顶会常客,全面盘点多模态融合算法及应用场景
沃恩智慧 2024-10-07 14:31:02 阅读 66
多模态融合
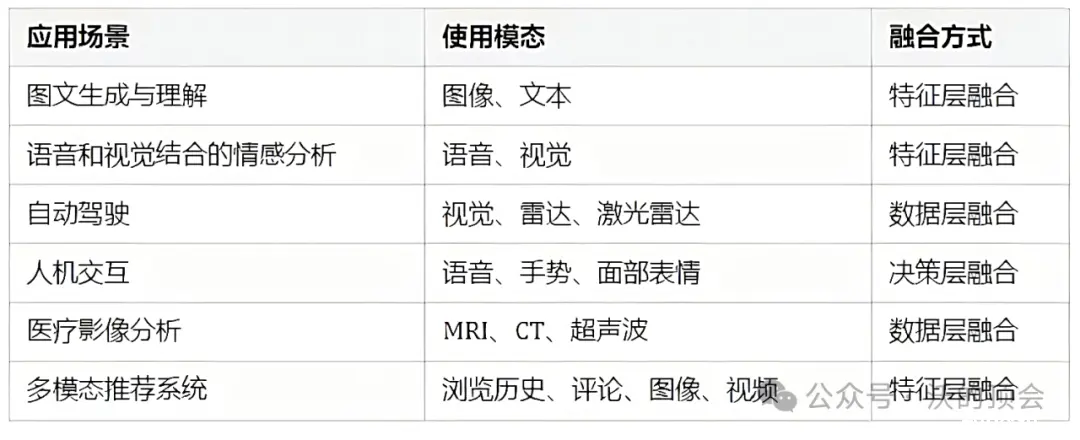
多模态融合(Multimodal Fusion)不仅是近年顶会的常客,此外,多模态融合技术还在图文生成与理解、语音和视觉结合的情感分析、自动驾驶、人机交互、医疗影像分析、多模态推荐系统等多个领域有着广泛的应用。不同应用场景中使用的模态及其融合方式可总结为以下表格:
为了帮助大家进一步学习多模态融合,沃的顶会整理了24篇多模态融合算法及应用场景相关论文分享给大家。
需要的同学关注公中号【沃的顶会】回复 “融合24”免费领取
1、多模态图像融合方法
标题:FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
方法:FusionMamba 包含一般融合过程中的三个关键组件:特征提取、特征融合和特征重建。该网络体系结构基于Unet框架,有效地提取更深层次的特征。这两个特点提取和重建阶段利用设计的动态视觉状态空间(DVSS)的模块。特征融合阶段采用动态特征融合模块(DFFM),每个层的动态增强融合块包括两个Dy-namic特征增强模块(DFEM)和一个跨模态融合Mamba模块(CMFM)。
创新点:
1. 设计了一种新颖的动态特征增强的Mamba图像融合模型,这是第一种改进的状态空间模型用于图像融合,为基于CNN和Transformers的方法提供了一种简单而有效的替代方案。
2. 提出了动态视觉状态空间(Dynamic Visual State Space, DVSS)模块,它通过动态增强局部特征并减少通道冗余,提升了标准Mamba模型的效率。这种增强加强了其建模和特征提取能力。
3. 特征融合模块从源图像中提取关键信息,并探索不同模态之间的关系。它包含一个动态特征增强模块,用于增强细微的纹理特征并感知差异特征,以及一个跨模态Mamba融合模块,用于有效地探索跨模态之间的相关性。
4. 开发了一个高效且多功能的图像融合框架,在包括红外与可见光融合、多模态医学图像融合以及生物医学图像融合在内的各种图像融合任务中取得了领先性能。
2、基于视觉语言模型的跨模态多级融合情感分析方法
标题:UniSA: Unified Generative Framework for Sentiment Analysis
方法:本文采用生成式Transformer体系结构,将所有的敏感性分析子任务统一为生成任务。具体地说,为了处理视觉、听觉和文本的跨模态输入,作者将原来的Transformer编码器修改为多模态编码器,并引入模态掩模训练方法。为了使模型能够有效地学习不同模态之间的关系,还提出了一个特定于任务的提示方法来标准化所有子任务的输入格式。此外,为了解决数据集之间的偏差,作者在输入中引入了数据集嵌入,以区分不同的数据集。该技术有助于模型更好地理解每个数据集的特征,并提高其在所有任务上的性能。
创新点:
1. 提出了一种新的情感分析方法UniSA,将所有子任务统一在一个单一的生成框架下。这代表了该领域的重大进展,因为以前没有工作采取如此全面的方法进行情感分析。
2. 提出了新颖的情感相关预训练任务,使模型能够学习跨子任务的通用情感知识。大量的实验结果表明,UniSA在所有子任务上都能与最先进的模型相媲美。
3. 创建了一个基准数据集 SAEval,该数据集以统一格式包含各种情绪分析子任务的基准数据集中,从而能够对情绪分析模型进行全面和公正的评估。
3、多模态自动驾驶
标题:DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
方法:DriveMLM框架将大型语言模(LLMs)的世界知识和推理能力集成到自动驾驶(AD)系统中,在现实模拟器中实现闭环驾驶。该框架有3个关键设计:①行为规划状态对齐。这部分将LLM的语言决策输出与行为规划模块对齐该模块是一个成熟的模块化AD系统,如阿波罗3这样,LLM的输出就可以很容易地转化为车辆控制信号。②MLLM规划器。它是多模式分词器和多模式LLM(MLLM)解码器的组合。多式分词器将多视图图像、激光雷达、交通规则和用户要求等不同输入转换为统一标记,MLLM解码器根据统一标记做出决策。③高效的数据收集策略。它为基于LLM的自动驾驶引入了定制的数据收集方法,确保包括决策状态、决策解释和用户命令在内的全面数据集。
创新点:
1. 根据现成的运动规划模块标准化决策状态,弥合了语言决策和车辆控制命令之间的差距。
2. 使用多模态LLM(MLLM)来建模模块AD系统的行为规划模块,该模块使用驾驶规则,用户命令和来自各种传感器(例如,相机,激光雷达)的输入作为输入,并做出驾驶决策和提供解释;该模型可以在现有的AD系统(例如Apolo)中插拔,用于闭环驾驶。
3. 设计了一个有效的数据引擎来收集一个数据集,该数据集包括决策状态和相应的解释注释,用于模型的训练和评估。
4、多模态医疗分析的应用
标题:Towards Generalist Foundation Model for Radiology by Leveraging Web-scale 2D&3D Medical Data
方法:RadFM 是一个多模态的放射学基础模型,能够将自然语言无缝地与 2D 或 3D 医学扫描相结合,并通过文本输出来解决广泛的医学任务。研究团队首先在 MedMD 数据集上对该模型进行了预训练,然后在一个经过筛选的数据集 RadMD 上进行视觉指令微调。RadMD 包含 3M 对放射学相关的多模态数据,确保了针对特定领域的微调过程中数据集的高质量和可靠性。
创新点:
1. 数据上:提供了全新的目前世界上最大规模的医疗多模态数据集 MedMD&RadMD,是首个包含 3D 数据的大规模医疗多模态数据集,含 15.5M 2D 图像和 180k 的 3D 医疗影像。
2. 模型上:开源了 14B 多模态基础模型 RadFM,支持 2D/3D、图像 / 文本混合输入。
3. 测试上:定义了医疗基础模型五大基本任务 —— 模态识别、疾病诊断、医疗问答、报告生成和归因分析,并提供了一个全面的基准——RadBench。
5、多模态推荐系统
标题:DiffMM: Multi-Modal Diffusion Model for Recommendation
方法:DiffMM 的总体框架主要分为三个部分:①多模态图扩散模型,它通过生成扩散模型来实现多模态信息引导的模态感知用户-物品图的生成。②多模态图聚合,该部分在生成的模态感知用户-物品图上进行图卷积操作,以实现多模态信息的聚合。③跨模态对比增强,采用对比学习的方式来利用不同模态下用户-物品交互模式的一致性,从而进一步增强模型的性能。
创新点:
1. 提出了一种新颖的基于多模态图扩散的推荐模型,称为 DiffMM。该框架结合了模态感知图扩散模型和跨模态对比学习范式,以提升模态感知用户表示的学习效果。这种整合方式有助于更好地对齐多模态特征信息与协同关系建模。
2. DiffMM 利用扩散模型的生成能力自动构建用户-物品图,这个图能够表示不同模态下的用户-物品交互信息,从而有助于将有用的多模态知识融入到用户-物品交互建模中。
3. 作者在三个公共数据集上进行了大量实验,结果表明,DiffMM 在各种基准模型中表现出了显著的优越性。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。