使用 continue 自定义 AI 编程环境
tiger119 2024-10-08 12:01:01 阅读 77
一直在使用github 的 copilot 来编程,确实好用,对编码效率有很大提升。
但是站在公司角度,因为它只能对接公网(有代码安全问题)。另外,它的扩展能力也不强,无法适配公司特定领域的知识库,无法最大化作用,所以不太能大规模推广,当然,还有成本问题(每月每人70多元,不是个小数目)。
于是,想尝试选型 开源的Continue插件来试试,是否可以替代github copilot,完成公司内部的AI 编程。试用了一下,总如如下:
一、Continue介绍:

它是一款开源的领先的AI编程助手,主要作用是代码自动生成和在编码中问答。因为是完全开源的,可定制性也非常好,一些企业级的大模型产品,也采用类似的方案。它作为插件,支持VS Code 和 JetBrains 两种较通用的IDE。
主要的功能一览:
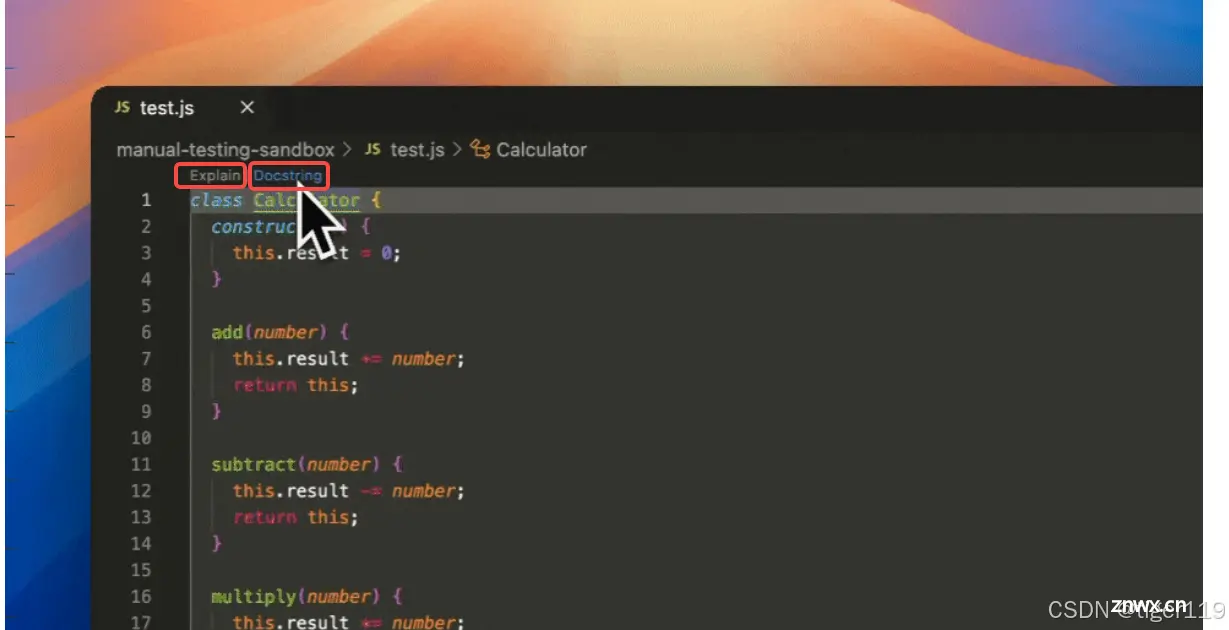
1:快速理解选中的代码,为你解释代码。通过问答(解释选中代码)
2:自动补全代码,提供编码的提示。使用 tab 来选择提示的代码。
3:对选定的代码进行重构。问题(可提出重构的要求)
4:针对当前项目/代码库的代码进行提问。使用 @codebase 进行范围限定后的提问。
还有一些默认范围。如:@Git Diff @Terminal @Problems
5:快速引用上下文。针对上下文进行提问。上下文有一些默认值,也可以自行定义。如:@a1.cpp 这是针对代码 @React 代码框架 ……
6:使用 / 快速执行命令,完成固定的任务。预置任务:
/comment 加注释,/edit 编辑修改代码,/share 将代码按指定格式输出用于分享,/cmd 执行命令,/test 生成单元测试。
命令可以自行定义(定义的执行是提示词)
7:进一步解释/解决调试终端中的错误。
二、安装初始化:
2.1:Configuration
配置主要是配使用的聊天模型,补齐代码模型,嵌入式索引算法模型,排序算法模型。
免费试用(在线):
{ -- -->
"models": [
{
"title": "GPT-4o (trial)",
"provider": "free-trial",
"model": "gpt-4o"
}
],
"tabAutocompleteModel": {
"title": "Codestral (trial)",
"provider": "free-trial",
"model": "AUTODETECT"
},
"embeddingsProvider": {
"provider": "free-trial"
},
"reranker": {
"name": "free-trial"
}
}
使用的都是公网提供的代理服务,在时间,速度,性能,功能上都是有限制的。所以,对于企业级应用是基本不能用。
最佳配置(在线):
chatting:使用 Claude 3.5
autocomplete:Codestral
embeddings:Voyage AI
remark:Voyage AI
{
"models": [
{
"title": "Claude 3.5 Sonnet",
"provider": "anthropic",
"model": "claude-3-5-sonnet-20240620",
"apiKey": "[ANTHROPIC_API_KEY]"
}
],
"tabAutocompleteModel": {
"title": "Codestral",
"provider": "mistral",
"model": "codestral-latest",
"apiKey": "[CODESTRAL_API_KEY]"
},
"embeddingsProvider": {
"provider": "openai",
"model": "voyage-code-2",
"apiBase": "https://api.voyageai.com/v1/",
"apiKey": "[VOYAGE_AI_API_KEY]"
},
"reranker": {
"name": "voyage",
"params": {
"apiKey": "[VOYAGE_AI_API_KEY]"
}
}
}
这虽然是最佳配置,但因为涉及apikey,所以需要去相应的完成注册。
本地配置(离线):
主要使用ollama来完成本地服务的部署。可以保证使用中不会有什么内容外泄。
For chat: ollama pull llama3:8bFor autocomplete: ollama pull starcoder2:3bFor embeddings: ollama pull nomic-embed-text
{
"models": [
{
"title": "Ollama",
"provider": "ollama",
"model": "AUTODETECT"
}
],
"tabAutocompleteModel": {
"title": "Starcoder 2 3b",
"provider": "ollama",
"model": "starcoder2:3b"
},
"embeddingsProvider": {
"provider": "ollama",
"model": "nomic-embed-text"
}
}
注意:为了保证完全私密性,对于VSCode的插件安装需要单独下载后安装。
对于遥测监控功能需要关闭:将 "allowAnonymousTelemetry" 设置为 false。这将阻止 Continue 插件向 PostHog 发送匿名遥测数据。
验权配置:
验权方式:通过apikey
"apiKey": "xxx"
上下文长度配置:
设置模型的上下文长度,确定了chat时能返回的长度
"contextLength": 8192
定制对话模板
如果你采用的模型,对于提示词有特殊的要求,可以通过定制对话模板,来统一不同模型造成的差异。这个需要你对采用的模型非常熟悉。
~/.continue/config.ts
function modifyConfig(config: Config): Config {
const model = config.models.find(
(model) => model.title === "My Alpaca Model",
);
if (model) {
model.templateMessages = templateAlpacaMessages;
}
return config;
}
continue/core/llm/templates/chat.ts at main · continuedev/continue · GitHub
function templateAlpacaMessages(msgs: ChatMessage[]): string {
let prompt = "";
if (msgs[0].role === "system") {
prompt += `${msgs[0].content}\n`;
msgs.pop(0);
}
prompt += "### Instruction:\n";
for (let msg of msgs) {
prompt += `${msg.content}\n`;
}
prompt += "### Response:\n";
return prompt;
}
定制Edit提示词
如果要定制 /edit 的提示词,可以如下配置。(具体如何定义类似/edit,后面会有讲解)
const codellamaEditPrompt = `\`\`\`{ { {language}}}
{ { {codeToEdit}}}
\`\`\`
[INST] You are an expert programmer and personal assistant. Your task is to rewrite the above code with these instructions: "{ { {userInput}}}"
Your answer should be given inside of a code block. It should use the same kind of indentation as above.
[/INST] Sure! Here's the rewritten code you requested:
\`\`\`{ { {language}}}`;
function modifyConfig(config: Config): Config {
config.models[0].promptTemplates["edit"] = codellamaEditPrompt;
return config;
}
定制对话模型返回:
如果定制自已的简易的大模型来支持输入,可以如下配置:(当然,这样做的可能性很小,一般是不会这么做的)
export function modifyConfig(config: Config): Config {
config.models.push({
options: {
title: "My Custom LLM",
model: "mistral-7b",
},
streamCompletion: async function* (
prompt: string,
options: CompletionOptions,
fetch,
) {
// Make the API call here
// Then yield each part of the completion as it is streamed
// This is a toy example that will count to 10
for (let i = 0; i < 10; i++) {
yield `- ${i}\n`;
await new Promise((resolve) => setTimeout(resolve, 1000));
}
},
});
return config;
}
2.2:Provider Select
Provider,实际上是联系continue和背后模型的一个服务,我们还需要单独说明一下。
自行托管服务
* 本地私有部署——可以选择一些通用的服务,有一大堆。
我们用的是Ollama
* 远程——可以将服务部署到公有云服务,比如AWS,Azure,阿里云。
可以选用一些标准框架,比如:HuggingFace TGI,vLLM,Anyscal Private Ednpoints。
Saas公有云服务
* Open-source models —— 开源社区提供的
* 商业模型 —— 商业公司提供的模型。
也可以使用 OpenRouter来适配上述两种。
2.3:models Select
选择的模型支持,那就是 会话,代码补全,词嵌入(索引)模型了。在config.json文件中配置。
代码补齐,聊天,词嵌入(编码索引),重排序 对应的支持模型
聊天:用于与用户进行自然语言交流,回答编程相关的问题,解释代码,提供编程建议等。
代码补全:在用户编写代码时,实时提供代码补全建议,提高编程效率。
词嵌入:用于生成代码和文档的向量表示,支持相似度计算、代码搜索、推荐等功能。将代码和自然语言转换成高维向量,以便进行各种向量操作,如查找相似代码片段、推荐相关文档等。
重排序:对于多个生成结果或推荐结果进行排序,以提供最优的建议给用户。
Chat:
建议 30B + parameters。
开源LLM——Llama 3,DeepSeek
商用LLM——Claude 3,GPT-4o,Gemini Pro,
AutoComplete:
建议 1-15 B parameters
开源LLM——DeepSeek,StarCoder
商用LLM——Mistral codestral-latest
Embeddings:
开源LLM——nomic-emded-text
商用LLM——voyage-code-2
三、自定义功能
可以自定义和配置的项目有:
* Models 和 providers (这个在上一章里已经基本讲过了)
* 上下文变量 @
* 快速命令 /
* 其它配置项
3.1:Context Provider
可以通过@快速引用希望引用的代码或文档内容,然后交给LLM去查找答案。
Context 有三种类型:
第一种:normal 就是正常的类型,比如 @ codebase, termial,os之类的,就是直接引用内容。
第二种:query 就是需要查询后的内容,比如 @ Google, Search 之类的,需要有搜索后得到的内容。
第三种:submenu 就是需要用户再做选择的。比如 @Folder @issue
系统内置:
@code:可以引用当前工程中的 Function 或者 Class。
@Git Diff:针对需要提交的内容做询问。这个可以在提交前review一下代码。
@Terminal:针对IDE中的Terminal的内容引用。
@Docs:指定具体的文档
@Files / Folder:指定具体的文件或者目录
@Codebase:指定的是当前工程
@URL:指定一个路径文件内容
@Google:基于google搜索的结果,这个是要求在线的。
@Github issues: 针对github 的isuue,这需要配置一下token获得指定工程的授权。
@GitLab MR 针对gitlab 的merge request,这个需要配置一下git lab的服务器。
@jira 这个可以针对jira issue 进行提问,但需要配置许可token。还可以配置一下 issue的query,缩小范围。
@postgres:可以针对某张表内容或者全部表内容。需要进行DB的连接配置。
@database:这个可以针对所有数据库,需要做更多的连接配置
@Locals:针对当前线程的局部变量
@os:针对当前的操作系统
自定义context provider
需要实现 CustomContextProvider
interface CustomContextProvider {
title: string;
displayTitle?: string;
description?: string;
renderInlineAs?: string;
type?: ContextProviderType;
getContextItems(
query: string,
extras: ContextProviderExtras,
): Promise<ContextItem[]>;
loadSubmenuItems?: (
args: LoadSubmenuItemsArgs,
) => Promise<ContextSubmenuItem[]>;
}
最重要就是上下文的名字和内容。
~/.continue/config.ts
const RagContextProvider: CustomContextProvider = {
title: "rag",
displayTitle: "RAG",
description:
"Retrieve snippets from our vector database of internal documents",
getContextItems: async (
query: string,
extras: ContextProviderExtras,
): Promise<ContextItem[]> => {
const response = await fetch("https://internal_rag_server.com/retrieve", {
method: "POST",
body: JSON.stringify({ query }),
});
const results = await response.json();
return results.map((result) => ({
name: result.title,
description: result.title,
content: result.contents,
}));
},
};
export function modifyConfig(config: Config): Config {
if (!config.contextProviders) {
config.contextProviders = [];
}
config.contextProviders.push(RagContextProvider);
return config;
}
如何实现 submenu 或者 query 呢?
如果是query,需要提供一个输入框,用来辅助生成内容。
type 设置为qury。
如果是submenu,需要将 type 设置为 submenu。需要提供submenu的内容
const ReadMeContextProvider: CustomContextProvider = {
title: "readme",
displayTitle: "README",
description: "Reference README.md files in your workspace",
type: "submenu",
getContextItems: async (
query: string,
extras: ContextProviderExtras,
): Promise<ContextItem[]> => {
// 'query' is the filepath of the README selected from the dropdown
const content = await extras.ide.readFile(query);
return [
{
name: getFolder(query),
description: getFolderAndBasename(query),
content,
},
];
},
loadSubmenuItems: async (
args: LoadSubmenuItemsArgs,
): Promise<ContextSubmenuItem[]> => {
// Filter all workspace files for READMEs
const allFiles = await args.ide.listWorkspaceContents();
const readmes = allFiles.filter((filepath) =>
filepath.endsWith("README.md"),
);
// Return the items that will be shown in the dropdown
return readmes.map((filepath) => {
return {
id: filepath,
title: getFolder(filepath),
description: getFolderAndBasename(filepath),
};
});
},
};
export function modifyConfig(config: Config): Config {
if (!config.contextProviders) {
config.contextProviders = [];
}
config.contextProviders.push(ReadMeContextProvider);
return config;
}
function getFolder(path: string): string {
return path.split(/[\/\\]/g).slice(-2)[0];
}
function getFolderAndBasename(path: string): string {
return path
.split(/[\/\\]/g)
.slice(-2)
.join("/");
}
在实现中,可以引入 Node的其它模块,辅助完成编程。
如果不想使用TypeScript,要使用其它语言,可以使用RestFull接口来适配。
{
"name": "http",
"params": {
"url": "https://myserver.com/context-provider",
"title": "http",
"description": "Custom HTTP Context Provider",
"displayTitle": "My Custom Context"
}
}
3.2:Slash Commands
用 / 开头的一系列命令,可以指明一些操作的具体内容。
内置命令:
/edit:按照后续的指令,对于当前选中的代码进行编辑。
/comment:对代码加注释
/share:对当前代码按指定要求进行markdown方式的输出,方便share。
/cmd:将结果输出到terminal,像一个shell command。
/commit: 生成一个commit的 message,针对需要提交的代码。
/http: 通过HTTP Restful 接口获取信息。
/issue:提交一个bug,需要做一些连接。可以快速提单。
/so:从 stackOverflow 上获取内容进行询问。
自定义命令:
通过提示词(自然语言)来定义命令:
customCommands=[{
"name": "check",
"description": "Check for mistakes in my code",
"prompt": "{ { { input }}}\n\nPlease read the highlighted code and check for any mistakes. You should look for the following, and be extremely vigilant:\n- Syntax errors\n- Logic errors\n- Security vulnerabilities\n- Performance issues\n- Anything else that looks wrong\n\nOnce you find an error, please explain it as clearly as possible, but without using extra words. For example, instead of saying 'I think there is a syntax error on line 5', you should say 'Syntax error on line 5'. Give your answer as one bullet point per mistake found."
}]
通过程序来实现自定义命令:
export function modifyConfig(config: Config): Config {
config.slashCommands?.push({
name: "commit",
description: "Write a commit message",
run: async function* (sdk) {
const diff = await sdk.ide.getDiff();
for await (const message of sdk.llm.streamComplete(
`${diff}\n\nWrite a commit message for the above changes. Use no more than 20 tokens to give a brief description in the imperative mood (e.g. 'Add feature' not 'Added feature'):`,
{
maxTokens: 20,
},
)) {
yield message;
}
},
});
return config;
}
四:功能详解
4.1:Chat 功能
对于chat功能,完全依赖于模型的能力,按道理来说,使用越强的模型,效果越好。和直接使用chatGPT的情况类似。这里不再详细讨论。按目前市面上的情况来看,GPT-4o的能力应该是最强的。对于开源模型,llama3-70b,或者最新的llama3.1-405B(号称多项指标超越 GPT4o)
4.2:Tab Autocomplete
对于自动补全,是 AI Code 的最重要功能,
商业的版本,官方推荐的并不是GPT的模型,而是 Mistra的codestral-latest。开源版本,推荐的是 starcode2:16b。如果你觉得运行太慢,可以考虑 deepseek-coder:1.3b-base。如果你有更多的计算资源,可以考虑升级到 deepseek-coder:6.7b-base.
官方不推荐 GPT和Claude(并不是预算的原因),因为自动补齐在训练时需要有提示词,但这些商业的模型做得并不好。而要做到这一点,10b以下的参数量就能做得很好。类似如下的提示词训练:
// Fill in the middle prompts
import { CompletionOptions } from "..";
import { AutocompleteSnippet } from "./ranking";
interface AutocompleteTemplate {
template:
| string
| ((
prefix: string,
suffix: string,
filename: string,
reponame: string,
snippets: AutocompleteSnippet[],
) => string);
completionOptions?: Partial<CompletionOptions>;
}
// https://huggingface.co/stabilityai/stable-code-3b
const stableCodeFimTemplate: AutocompleteTemplate = {
template: "<fim_prefix>{ { {prefix}}}<fim_suffix>{ { {suffix}}}<fim_middle>",
completionOptions: {
stop: ["<fim_prefix>", "<fim_suffix>", "<fim_middle>", "<|endoftext|>"],
},
};
// https://arxiv.org/pdf/2402.19173.pdf section 5.1
const starcoder2FimTemplate: AutocompleteTemplate = {
template: (
prefix: string,
suffix: string,
filename: string,
reponame: string,
snippets: AutocompleteSnippet[],
): string => {
const otherFiles =
snippets.length === 0
? ""
: "<file_sep>" +
snippets
.map((snippet) => {
return snippet.contents;
// return `${getBasename(snippet.filepath)}\n${snippet.contents}`;
})
.join("<file_sep>") +
"<file_sep>";
let prompt = `${otherFiles}<fim_prefix>${prefix}<fim_suffix>${suffix}<fim_middle>`;
return prompt;
},
completionOptions: {
stop: [
"<fim_prefix>",
"<fim_suffix>",
"<fim_middle>",
"<|endoftext|>",
"<file_sep>",
],
},
};
const codeLlamaFimTemplate: AutocompleteTemplate = {
template: "<PRE> { { {prefix}}} <SUF>{ { {suffix}}} <MID>",
completionOptions: { stop: ["<PRE>", "<SUF>", "<MID>", "<EOT>"] },
};
// https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base
const deepseekFimTemplate: AutocompleteTemplate = {
template:
"<|fim▁begin|>{ { {prefix}}}<|fim▁hole|>{ { {suffix}}}<|fim▁end|>",
completionOptions: {
stop: ["<|fim▁begin|>", "<|fim▁hole|>", "<|fim▁end|>", "//"],
},
};
const deepseekFimTemplateWrongPipeChar: AutocompleteTemplate = {
template: "<|fim▁begin|>{ { {prefix}}}<|fim▁hole|>{ { {suffix}}}<|fim▁end|>",
completionOptions: { stop: ["<|fim▁begin|>", "<|fim▁hole|>", "<|fim▁end|>"] },
};
const gptAutocompleteTemplate: AutocompleteTemplate = {
template: `Your task is to complete the line at the end of this code block:
\`\`\`
{ { {prefix}}}
\`\`\`
The last line is incomplete, and you should provide the rest of that line. If the line is already complete, just return a new line. Otherwise, DO NOT provide explanation, a code block, or extra whitespace, just the code that should be added to the last line to complete it:`,
completionOptions: { stop: ["\n"] },
};
export function getTemplateForModel(model: string): AutocompleteTemplate {
const lowerCaseModel = model.toLowerCase();
// if (lowerCaseModel.includes("starcoder2")) {
// return starcoder2FimTemplate;
// }
if (
lowerCaseModel.includes("starcoder") ||
lowerCaseModel.includes("star-coder") ||
lowerCaseModel.includes("starchat") ||
lowerCaseModel.includes("octocoder") ||
lowerCaseModel.includes("stable")
) {
return stableCodeFimTemplate;
}
if (lowerCaseModel.includes("codellama")) {
return codeLlamaFimTemplate;
}
if (lowerCaseModel.includes("deepseek")) {
return deepseekFimTemplate;
}
if (lowerCaseModel.includes("gpt")) {
return gptAutocompleteTemplate;
}
return stableCodeFimTemplate;
}
4.3:代码的检索场景
代码的检索,从表面上并不能看到,但实际上很多功能都和它相关。比如:我们使用的上下文引用,快速命令,都会对大量的内容进行索引,匹配。这需要很好的 Codebase retrival 功能,这就依赖于嵌入式模型,关键字搜索,排序的功能。
比如:@folder What is the purpose of the utils directory? 这里会检索内容。
当然,并不是所有的检索都会被continue执行,
使用嵌入编码的情况
高层次问题和上下文检索: 当用户提出高层次的问题(例如关于代码库的设计、架构、实现方法等)时,Continue 会使用嵌入编码来对整个代码库进行语义检索。这有助于找到与用户问题最相关的文档和代码片段。
@codebase How is the authentication implemented in this project?
相似代码生成和引用: 当用户要求生成与现有代码相似的新代码时,Continue 会使用嵌入编码来查找相似的代码片段,以便生成新的代码或提供参考。
@React Generate a new component similar to the existing Button component.
文件夹或特定文件的上下文检索: 当用户针对特定文件夹或文件提出问题时,Continue 会使用嵌入编码来检索相关内容,确保回答与上下文相关。
@folder What is the purpose of the utils directory?
综合文档和代码库检索: 在用户希望检索整个文档和代码库中的相关信息时,嵌入编码有助于在大量文档中找到语义上相关的内容。
@codebase Do we use VS Code's CodeLens feature anywhere?
不使用嵌入编码的情况
直接问题解答: 对于一些直接且具体的问题,Continue 可以直接利用 LLM 中已训练的知识来回答,而不需要进行嵌入编码和检索。
What is the syntax for a for loop in Python?
简单代码生成: 当用户要求生成简单的代码片段或回答不需要复杂的上下文时,Continue 可以直接生成代码,而无需进行嵌入编码和检索。
Write a function to reverse a string in JavaScript.
基础知识和常见问题: 对于基础编程知识和常见问题,Continue 可以直接利用模型中已存在的知识库进行回答,而不需要进行嵌入编码。
What is the difference between a list and a tuple in Python?
决策逻辑
Continue 的决策逻辑大致如下:
是否需要上下文:
如果问题需要上下文信息(如高层次问题、相似代码生成、文件夹或特定文件的上下文),则使用嵌入编码。如果问题不需要上下文信息(如基础知识、简单代码生成、直接问题解答),则不使用嵌入编码。
问题的复杂性:
对于复杂问题,特别是那些需要结合整个代码库的信息来回答的问题,使用嵌入编码。对于简单问题,可以直接利用模型中的已训练知识来回答。
4.4:Prompt files
可以定制 test.prompt 文件,根据提示词,快速完成需要要功能。
temperature: 0.5
maxTokens: 4096
---
<system>
You are an expert programmer
</system>
{ { { input }}}
Write unit tests for the above selected code, following each of these instructions:
- Use `jest`
- Properly set up and tear down
- Include important edge cases
- The tests should be complete and sophisticated
- Give the tests just as chat output, don't edit any file
- Don't explain how to set up `jest`
4.5:Quck Action
这应该是试用版的功能,我没有试过,说明可以提供一些快捷的功能入口。
"experimental": { -- -->
"quickActions": [
{
"title": "Unit test",
"prompt": "Write a unit test for this code. Do not change anything about the code itself.",
}
]
}
可以比较快捷的完成一些组合功能。
4.6:功能快捷键
我们来回顾一下,以VS-Code LLinux 版为例 ,有哪些重要的快捷键。
1:选中代码,Ctrl + L,针对选中代码进行快问快答。如果没有选中代码,针对当前编辑框内容进行问答。
2:Tab 针对提示补全的代码,进行确认。
3:选中代码,Ctrl + I,进行 Inline chat,
4:@可以唤起上下文变量,如果该变量有子菜单,回车会显示子内容。
5:/可以添加命令。针对当前内容进行处理。
6:Ctrl + Shift + R 解释终端中的错误内容。
五:总结
在性能上看,与github copilot 进行比较,可能对接模型的能力原因,代码补全能力是稍弱的。且流畅度会稍差,当然,也可能是我配置的问题。总的来说,基本可用。
在功能上看,没有太多的差别。
但是可配置性还是很强的。完全可以利用 @ 和 \ 的定制能力,为自已公司的领域开发,提供很多便利性。
比如:
* @ 来支持强大的代码库的检索功能。提供三方库,内置库的功能解释。
* / 定义命令来集成一些开发中的工具,这样更加快捷,比如代码提交前的自查。
* / 来完成与CI/CD系统的集成,完成一些MR相关的工作。
* / 来完成与问题单系统进行集成,快速定位和分析错误。
* 提供单元测试模板,快速生成单元测试。
* 提供快速生成注释的功能,……
* 针对硬件开发的特点,提供arch file,约束的引用,检查……
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。