教你制作AI比奇堡合唱团歌曲翻唱,RVC模型训练教程
普鲁夕格 2024-08-23 17:31:02 阅读 95
前言
随着人工智能技术的飞速发展,音乐创作领域也迎来了新的变革。AI翻唱技术,特别是针对特定风格或组合的翻唱,已经成为音乐制作领域的新宠。本文将带你学习如何使用RVC(Retrieval-based-Voice-Conversion-WebUI )简称 RVC一个基于VITS的简单易用的语音转换(变声器)框架,模型训练出多个角色能够翻唱比奇堡合唱团歌曲的AI模型。
听比奇堡美男团唱硬曲,拒绝emo
模型下载
我训练好的比奇堡声音模型已经上传到模型工坊了。可以自己直接使用,不用训练,直接进行推理。跳转到本文的歌曲推理部分看看。 下载方式在mxgf.cc上搜索对应的模型就可以了,比如痞老板、派大星、海绵宝宝。
为了训练出高度还原比奇堡角色声音的AI模型,首要任务是收集大量的比奇堡声音样本,声音样本的采集工作至关重要,关乎着模型的质量好坏,影响翻唱的效果,声音样本的提取我们可以从官方发布的动画、视频资源中截取,或者寻找高质量的录音资料。在采集过程中,需要确保声音样本的清晰度和纯净度,避免噪音干扰,以保证训练出的模型性能达到最佳。 采集到足够的声音样本后,我们将利用深度学习框架来训练RVC模型。RVC模型是一种基于深度学习的语音处理技术,它通过神经网络学习源声音与目标声音之间的映射关系,实现源声音向目标声音的转换。在本教程中,目标声音即为比奇堡角色的声音。 AI比奇堡声音模型训练与应用 专业级AI比奇堡声音模型训练涉及声音提取、模型训练、歌曲推理和歌曲合成四个关键步骤。
首先,通过手动或自动方法提取比奇堡各个角色的声音样本;接着,利用深度学习框架训练RVC模型,学习并模拟角色声音特征;然后,将模型应用于歌曲推理,结合旋律和节奏生成符合角色特色的歌曲;最后,通过音频编辑软件合成完整的歌曲作品,实现高质量的AI声音模仿与应用。
听不懂术语没关系,我把它分成四部分:1.提取声音 2.训练模型 3.推理歌曲 4.合成歌曲
常用工具下载
1 音频分离工具
链接:https://pan.baidu.com/s/12DWJHR6qRAB3lGQmJckMJw?pwd=mxgf
提取码:mxgf
2 RVC整合包下载
N卡下载 链接:https://pan.baidu.com/s/1Vzvpq_D-NFLL-IpvQtzPlA?pwd=mxgf 提取码:mxgf
A卡下载 https://pan.baidu.com/s/1XDp0dzvDpgqGgHT1r15b2A?pwd=z3oo
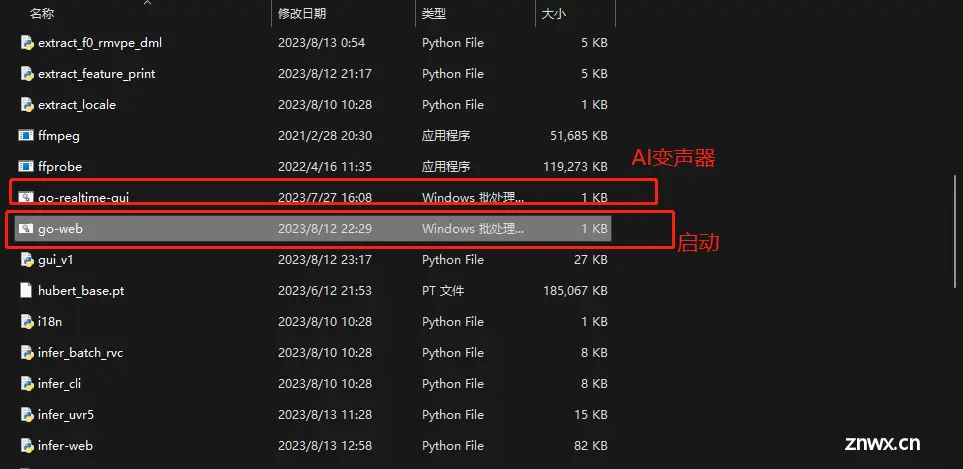
将整合包下载并解压,启动go-web.bat 等待运行
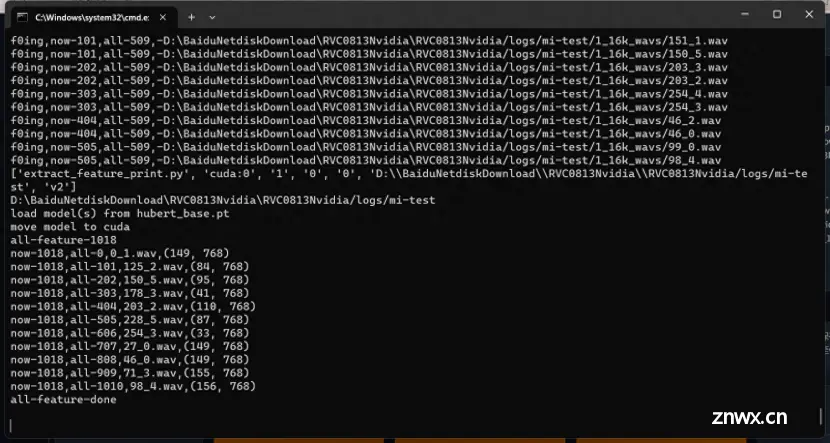
会跳转到浏览器,本地内网地址
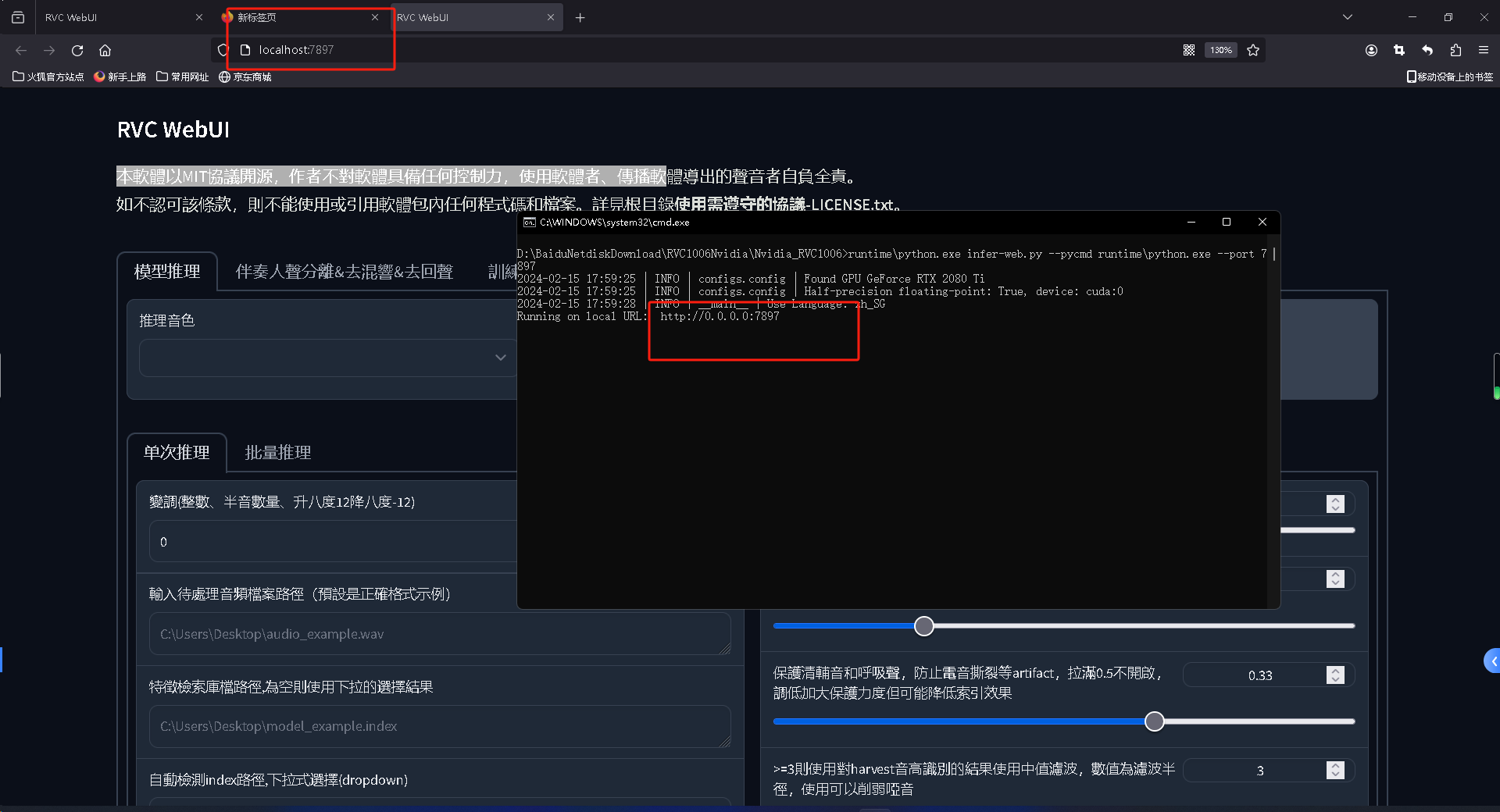
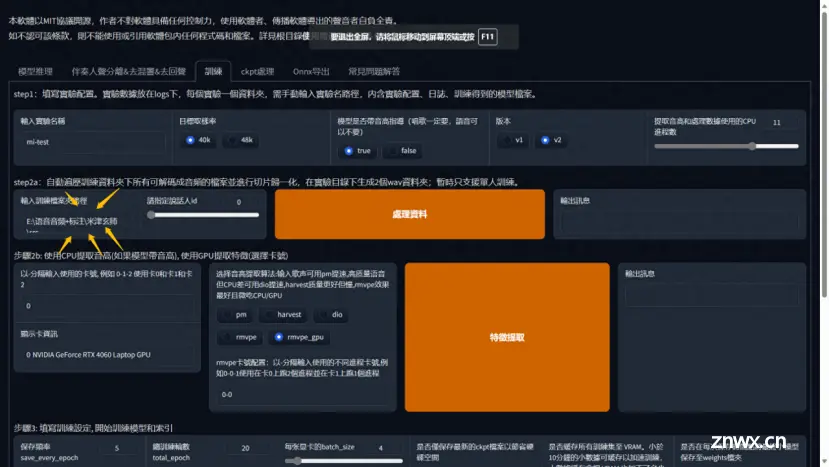
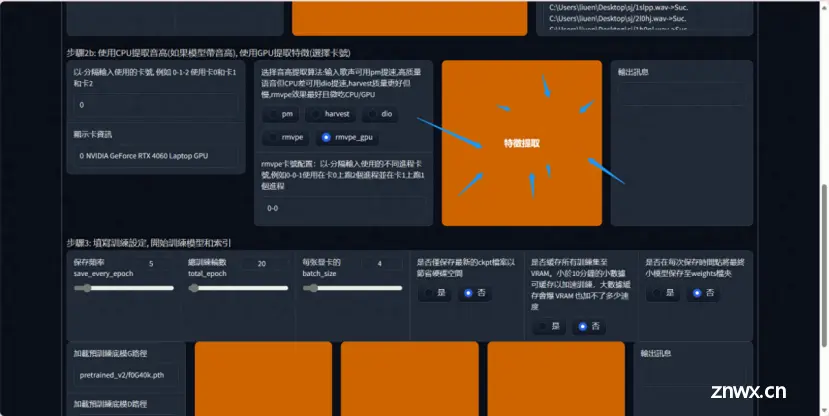
进入训练界面,默认的参数默认就行,不用动

3,输入音频文件夹路径,处理数据
将要训练的的干声数据集放到本地任意英文路径文件夹内复,点击处理数据
处理数据
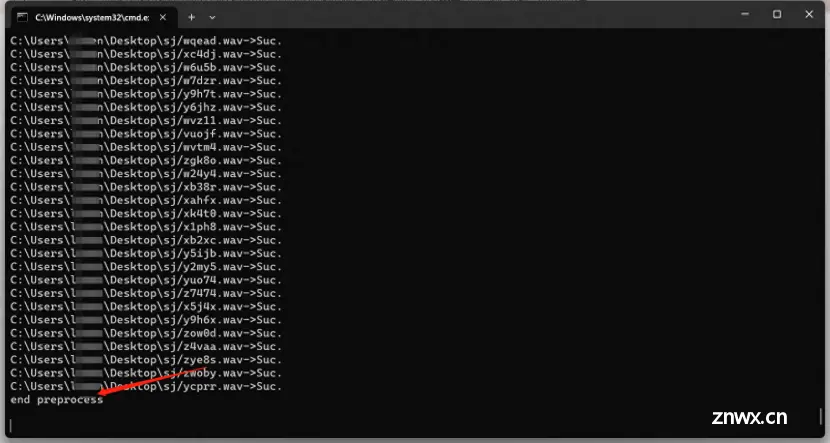
出现 end preprocess 表示处理完毕
特征提取
(特征提取是从声音信号中提取有用信息的过程,这些信息可以被用于训练模型进行分类或识别)
出现 all-feature-done 表示已经处理完毕,可以进行最后一步处理了
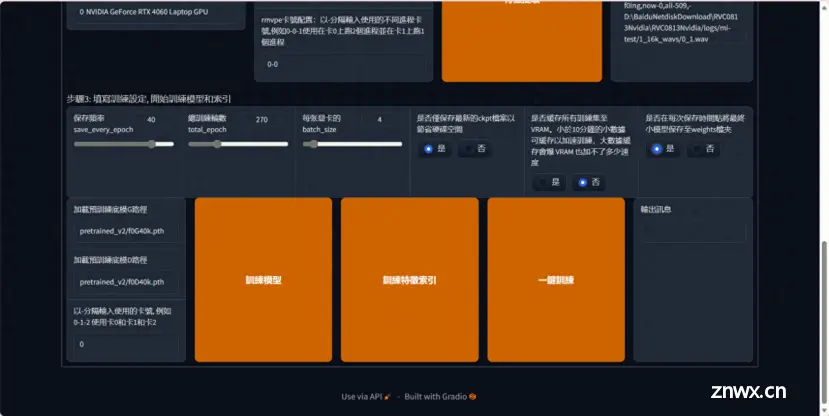
开始训练,设置训练的步数和保存频率

保存頻率 这个数值表示多少轮保存一次模型,如果你的电脑很牛很稳定 50轮也是可以的,不然就推荐 20-40轮保存一次模型
總訓練輪數一般 300轮,模型就可以出炉了
每张显卡的batch_size 如果你的显存是8则填8,显存多少,填多少数值。
点击一键训练
终端显示Epoch: 1字符,表示第一轮,正在训练了
等待几个小时后,就训练结束了,就可以进行下一步,对声音模型进行推理试音了。
三、 歌曲分离/推理
1,歌曲分离
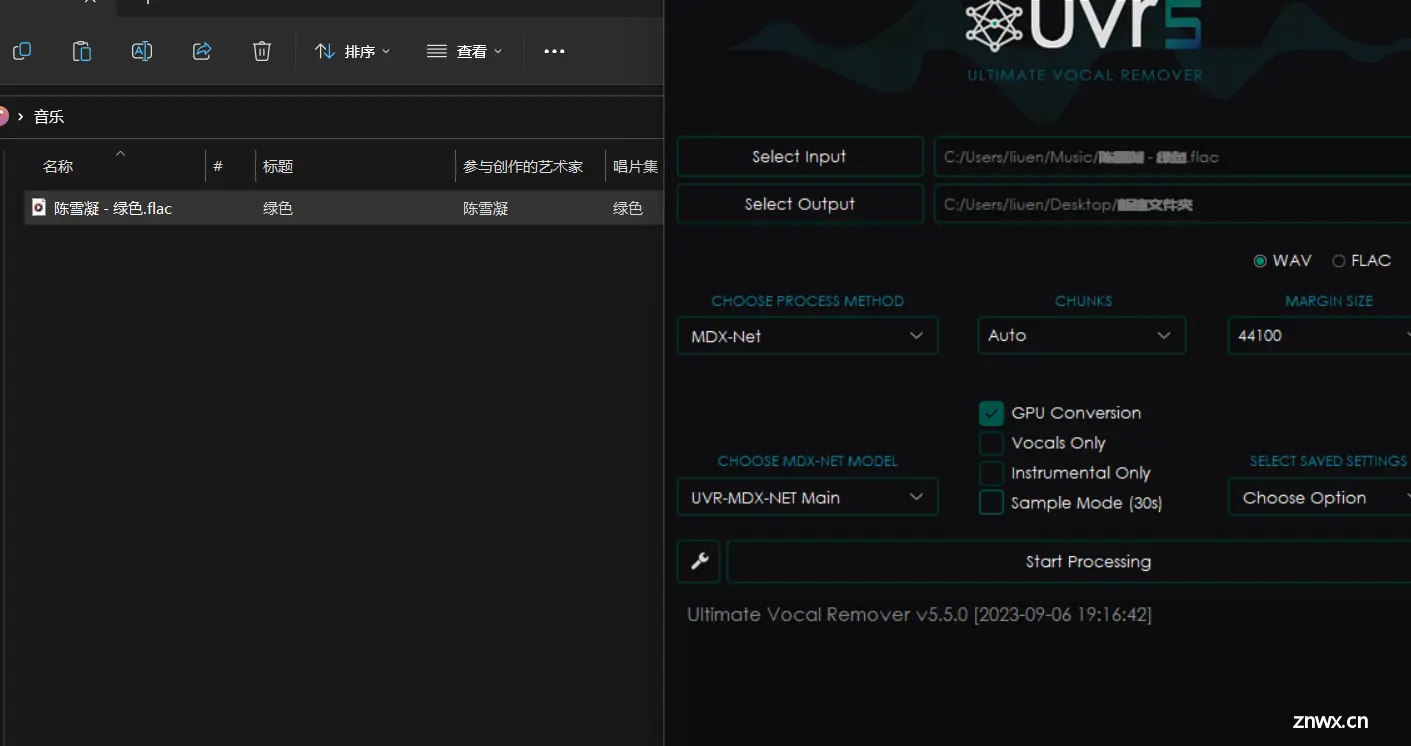
1,准备好歌曲文件,格式包括AAC,FLAC等主流声音格式,但不包括加密格式,比如网易云加密歌曲,酷狗,qq音乐。
2,将歌曲文件放到UVR 5,进行分离,分离的目的是 把伴奏和人声抽离出来

处理完成之后会得到两个音频文件
1_陈雪凝 - 绿色_(Instrumental) 伴奏
1_陈雪凝 - 绿色_(Vocals) 人声
等下推理时候会用到 这个 _(Vocals) 人声部分
注:
模型要记得选择 MDX-NET UVR-MDX-NET Main
处理模型下载
百度网盘 请输入提取码
将下载好的模型,放到UVR根目录下面的models文件夹下
如果分离过程中出现报错,可能原因是显存或内存不足,尝试重启电脑
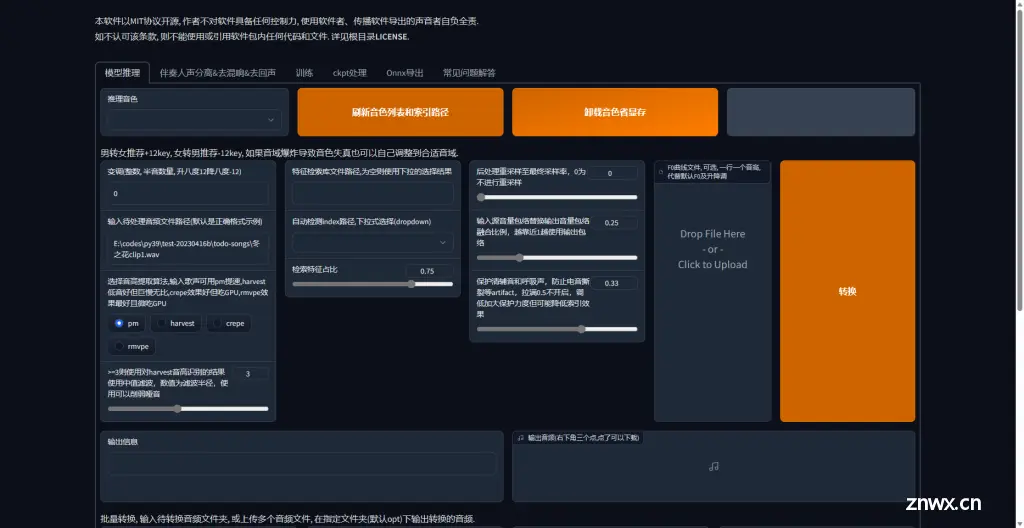
2,歌曲推理
打开整合包
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
百度网盘 请输入提取码
下载之后,解压
版本说明
下载RVC0813AMD_Intel包可解锁A卡I卡
(1)双击go-realtime-gui-dml.bat使用实时变声,A卡大概能压到300ms左右,以下有压力
(2)双击go-web-dml.bat使用训练推理(CPU训练)
N卡用户下载RVC0813Nvidia
(1)双击go-realtime-gui.bat使用实时变声,N卡大概能压到100ms左右,以下有压力
双击go-web.bat使用训练推理
选择合适自己的显卡下载
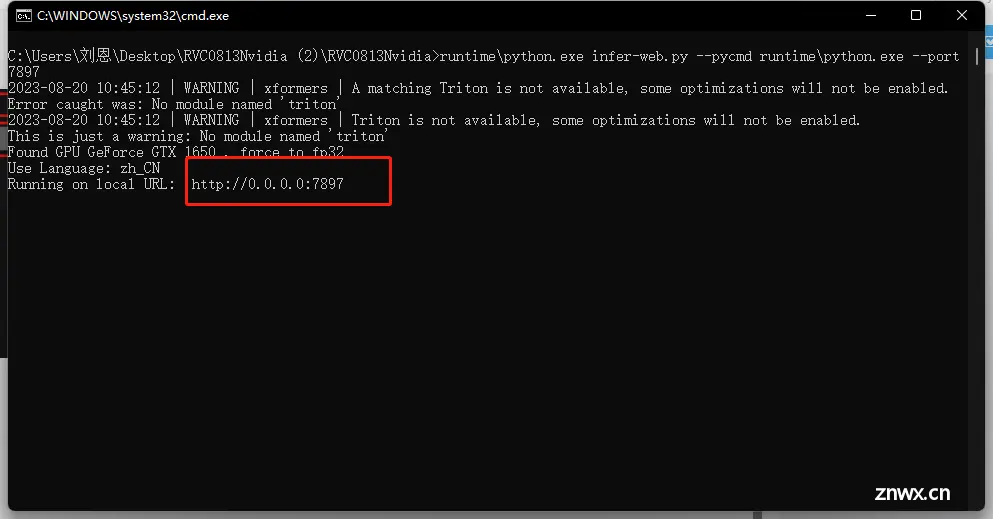
等待启动,出现地址,表示启动成功
启动成功会自动跳转WEBUI

将模型放置到目录(训练好的,忽略这一步)
刷新音色,然后按顺序进行推理
解疑
音频地址
WIN11 鼠标右击可以快速复制地址,复制的地址前后如果带有双引号记得删除”“
WIN10 需要将声音文件放到 任意文件夹内,按shift+鼠标右键 选择复制路径

四、歌曲合成
所需工具 AU 链接:百度网盘-链接不存在
解压密码 @vposy
1,转换后的歌曲人声下载到桌面
2,使用AU将伴奏和转换后的人声合并
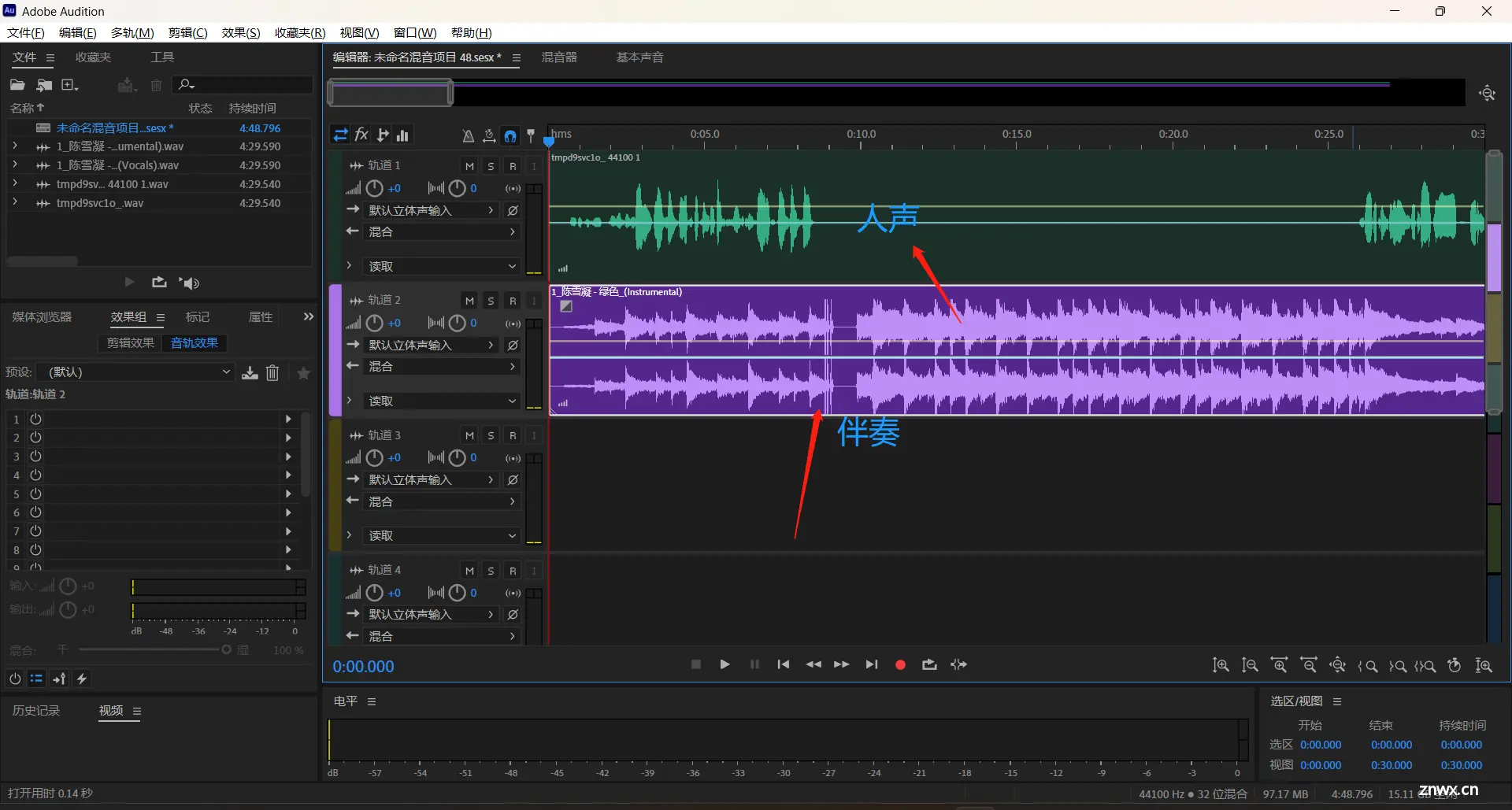
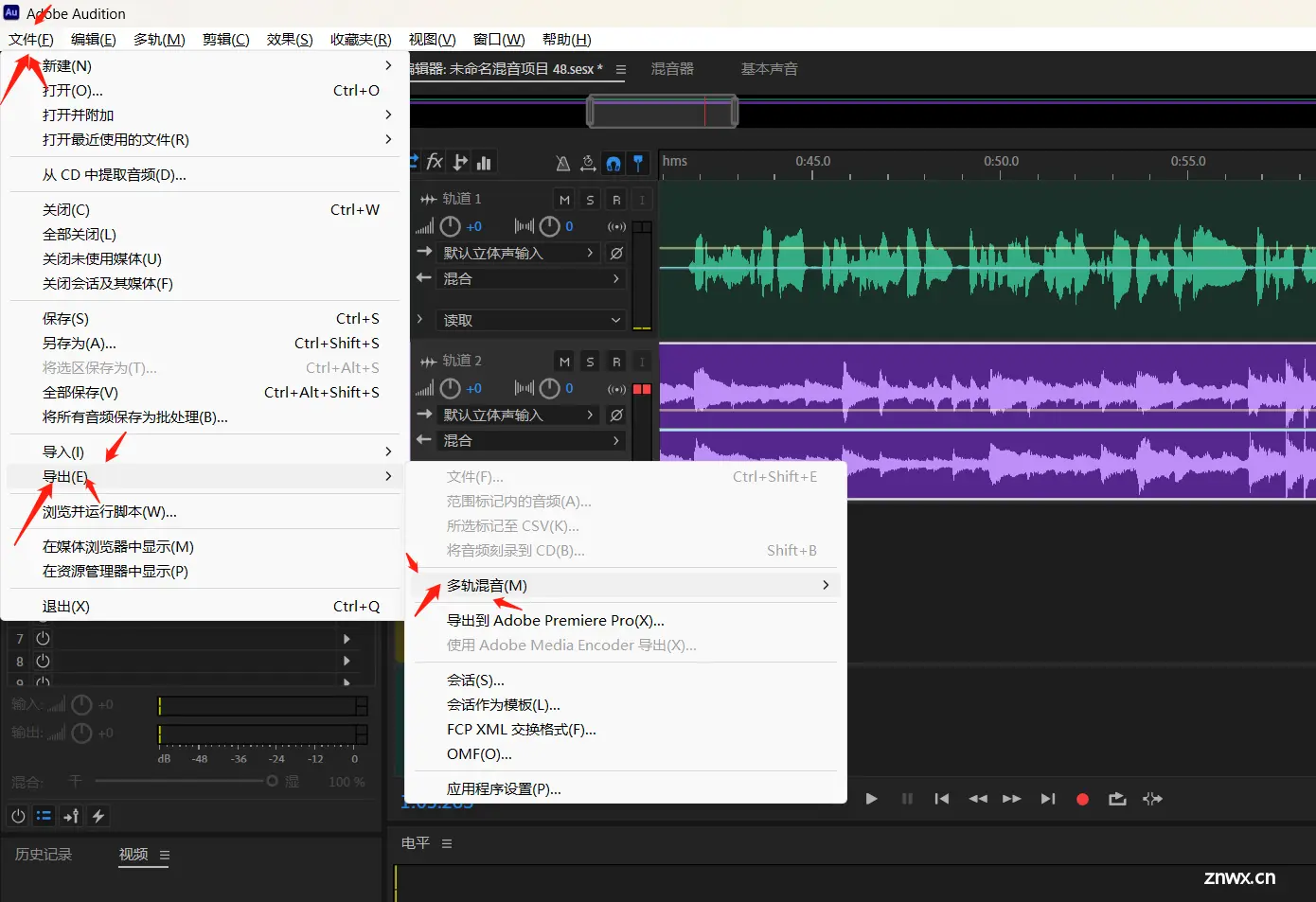
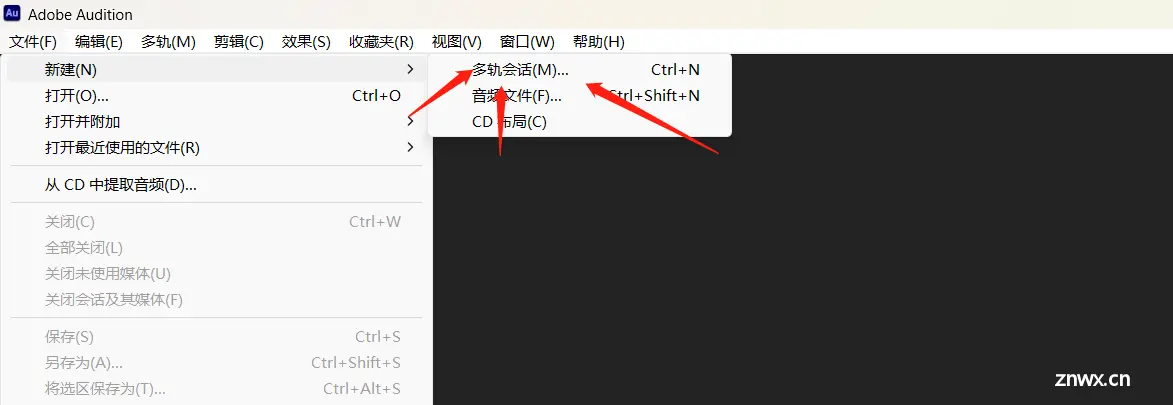
首先新建多轨会话,将转换的人声和伴奏拉进AU
导出

教程结束,教程写的有点乱,多多包涵,有什么不懂的下方留言。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。