【AI-6】算力和带宽
W Y 2024-09-02 11:31:04 阅读 88
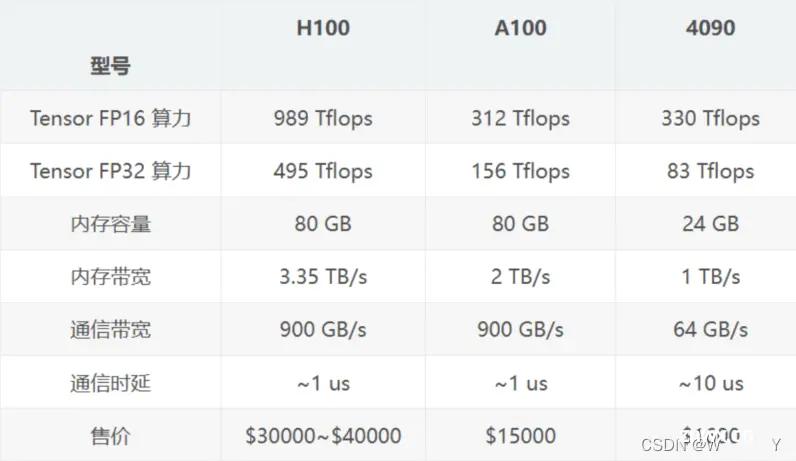
上述为大模型训练的显卡选项
tensor fp16 算力是什么?
Tensor FP16(Float16)算力是指GPU在执行深度学习的张量计算时,使用float16(半精度浮点)数据类型所能达到的性能指标。
为什么要使用Tensor FP16?
提升计算效率:
float16数据类型的存储和计算开销比float32(单精度浮点)低一半,可以大幅提升GPU的吞吐量和能效。减少显存占用:
float16只占用float32一半的显存空间,可以在同等显存容量下容纳更大的模型。加速训练/推理:
利用FP16的加速优势,可以显著加快深度学习模型的训练和推理速度。
Tensor FP16算力的计算方式如下:
每个Tensor Core单元能同时执行4个FP16乘法和4个FP16加法操作。
在NVIDIA Ampere架构的A100 GPU上,Tensor FP16算力高达312 TFLOPS。
而在上一代Volta架构的V100 GPU上,Tensor FP16算力为125 TFLOPS。
需要注意的是,在使用FP16进行计算时,需要进行混合精度训练。这是因为FP16的数值范围和精度较float32要小,直接使用FP16可能会导致精度损失和数值不稳定。
通过混合精度训练,模型的权重和梯度使用float32进行更新,而中间计算则使用float16,可以在保证精度的前提下大幅提升训练速度。
总之,Tensor FP16算力是GPU在深度学习场景中的一项重要性能指标,它可以通过半精度计算来显著提升模型的训练和推理效率。这对于需要快速迭代的AI应用非常关键。
H100显卡的989Tflops算力中的989是什么意思?
TFLOPS (Tera Floating-Point Operations Per Second)是衡量GPU计算性能的一个重要指标,表示每秒可执行的浮点运算次数。
H100 GPU的 989 TFLOPS 中的 “989” 就是指它的浮点运算性能可达到989兆次每秒(989 Trillion Floating-Point Operations Per Second)。
也就是说,H100 GPU在特定的浮点运算场景下(主要是深度学习中的张量运算),它的计算速度可以达到每秒989万亿次浮点运算。
这个超高的算力数字代表了H100在AI加速领域的领先性能。它相比上一代A100的312 TFLOPS提升了3倍多,这意味着H100可以大幅提高深度学习模型的训练和推理速度。
对于需要处理大规模数据和复杂神经网络的AI应用来说,H100的989 TFLOPS算力无疑是一个巨大的性能优势,有助于推动各种前沿AI技术的发展。
所以总的来说,989 TFLOPS就是H100 GPU强大计算能力的一个具体量化指标,体现了它在AI加速领域的领先地位。
Tensor FP16 和 Tensor FP32?
Tensor FP16和Tensor FP32是深度学习硬件中常见的两种浮点运算精度。它们的区别如下:
定义:
Tensor FP16 (半精度浮点数)使用16位表示浮点数。
Tensor FP32 (单精度浮点数)使用32位表示浮点数。算力差异:
FP16的计算速度通常是FP32的2-4倍。
这是因为FP16的硬件电路和内存访问更简单,可以并行处理更多运算。精度差异:
FP16的数值范围和精度略低于FP32,但对于大多数深度学习任务来说已经足够。
FP16的动态范围约为FP32的1/16,因此在极端情况下可能会出现溢出或精度损失。应用场景:
FP16主要应用于GPU和AI加速器中的神经网络训练和推理。
由于速度优势,FP16特别适用于对计算性能要求高的深度学习任务,如图像识别、自然语言处理等。
FP32则更适用于需要更高精度的科学计算和传统机器学习场景。
综上所述,Tensor FP16和FP32各有优缺点,需要根据具体任务的性能和精度需求进行选择。现代AI硬件通常支持两种精度并行运算,以充分发挥算力潜能。
内存带宽和通信带宽分别是什么?有什么区别?
内存带宽和通信带宽是两个不同但都很重要的性能指标:
内存带宽(Memory Bandwidth):
内存带宽指的是GPU或CPU与其内存之间的数据传输速率。
它决定了GPU或CPU能够从内存中读取和写入数据的速度。
内存带宽越高,就能为GPU或CPU提供更快的数据吞吐量,从而提高整体计算性能。通信带宽(Communication Bandwidth):
通信带宽指的是GPU与CPU、GPU与GPU之间的数据传输速率。
它决定了多个处理器或加速器之间进行数据交换的速度。
通信带宽越高,就能更快地在不同设备之间传输数据,降低系统瓶颈。
二者的主要区别如下:
内存带宽是局部的,仅针对单个设备内部;而通信带宽是全局的,涉及多个设备之间的数据交互。
内存带宽主要影响单设备的计算性能;通信带宽则影响整个分布式系统的性能和扩展性。
内存带宽由内存控制器和内存设计决定;通信带宽由总线、链路、网络等架构决定。
总的来说,内存带宽和通信带宽都是现代计算系统的关键指标,内存带宽决定单机性能上限,通信带宽则决定分布式系统的整体性能。两者缺一不可,是构建高性能计算平台的两大支柱。
显卡内存容量?
显卡的内存容量是非常重要的一个硬件参数,它会对显卡的性能和应用场景产生较大影响:
定义:
显卡内存容量指的是显卡自身搭载的专用显存容量大小,通常以GB为单位。作用:
显卡内存容量决定了显卡可以处理的最大数据量。
它直接影响着显卡在各类图形图像、视频渲染、深度学习等场景的性能表现。影响因素:
图像分辨率和色深:更高分辨率和色深需要更大的显存容量。
纹理、模型复杂度:复杂3D场景需要更多的显存用于贴图等。
深度学习模型尺寸:复杂的深度学习模型需要更多显存用于参数存储。
多任务并行:同时运行多个图形、计算任务需要更大的显存。优化建议:
对于一般图形图像应用,4-8GB显存通常可满足需求。
对于高分辨率视频编辑和3D建模,建议选择8-16GB显存。
对于复杂的深度学习训练,选择16-32GB显存会有更好的性能表现。
对于未来应用需求的增长,可以选择更大容量的显存以留有余量。
总之,显卡内存容量是一个关键的硬件参数,它会直接影响显卡在不同应用场景下的性能表现。合理选择显存容量非常重要。
AI算力集群?
对于AI领域的算力需求,选择先部署集群还是单个高性能GPU,需要综合考虑几个关键因素:
计算任务特点:
如果是大规模的并行化训练任务,如大型语言模型训练,集群部署更合适。
而对于单个小型模型的快速迭代开发,使用单个高性能GPU可能更有优势。数据吞吐要求:
对于需要高吞吐计算的任务,如实时语音识别、视频推理等,集群部署可提供更强大的总体算力。
但单GPU也可能满足部分实时应用的低延迟需求。资源利用效率:
集群部署可提高资源利用率,比如通过调度实现多任务并行计算。
但集群管理也会增加一定的系统开销和复杂度。成本预算:
集群部署的总体硬件成本可能会高于单GPU方案,但能提供更强大的算力扩展能力。
单GPU方案初期投入较低,但后期可能需要频繁升级硬件。开发效率:
集群部署需要解决分布式训练、模型并行等复杂问题,开发效率可能较低。
单GPU方案的开发测试更简单,可以快速迭代。
综合以上因素,如果是大规模并行计算任务,或需要高吞吐的实时应用,集群部署通常是更合适的选择。但对于小型模型的快速迭代开发,使用单个高性能GPU可能更有优势。需要根据具体应用场景进行权衡取舍。
部署集群时需要考虑哪些具体的技术实现细节?
AI算力集群,顾名思义,是一种由多个计算节点组成的集群,专门用于进行人工智能相关的计算任务。这些节点可以是普通的服务器,也可以是专业的AI芯片或者GPU。通过将这些计算节点组合在一起,形成一个整体,可以提供远超单个节点的计算能力。这种集群化的计算模式,不仅可以提高计算效率,还可以降低能耗,实现资源的最大化利用。
AI算力集群的核心是分布式计算。在分布式计算中,一个大型的任务被分解成多个小任务,然后分配给不同的计算节点进行处理。每个节点只需要完成自己的小任务,然后将结果返回给主节点。主节点再将所有的结果合并起来,得到最终的结果。这种并行处理的方式,大大提高了计算速度。
除了分布式计算,AI算力集群还采用了多种优化技术,如负载均衡、数据并行、模型并行等,进一步提高了计算效率。同时,为了应对复杂的计算环境,AI算力集群还具备强大的容错能力和可扩展性。当某个节点出现故障时,其他节点可以自动接管其工作,保证整个集群的正常运行。而当需要处理更大规模的数据时,可以通过增加新的计算节点,轻松扩展集群的规模。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。