【AI】ubuntu 22.04 RTX4060TI 16G 本地部署通义千问 7B模型
hkNaruto 2024-07-05 15:01:02 阅读 78
下载模型
git lfs install
git clone https://www.modelscope.cn/qwen/Qwen-7B.git
中途下载报错,手动下载几个没有正常拉下来的模型文件
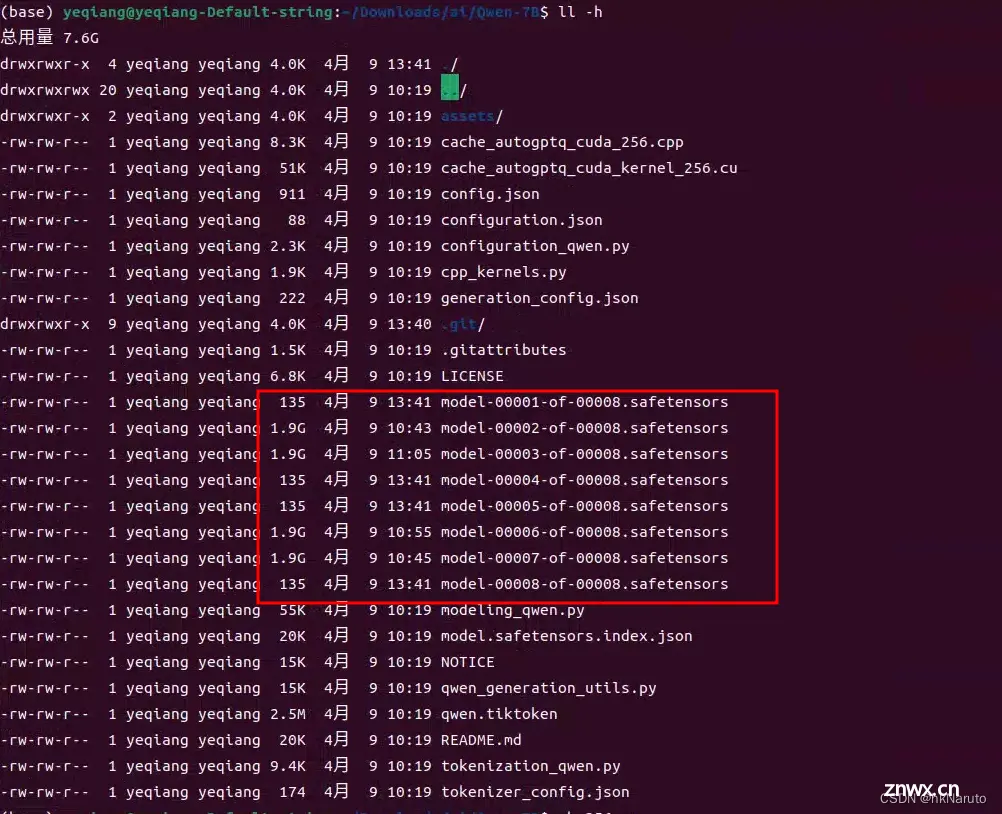

移动过来

Quickstart
创建工作目录以及env

要求及安装依赖
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
pip install flash-attention
pip install modelscope
测试,非常缓慢!GPU显存接近极限

异常缓慢,调整代码报错,显存不足

fp16,bf16都会报错。


接近4分钟,没有意义了。。。
后续研究下量化方法,缩小模型对显存的消耗看看效果。
7B模型这个问题的回答乱七八糟

部署Qwen web
下载源代码
git clone https://gh-proxy.com/https://github.com/QwenLM/Qwen
创建venv安装依赖

安装web的依赖
pip install -r requirements_web_demo.txt
直接启动报错
python3 web_demo.py
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/yeqiang/下载/src/Qwen/web_demo.py", line 209, in <module>
main()
File "/home/yeqiang/下载/src/Qwen/web_demo.py", line 203, in main
model, tokenizer, config = _load_model_tokenizer(args)
File "/home/yeqiang/下载/src/Qwen/web_demo.py", line 41, in _load_model_tokenizer
tokenizer = AutoTokenizer.from_pretrained(
File "/home/yeqiang/下载/src/Qwen/venv/lib/python3.10/site-packages/transformers/models/auto/tokenization_auto.py", line 773, in from_pretrained
config = AutoConfig.from_pretrained(
File "/home/yeqiang/下载/src/Qwen/venv/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1100, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/yeqiang/下载/src/Qwen/venv/lib/python3.10/site-packages/transformers/configuration_utils.py", line 634, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/yeqiang/下载/src/Qwen/venv/lib/python3.10/site-packages/transformers/configuration_utils.py", line 689, in _get_config_dict
resolved_config_file = cached_file(
File "/home/yeqiang/下载/src/Qwen/venv/lib/python3.10/site-packages/transformers/utils/hub.py", line 425, in cached_file
raise EnvironmentError(
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like Qwen/Qwen-7B-Chat is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
没有指定模型,自动连接到huggingface,报错
查看help
(venv) (base) yeqiang@yeqiang-Default-string:~/Downloads/src/Qwen$ python3 web_demo.py --help
usage: web_demo.py [-h] [-c CHECKPOINT_PATH] [--cpu-only] [--share] [--inbrowser] [--server-port SERVER_PORT] [--server-name SERVER_NAME]
options:
-h, --help show this help message and exit
-c CHECKPOINT_PATH, --checkpoint-path CHECKPOINT_PATH
Checkpoint name or path, default to 'Qwen/Qwen-7B-Chat'
--cpu-only Run demo with CPU only
--share Create a publicly shareable link for the interface.
--inbrowser Automatically launch the interface in a new tab on the default browser.
--server-port SERVER_PORT
Demo server port.
--server-name SERVER_NAME
Demo server name.
指定模型路径,再次启动
python3 web_demo.py -c /home/yeqiang/Downloads/ai/Qwen-7B --server-port 8080
Wed Apr 10 09:49:48 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti Off | 00000000:01:00.0 On | N/A |
| 0% 35C P8 13W / 165W | 13219MiB / 16380MiB | 34% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3465 G /usr/lib/xorg/Xorg 200MiB |
| 0 N/A N/A 3617 G /usr/bin/gnome-shell 62MiB |
| 0 N/A N/A 66713 G ...38243838,2569802313780412916,262144 52MiB |
| 0 N/A N/A 258826 C python3 12890MiB |
+---------------------------------------------------------------------------------------+

web模式需要下载Qwen-7B-Chat模型。
Qwen-7B-Chat模型
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git
速度有点慢,输出内容还行(显存90%左右,GPU 80%左右)

参考:
魔搭社区
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。