用pytorch实现LeNet-5网络
mofeisite 2024-08-18 08:13:00 阅读 81
上篇讲述了LeNet-5网络的理论,本篇就试着搭建LeNet-5网络。但是搭建完成的网络还存在着问题,主要是训练的准确率太低,还有待进一步探究问题所在。是超参数的调节有问题?还是网络的结构有问题?还是哪里搞错了什么
1.库的导入
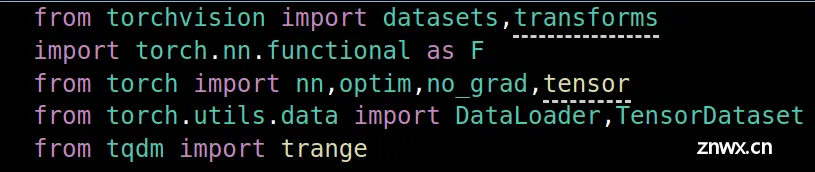
- <li>dataset: datasets.MNIST()函数,该函数作用是导入MNIST数据库,以供后续使用。
- torch.nn.functional() 主要是用到了F.relu(),relu激活函数。
- nn.Linear() , nn.MaxPool2d() , nn.Conv2d(),起到构建卷积神经网络各隐藏层的函数。
- optim:模块扮演着优化算法的角色,它提供了多种优化算法的实现,用于更新和调整模型中的参数(即权重和偏置),以最小化或最大化某个损失函数(通常是最小化)。这些优化算法是深度学习训练过程中不可或缺的一部分,因为它们决定了模型如何根据损失函数的梯度来更新其参数,从而逐步改进模型的性能。
optim.Adam() :一种基于梯度下降的优化算法,结合了AdaGrad和RMSProp两种优化算法的思想,具有计算高效、内存需求小、适合解决大规模和高维空间优化问题的优点。
- no_grad: no_grade()关闭自动向求导,主要是在对网络进行测试时,起到加快模型速度和减小内存的作用。
- DataLoader:起到对数据集进行分组的作用,在训练模型时,并不是把训练集中的所有样本加载到X中去,而是把样本分批次进行计算,在多批次后完成对训练集中样本的遍历,也叫做一个周期。
- TensorDataset:起到将张量Tensor组成pytorch能够处理的数据组,因为pytorch能够处理的数据组都要继承nn.model()
- trange:整体类似于range(),但不同之处在于每次epoch时会有一个进度条
2.程序的整体框架
程序由以下三部分组成:
3.数据集的建构
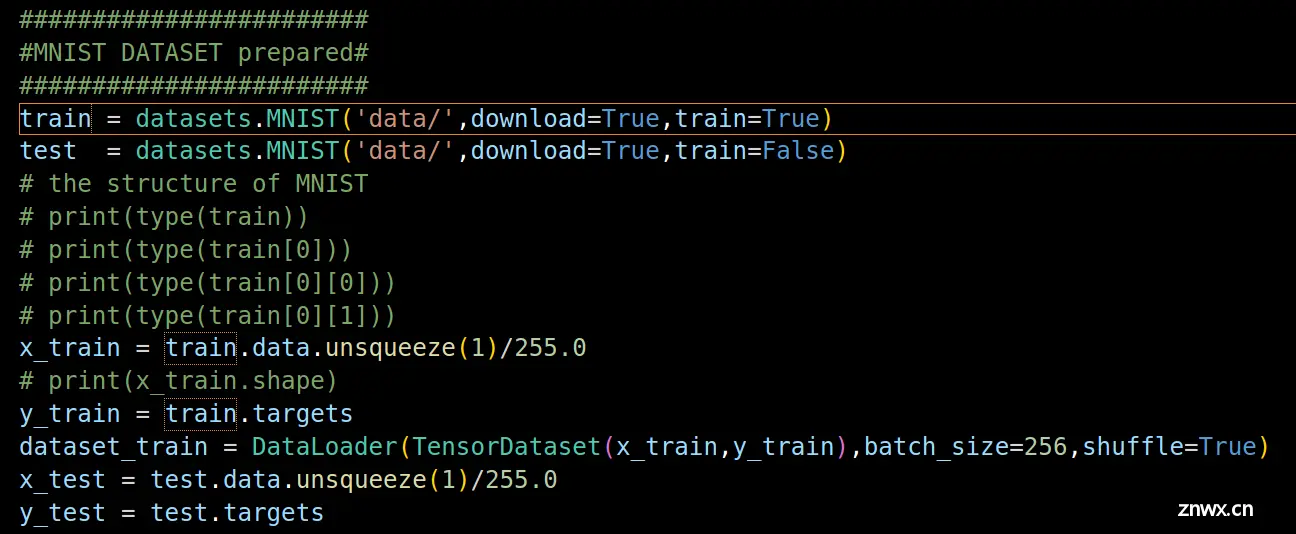
函数<code>datasets.MNIST()起到下载数据集的作用。第一个形式参数是确定下载的数据存放的根文件,第二个形式参数download作用是判断是否需要从目标源下载数据,若download=True则代表若程序在目标文件夹没有找到MNIST数据集则会从目标源上下载数据集,若download=False则不会下载。第三个参数判断下载的是训练集还是验证集。若train=True代表下载的是训练集,若train=False则代表下载的是训练集。
代码x_train = train.data.unsqueeze(1)/255.0实现的功能是给数据集增加一个维度。具体来说该步将原本的数据集样式:样本数x数据高度x数据宽度转变为样本数x数据通道数x数据高度x数据宽度。而/255.0实现的是将数据归一化的操作。
x_train和y_train格式为torch.tensor。
dataset_train = DataLoader(TensorDataset(x_train,y_train),batch_size=256,shuffle=True)该代码由两个函数嵌套而成,第一个为 TensorDataset(x_train,y_train) 该函数的作用为将两个张量合成一个数据集,直接用TensorDataset()是一种简单的方法。还有一种方法是构建数据类,继承于Dataset数据基类。第二个为DataLoader()该函数的作用为将一个大的训练集拆分成若干小的训练集,再逐个进行训练。<code>batch_size=256参数确定了划分的小样本集的规模为256个样本,shuffle=True作用是在样本选择时采用随机采样的方式。
3.模型的构建

在pytorch中,建构一个模型,需要创建一个继承nn.Module类的子类,并且要对子类中的两个函数<code>__init__()和forward()进行重写。在LeNet_5Model的模型定义中,初始化函数定义了卷积层,池化层和线性层,在前向传播函数中定义了网络的结构。x.view()方法和numpy中的reshape类似,都是改变数据类型的内部结构。
nn.Conv2d(1,6,5)其中第一个参数是输入的通道数;第二个参数是输出通道数;第三个参数是卷积核的规模。
4.模型的使用

首先实现的是模型、优化器、损失函数的实例化,优化器采用的是<code>Adam(),损失函数采用的是交叉熵函数。
with no_grad():实现关闭模型自动求导功能,不仅降低了模型的运算时间,而且减少了内存消耗。
acc_train = (train_preds.argmax(dim=1) == y_train).float().mean().item()
- <li>train_preds:这是一个张量(Tensor),包含了模型对训练集样本的预测结果。假设这是一个分类问题,train_preds的形状可能是[batch_size, num_classes],其中batch_size是批次大小,num_classes是类别的数量。每个样本的预测结果是一个长度为num_classes的向量,向量中的每个元素代表该样本属于对应类别的概率(尽管这里可能不是直接的概率值,而是某种形式的得分,如未经过softmax归一化的logits)。
- train_preds.argmax(dim=1):这个操作沿着dim=1(即类别的维度)查找每个样本预测概率最高的类别的索引。argmax函数会返回每个样本预测概率最高的类别的索引,因此结果是一个形状为[batch_size]的张量,包含了每个样本预测类别的索引。
- == y_train:这里将预测类别的索引与真实的标签y_train进行比较。y_train是一个形状为[batch_size]的张量,包含了每个样本的真实类别索引。比较的结果是一个布尔张量,其中的每个元素都是True(如果预测正确)或False(如果预测错误)。
- .float():将布尔张量转换为浮点张量,这样True会被转换为1.0,False会被转换为0.0。
- .mean():计算张量中所有元素的平均值。由于张量中的元素是0.0或1.0,这个平均值实际上就是准确率:正确预测的样本数除以总样本数。
- .item():将得到的平均值(一个标量Tensor)转换为Python的数值类型(通常是float),以便在Python代码中使用。
综上所述,acc_train = (train_preds.argmax(dim=1) == y_train).float().mean().item()这行代码计算了模型在训练集上的准确率,并将结果存储在变量acc_train中。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。