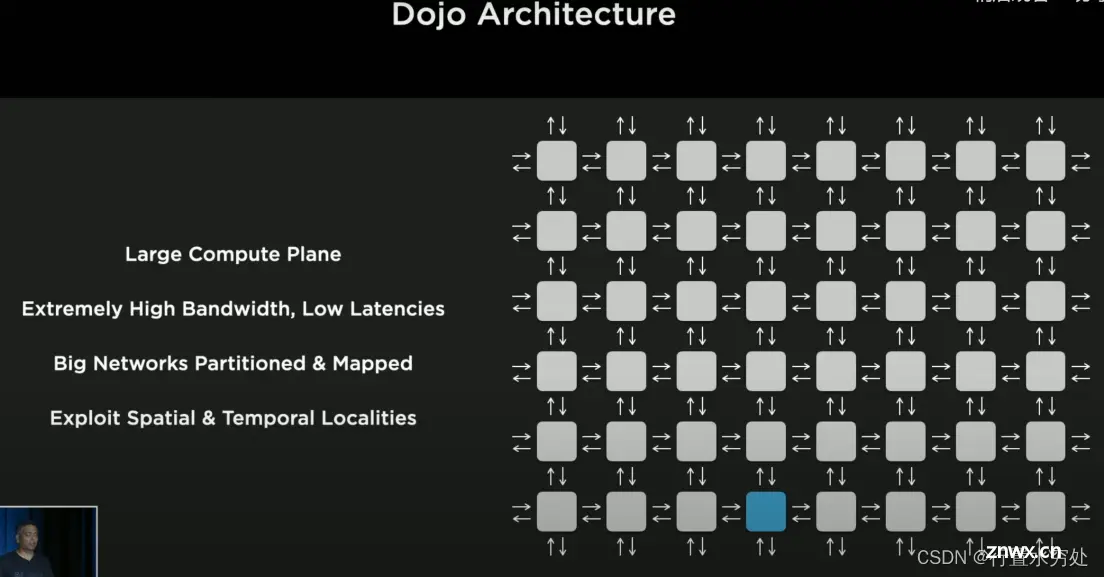
特斯拉的Dojo架构由计算单元和Network Fabric(指芯片上用于连接和通信的网络架构,是一种高性能的互连系统,负责在芯片内部不同计算单元之间传输数据)组成,采用了多种技术例如采用2D网格网络进行数据传输、对神经网络分割、调用本地存储方式等解决带宽和延迟的限制。
(一句话,特斯拉极大程度提高了带宽降低了延迟,远超业内)

1)芯片

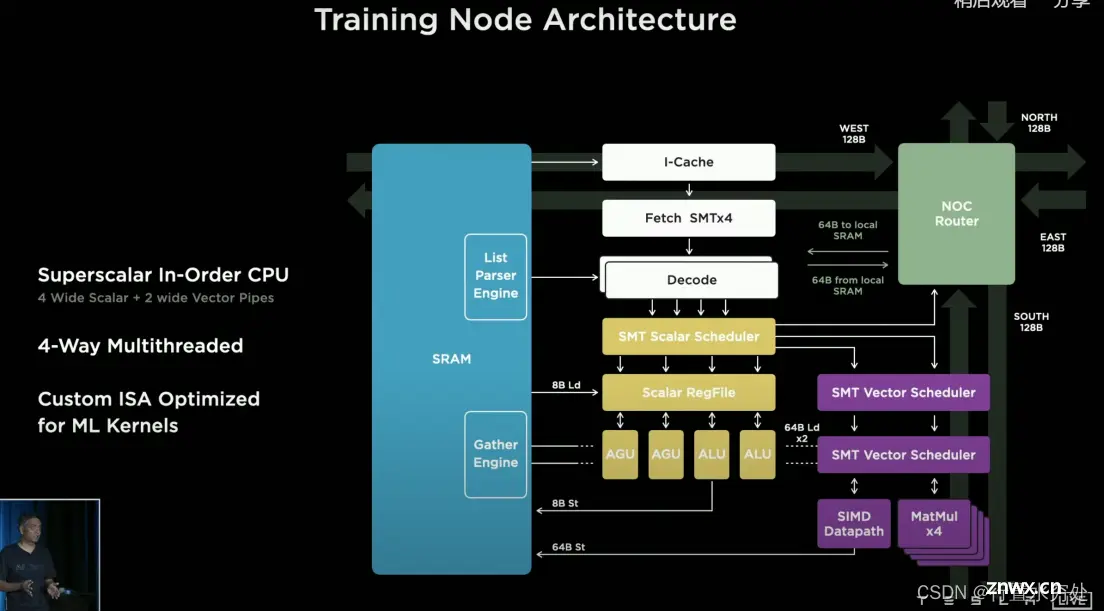
如上图所示是特斯拉SoC芯片上一个高性能的训练节点结构图:底部是机器学习阵列,左侧是SRAM存储阵列,再加上顶部的多线程可编程核。支持FP32、BFP16、CFP8。
1024 GFLOPS(BF16/CFP8)64GFLOPS(FP32)512GB/S带宽

如上图所示,这是个超标量处理器核,四个宽标量核两个宽标量数据管线;支持四个线程;针对机器学习支持自定义指令集ISA,例如转置、链接遍历、广播等。(这部分工作原理会在处理器专栏做详细介绍)
特斯拉D1芯片由354个训练节点组成计算阵列,可谓针对机器学习的机器,GPU级别的芯片同时拥有CPU的灵活性核两倍NPU级别的I/O带宽,提供了超高性能的计算能力。
2)计算系统Computer Plane
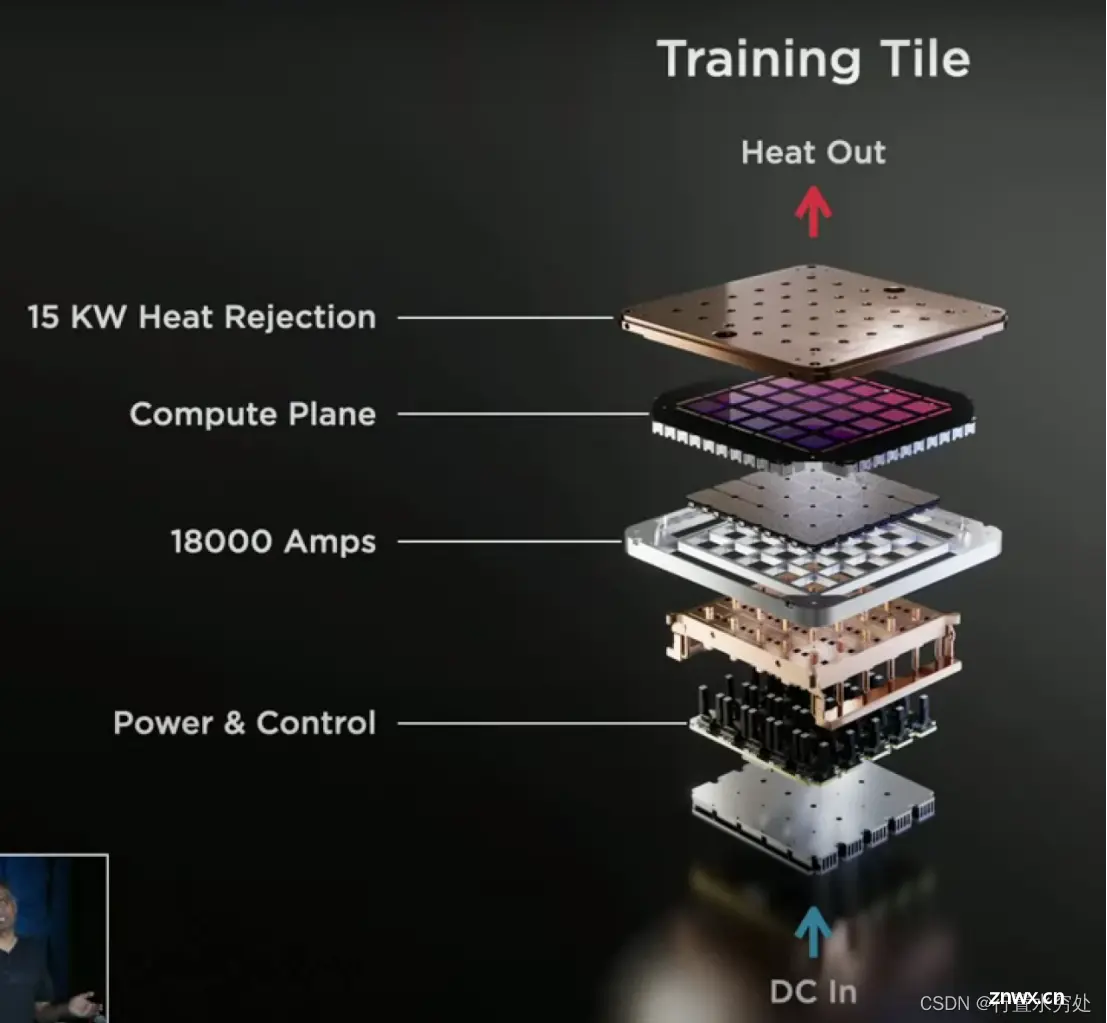
特斯拉的计算系统上,1个Training Tile集成了25个D1芯片,四周使用高速连接器支持9TB/S带宽,支持9PFLOPS(BF16/CFP8)
3)计算集群

4)AI编译器
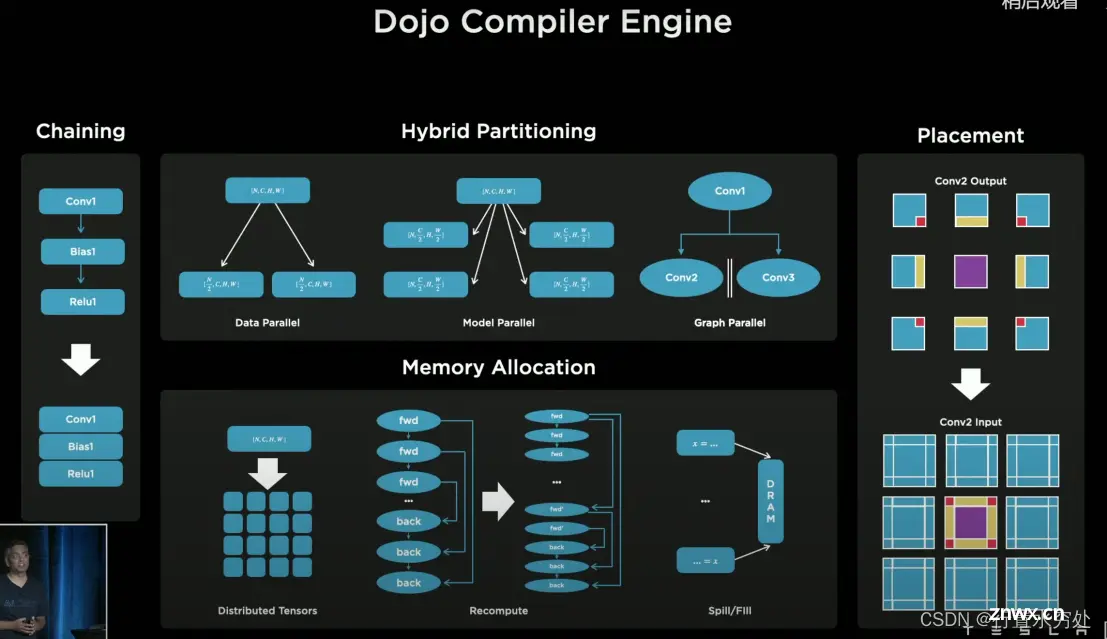
特斯拉Dojo编译器引擎,使用多种细颗粒度的并行化技术:数据并行、模型并行、计算图并行技术,还支持高层次的环路管理,例如循环等。
特斯拉的软件栈有两个重点:用户编程接口,基于PyTorch做了扩展;使用LLVM作为底层处理生成硬件所需的二进制代码。
LLVM(Low Level Virtual Machine)是一套用于构建编译器和相关工具的开源项目,提供了一种模块化和可重用的编译器基础架构。LLVM的架构主要包括:前端负责将源代码转换为LLVM中间表示IR;中端对LLVM IR进行各种优化处理,提高代码执行效率;后端将优化后的LLVM IR转换为目标机器码,具体包括代码生成和目标特定优化。
(以下为笔者猜测内容)
特斯拉的Dojo AI编译器使用LLVM作为后端处理的基础架构,通过LLVM的模块化设计和强大的优化能力,实现高效的AI模型编译和执行:
自定义目标支持:特斯拉可以通过LLVM的目标描述文件,定义Dojo芯片的特性,并扩展LLVM的指令选择和代码生成模块,以支持特斯拉可能有的特定的硬件加速单元和自定义指令集自定义指令。高效的寄存器分配:Dojo AI编译器可以利用LLVM的寄存器分配算法,优化寄存器使用,减少内存访问,提高模型执行效率。目标特定优化:通过LLVM的目标特定优化能力,Dojo AI编译器可以实现针对Dojo硬件的深度优化,包括利用硬件加速单元和并行计算资源,提高模型推理速度。模块化和可扩展性:LLVM的模块化设计允许特斯拉根据需要扩展和定制编译器后端,以适应不同的AI模型和硬件需求。可以在LLVM的基础上添加新的优化通道和代码生成策略,提升整体性能。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。