月之暗面:Moonshot AI接口总结
幸福清风 2024-06-18 08:01:11 阅读 72
前言:
开发者们只需访问 platform.moonshot.cn,便能创建自己的 API Key,进而将 Kimi 智能助手背后的同款 moonshot 模型能力,如长文本处理和出色的指令遵循等,集成至自己的产品中。这不仅增强了现有产品的功能,更为开发者们提供了打造全新、富有创意的产品的机会。
除了核心的对话问答功能外,Moonshot AI 开放平台还提供了“文件内容提取”能力接口。这一功能使得开发者们能够结合文件上传功能,开发出针对文档和知识库场景的多样化应用。
在定价方面,Moonshot AI 开放平台提供了三个基础模型:moonshot-v1-8k、32k 和128k。这些模型的定价分别为每千个 token0.012元、0.024元和0.06元。为了让开发者们能够更好地体验平台的功能,注册后的开发者将获得价值15元的体验包,这相当于125万 tokens(8k模型)或62.5万 tokens(32k模型)的使用量。同时,个人自助充值功能也即将上线,为开发者们提供更多的便利和选择。
获取API Key:
1、打开网址:platform.moonshot.cn 注册账号登录
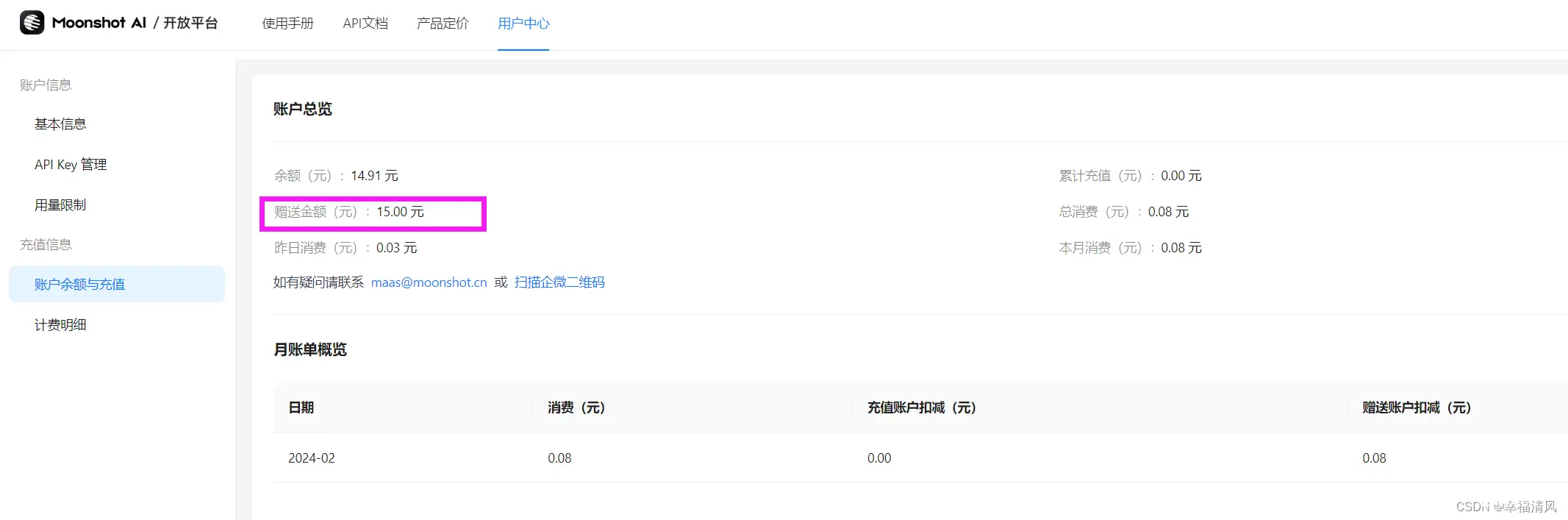
2、用户中心查看余额
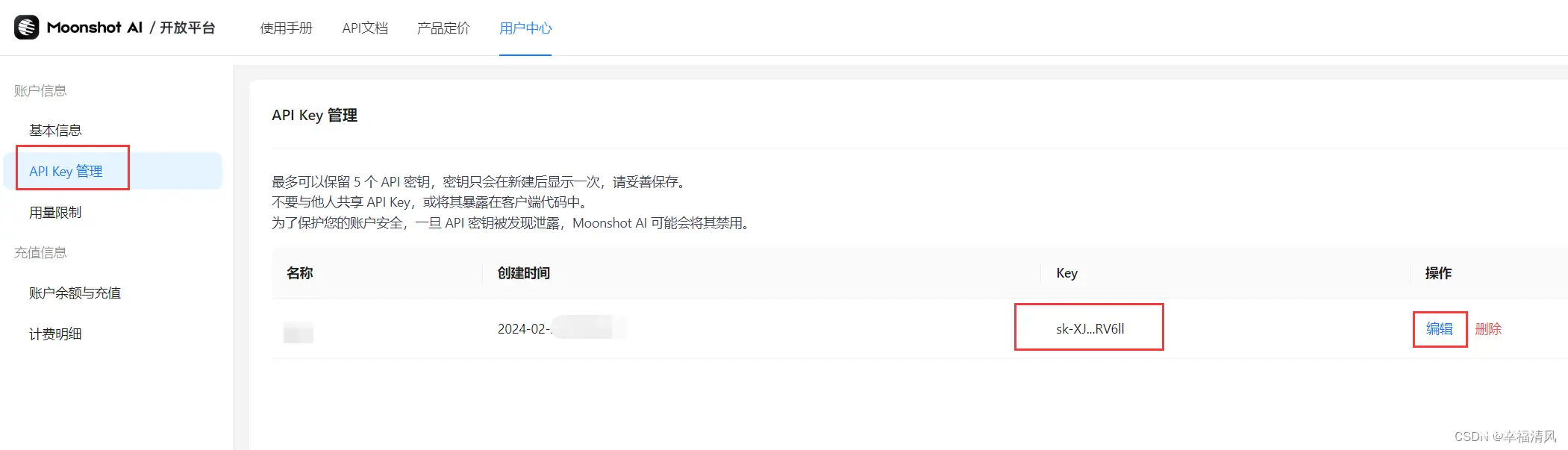
3、获取API Key
Python 安装及调用方法:
1、命令安装
pip install openai # 如果你没有安装,可以这样安装一下依赖
如果您之前安装过,请再更新一下 openai 确保它版本高于 1.0.
pip install --upgrade openai
示例:
import osfrom openai import OpenAIclient = OpenAI( api_key="MOONSHOT_API_KEY", base_url="https://api.moonshot.cn/v1",)completion = client.chat.completions.create( model="moonshot-v1-8k", messages=[ {"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}, {"role": "user", "content": "你好,我叫李雷,1+1等于多少?"} ], temperature=0.3,)print(completion.choices[0].message)
API 说明
请求地址
POST https://api.moonshot.cn/v1/chat/completions
请求内容
示例
{ "model": "moonshot-v1-8k", "messages": [ {"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}, {"role": "user", "content": "你好,我叫李雷,1+1等于多少?"} ], "temperature": 0.3}
字段说明
| 字段 | 说明 | 类型 | 取值 |
|---|---|---|---|
| messages | 包含迄今为止对话的消息列表。 | List[Dict] | 这是一个结构体的列表,每个元素类似如下:json{ "role": "user", "content": "你好"} role 只支持 system,user,assistant 其一,content 不得为空 |
| model | Model ID, 可以通过 List Models 获取 | string | 目前是 moonshot-v1-8k,moonshot-v1-32k,moonshot-v1-128k 其一 |
| max_tokens | 聊天完成时生成的最大 token 数。如果到生成了最大 token 数个结果仍然没有结束,finish reason 会是 "length", 否则会是 "stop" | int | 这个值建议按需给个合理的值,如果不给的话,我们会给一个不错的整数比如 1024。特别要注意的是,这个 max_tokens 是指您期待我们返回的 token 长度,而不是输入 + 输出的总长度。比如对一个 moonshot-v1-8k 模型,它的最大输入 + 输出总长度是 8192,当输入 messages 总长度为 4096 的时候,您最多只能设置为 4096,否则我们服务会返回不合法的输入参数( invalid_request_error ),并拒绝回答。如果您希望获得“输入的精确 token 数”,可以使用下面的“计算 Token” API 使用我们的计算器获得计数。 |
| temperature | 使用什么采样温度,介于 0 和 1 之间。较高的值(如 0.7)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性。 | float | 如果设置,值域须为 [0, 1] 我们推荐 0.3,以达到较合适的效果。 |
| top_p | 另一种采样温度 | float | 默认 1.0 |
| n | 为每条输入消息生成多少个结果 | int | 默认 1,不得大于 5 特别的,当 temperature 非常小靠近 0 的时候,我们只能返回 1 个结果,如果这个时候 n 设置并 > 1,我们服务会返回不合法的输入参数( invalid_request_error )。 |
| stream | 是否流式返回 | bool | 默认 false, 可选 true |
返回内容
对非 stream 格式的,返回类似如下:
{ "id": "cmpl-04ea926191a14749b7f2c7a48a68abc6", "object": "chat.completion", "created": 1698999496, "model": "moonshot-v1-8k", "choices": [ { "index": 0, "message": { "role": "assistant", "content": " 你好,李雷!1+1等于2。如果你有其他问题,请随时提问!" }, "finish_reason": "stop" } ], "usage": { "prompt_tokens": 19, "completion_tokens": 21, "total_tokens": 40 }}
对 stream 格式的,返回类似如下:
data: {"id":"cmpl-1305b94c570f447fbde3180560736287","object":"chat.completion.chunk","created":1698999575,"model":"moonshot-v1-8k","choices":[{"index":0,"delta":{"role":"assistant"},"finish_reason":null}]}data: {"id":"cmpl-1305b94c570f447fbde3180560736287","object":"chat.completion.chunk","created":1698999575,"model":"moonshot-v1-8k","choices":[{"index":0,"delta":{"content":"你好"},"finish_reason":null}]}...data: {"id":"cmpl-1305b94c570f447fbde3180560736287","object":"chat.completion.chunk","created":1698999575,"model":"moonshot-v1-8k","choices":[{"index":0,"delta":{"content":"。"},"finish_reason":null}]}data: {"id":"cmpl-1305b94c570f447fbde3180560736287","object":"chat.completion.chunk","created":1698999575,"model":"moonshot-v1-8k","choices":[{"index":0,"delta":{},"finish_reason":"stop","usage":{"prompt_tokens":19,"completion_tokens":13,"total_tokens":32}}]}data: [DONE]
调用示例
Python 流式调用
对简单调用,见前面。对流式调用,可以参考如下代码片段:
import osfrom openai import OpenAIclient = OpenAI( api_key="MOONSHOT_API_KEY", base_url="https://api.moonshot.cn/v1",)response = client.chat.completions.create( model="moonshot-v1-8k", messages=[ { "role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。", }, {"role": "user", "content": "你好,我叫李雷,1+1等于多少?"}, ], temperature=0.3, stream=True,)collected_messages = []for idx, chunk in enumerate(response): # print("Chunk received, value: ", chunk) chunk_message = chunk.choices[0].delta if not chunk_message.content: continue collected_messages.append(chunk_message) # save the message print(f"#{idx}: {''.join([m.content for m in collected_messages])}")print(f"Full conversation received: {''.join([m.content for m in collected_messages])}")
List Models
请求地址
GET https://api.moonshot.cn/v1/models
调用示例
import osfrom openai import OpenAIclient = OpenAI( api_key="MOONSHOT_API_KEY", base_url="https://api.moonshot.cn/v1",)model_list = client.models.list()model_data = model_list.datafor i, model in enumerate(model_data): print(f"model[{i}]:", model.id)
文件内容抽取
该功能可以实现让模型获取文件中的信息作为上下文。本功能需要配合文件上传等功能共同使用。
调用示例
from pathlib import Pathfrom openai import OpenAIclient = OpenAI( api_key="MOONSHOT_API_KEY", base_url="https://api.moonshot.cn/v1",)# xlnet.pdf 是一个示例文件, 我们支持 pdf, doc 等格式, 目前暂不提供ocr相关能力file_object = client.files.create(file=Path("xlnet.pdf"), purpose="file-extract")# 获取结果# file_content = client.files.retrieve_content(file_id=file_object.id)# 注意,之前 retrieve_content api 在最新版本标记了 warning, 可以用下面这行代替# 如果是旧版本,可以用 retrieve_contentfile_content = client.files.content(file_id=file_object.id).text# 把它放进请求中messages=[ { "role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。", }, { "role": "system", "content": file_content, }, {"role": "user", "content": "请简单介绍 xlnet.pdf 讲了啥"},]# 然后调用 chat-completion, 获取 kimi 的回答completion = client.chat.completions.create( model="moonshot-v1-32k", messages=messages, temperature=0.3,)print(completion.choices[0].message)
列出文件
本功能用于列举出用户已上传的所有文件
请求地址
GET https://api.moonshot.cn/v1/files
调用示例
file_list = client.files.list()for file in file_list.data: print(file) # 查看每个文件的信息
上传文件
注意,单个用户最多只能上传 1000 个文件,单文件不超过100MB,同时所有已上传的文件总和不超过 10G 容量。如果您要抽取更多文件,需要先删除一部分不再需要的文件。
请求地址
POST https://api.moonshot.cn/v1/files
文件上传成功后,我们会开始抽取文件信息
调用示例
# file 可以是多种类型# purpose 目前只支持 "file-extract"file_object = client.files.create(file=Path("xlnet.pdf"), purpose="file-extract")
删除文件
本功能可以用于删除不再需要使用的文件
请求地址
DELETE https://api.moonshot.cn/v1/files/{file_id}
调用示例
client.files.delete(file_id=file_id)
获取文件信息
本功能用于获取指定文件的文件基础信息
请求地址
GET https://api.moonshot.cn/v1/files/{file_id}
调用示例
client.files.retrieve(file_id=file_id)# FileObject(# id='clg681objj8g9m7n4je0', # bytes=761790, # created_at=1700815879,# filename='xlnet.pdf',# object='file',# purpose='file-extract',# status='ok', status_details='') # status 如果为 error 则抽取失败
获取文件内容
本功能支持获取指定文件的文件抽取结果。通常的,它是一个合法的 JSON 格式的 string,并且对齐了我们的推荐格式。 如需抽取多个文件,您可以在某个 message 中用换行符 \n 隔开,拼接为一个大字符串,role 为 system 的方式加入历史记录。
请求地址
GET https://api.moonshot.cn/v1/files/{file_id}/content
调用示例
# file_content = client.files.retrieve_content(file_id=file_object.id)# type of file_content is `str`# 注意,之前 retrieve_content api 在最新版本标记了 warning, 可以用下面这行代替# 如果是旧版本,可以用 retrieve_contentfile_content = client.files.content(file_id=file_object.id).text# 我们的输出结果目前是一个内部约定好格式的 json, 但是在 message 中应该以 text 格式放进去
计算 Token
请求地址
POST https://api.moonshot.cn/v1/tokenizers/estimate-token-count
请求内容
estimate-token-count 的输入结构体和 chat completion 基本一致。
示例
{ "model": "moonshot-v1-8k", "messages": [ {"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}, {"role": "user", "content": "你好,我叫李雷,1+1等于多少?"} ]}
字段说明
| 字段 | 说明 | 类型 | 取值 |
|---|---|---|---|
| messages | 包含迄今为止对话的消息列表。 | List[Dict] | 这是一个结构体的列表,每个元素类似如下:json{ "role": "user", "content": "你好"} role 只支持 system,user,assistant 其一,content 不得为空 |
| model | Model ID, 可以通过 List Models 获取 | string | 目前是 moonshot-v1-8k,moonshot-v1-32k,moonshot-v1-128k 其一 |
调用示例
curl 'https://api.moonshot.cn/v1/tokenizers/estimate-token-count' \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $MOONSHOT_API_KEY" \ -d '{ "model": "moonshot-v1-8k", "messages": [ { "role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一些涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。" }, { "role": "user", "content": "你好,我叫李雷,1+1等于多少?" } ]}'
返回内容
{ "data": { "total_tokens": 80 },}
当没有 error 字段,可以取 data.total_tokens 作为计算结果
错误说明
下面是主要的几个错误
| Error Type | HTTP Status Code | 详细描述 |
|---|---|---|
| invalid_authentication_error | 401 | 鉴权失败请确认 |
| invalid_request_error | 400 | 这个通常意味着您输入格式有误,包括使用了预期外的参数,比如过大的 temperature,或者 messages 的大小超过了限制。在 message 字段通常会有更多解释 |
| rate_limit_reached_error | 429 | 您超速了。我们设置了最大并发上限和分钟为单位的次数限制。如果在 429 后立即重试,可能会遇到罚时建议控制并发大小,并且在 429 后 sleep 3 秒 |
| exceeded_current_quota_error | 429 | Quota 不够了,请联系管理员加量 |
价格说明
按照实际使用的数据量( 千tokens )收费。Token 在这里指的是文本中的一个最小单位,可以是一个词、一个数字或一个标点符号等。
| 模型 | 计费单位 | 价格 |
|---|---|---|
| moonshot-v1-8k | 1000 tokens | 0.012元 |
| moonshot-v1-32k | 1000 tokens | 0.024元 |
| moonshot-v1-128k | 1000 tokens | 0.06元 |
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。