AI大模型探索之路-实战篇12: 构建互动式Agent智能数据分析平台:实现多轮对话控制
CSDN 2024-06-12 15:01:23 阅读 82
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
AI大模型探索之路-实战篇10:数据预处理的艺术:构建Agent智能数据分析平台的基础
AI大模型探索之路-实战篇11: Function Calling技术整合:强化Agent智能数据分析平台功能
目录
系列篇章💥一、前言二、引入背景知识库1、定义OpenAI客户端2、定义工具函数生成器3、两次大模型API调用封装4、user_demographics数据查询服务封装5、user_demographics函数信息生成测试6、第一次数据查询对话测试7、读取数据字典8、第二次数据查询对话测试9、数据库基本信息查询测试10、数据分析调用测试 三、实现交互确认1、定义数据库基本信息获取函数2、函数信息生成测试检查:3、数据分析测试4、定义SQL提取函数5、两次次大模型API两次调用封装改造6、定义消息列表7、数据查询分析测试18、数据查询分析测试29、数据查询分析测试3 四、实现完整的多轮对话效果五、结语
一、前言
在Agent智能数据分析平台的实战开发中,继我们之前关于Function Calling技术整合的讨论之后,本文将专注于实现一个核心功能——多轮对话控制系统。这一机制能够让用户通过自然语言与系统进行连续的交流,从而更准确、更高效地完成数据分析任务。
二、引入背景知识库
引入数据字典知识,作为大模型对话的背景知识库。
1、定义OpenAI客户端
定义大模型客户端,用于与大模型交互对话
import openaiimport osimport numpy as npimport pandas as pdimport jsonimport iofrom openai import OpenAIimport inspectimport pymysqlopenai.api_key = os.getenv("OPENAI_API_KEY")client = OpenAI(api_key=openai.api_key)
2、定义工具函数生成器
定义一个函数,用于自动生成function calling功能需要的,工具函数信息体
def auto_functions(functions_list): """ Chat模型的functions参数编写函数 :param functions_list: 包含一个或者多个函数对象的列表; :return:满足Chat模型functions参数要求的functions对象 """ def functions_generate(functions_list): # 创建空列表,用于保存每个函数的描述字典 functions = [] # 对每个外部函数进行循环 for function in functions_list: # 读取函数对象的函数说明 function_description = inspect.getdoc(function) # 读取函数的函数名字符串 function_name = function.__name__ system_prompt = '以下是某的函数说明:%s' % function_description user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\ 1.字典总共有三个键值对;\ 2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\ 3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\ 4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\ 5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_name response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ { "role": "system", "content": system_prompt}, { "role": "user", "content": user_prompt} ] ) json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json","")) json_str={ "type": "function","function":json_function_description} functions.append(json_str) return functions max_attempts = 4 attempts = 0 while attempts < max_attempts: try: functions = functions_generate(functions_list) break # 如果代码成功执行,跳出循环 except Exception as e: attempts += 1 # 增加尝试次数 print("发生错误:", e) if attempts == max_attempts: print("已达到最大尝试次数,程序终止。") raise # 重新引发最后一个异常 else: print("正在重新运行...") return functions
3、两次大模型API调用封装
封装funcation calling中两次大模型API得调用
def run_conversation(messages, functions_list=None, model="gpt-3.5-turbo"): """ 能够自动执行外部函数调用的对话模型 :param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象 :param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象 :param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo :return:Chat模型输出结果 """ # 如果没有外部函数库,则执行普通的对话任务 if functions_list == None: response = client.chat.completions.create( model=model, messages=messages, ) response_message = response.choices[0].message final_response = response_message.content # 若存在外部函数库,则需要灵活选取外部函数并进行回答 else: # 创建functions对象 tools = auto_functions(functions_list) # 创建外部函数库字典 available_functions = { func.__name__: func for func in functions_list} # 第一次调用大模型 response = client.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice="auto", ) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: messages.append(response_message) for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) function_response = function_to_call(**function_args) messages.append( { "tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": function_response, } ) ## 第二次调用模型 second_response = client.chat.completions.create( model=model, messages=messages, ) # 获取最终结果 final_response = second_response.choices[0].message.content else: final_response = response_message.content return final_response
4、user_demographics数据查询服务封装
定义一个get_user_demographics函数,用于获取user_demographics 表的相关信息
def get_user_demographics(sql_query): """ 用户获取user_demographics 表的相关信息 :param sql_query: 字符串形式的SQL语句 :return SQL查询的user_demographics 表的相关信息 """ mysql_pw="iquery_agent" connection = pymysql.connect( host='localhost', # 数据库地址 user='iquery_agent', # 数据库用户名 passwd=mysql_pw, # 数据库密码 db='iquery', # 数据库名 charset='utf8' # 字符集选择utf8 ) try: with connection.cursor() as cursor: sql = sql_query cursor.execute(sql) results = cursor.fetchall() finally: cursor.close() column_names = [desc[0] for desc in cursor.description] # 使用results和column_names创建DataFrame df = pd.DataFrame(results, columns=column_names) return df.to_json(orient = "records")
5、user_demographics函数信息生成测试
使用工具函数生成器,对测试是否能够正常生成user_demographics相关数据查询的工具函数信息
#定义工具函数列表(当前只有user_demographics信息获取的函数)functions_list = [get_user_demographics]#user_demographics相关数据查询的工具函数信息,生成测试tools = auto_functions(functions_list)tools
生成的函数信息如下:

注意:结构生成不一定正确,大模型缺少稳定性;可能需要多次调用测试;也可以再生成函数中,加入校验;比如:如果缺失关键key、value,就让大模型重新生成。
6、第一次数据查询对话测试
使用自然语言对话的方式,进行数据查询分析
messages=[ { "role": "user", "content": "请问user_demographics表中个人属性为老年男性的数据总共有多少条?"} ] response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", )response.choices[0].message
输出:
ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_5VK3ywSsn76wNBfAEc17FaWr', function=Function(arguments='{"sql_query":"SELECT COUNT(*) FROM user_demographics WHERE age >= 60 AND gender = \'male\'"}', name='get_user_demographics'), type='function')])
可以从结果中检查大模型是否正常找到自己生成的工具函数,以及生成的相关SQL是否正确;
查询SQL中使用了年龄大于60岁,来查询老年人。
7、读取数据字典
读取本地的数据字典
# 打开并读取Markdown文件with open('/root/autodl-tmp/iquery项目/data/数据字典/iquery数据字典.md', 'r', encoding='utf-8') as f: md_content = f.read() md_content
输出
'# iquery数据字典:iquery数据库数据字典\n\n本数据字典记录了iquery数据库中各张数据表的基本情况。\n\n## 1.user_demographics数据表\n\n- 基本解释\n\n \u200b\t\tuser_demographics数据表记录了电信用户的个人基本情况,主要涵盖客户基本生物属性,包括性别、年龄状况、是否结婚以及是否经济独立等。\n\n- 数据来源\n\n \u200b\tuser_demographics数据集由一线业务人员人工采集记录,并且通过回访确认相关信息,数据集的准确性和可信度都非常高。\n\n- 各字段说明\n\n| Column Name | Description | Value Range | Value Explanation | Type |\n|-------------|-------------|-------------|-------------------|------|\n| customerID | 客户ID,user_demographics数据表主键 | | 由数字和字母组成的 | VARCHAR(255) |\n| gender | 用户的性别 | Female, Male | Female (女性), Male (男性) | VARCHAR(255) |\n| SeniorCitizen | 是否为老人 | 0, 1 | 0 (不是), 1 (是) | INT |\n| Partner | 用户是否有伴侣 | Yes, No | Yes (有), No (没有) | VARCHAR(255) |\n| Dependents | 用户经济是否独立,往往用于判断用户是否已经成年 | No, Yes | Yes (有), No (没有) | VARCHAR(255) |\n\n## 2.user_services数据表\n\n- 基本解释\n\n \u200b user_services数据表记录了每位用户订购电信服务的基本情况,截至目前,电信服务商提供了种类多样的服务,包括电话类服务和网络类服务等,本数据集表记录了每位用户订阅电信服务的基本情况。\n\n- 数据来源\n\n \u200b\t\tuser_services数据表由后台系统自动创建生成,并未经过人工校验。\n\n- 各字段说明\n\n| Column Name | Description | Value Range | Value Explanation | Type |\n|-------------|-------------|-------------|-------------------|------|\n| customerID | 客户ID,user_services数据表主键 | | 由数字和字母组成的 | VARCHAR(255) |\n| PhoneService | 用户是否有电话服务 | No, Yes | Yes (有), No (没有) | VARCHAR(255) |\n| MultipleLines | 用户是否开通了多条电话业务 | No phone service, No, Yes | Yes (有多条电话线业务), No (没有多条电话线业务), No phone service (没有电话服务) | VARCHAR(255) |\n| InternetService | 用户的互联网服务类型 | DSL, Fiber optic, No | DSL (DSL), Fiber optic (光纤), No (没有) | VARCHAR(255) |\n| OnlineSecurity | 是否开通网络安全服务 | No, Yes, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n| OnlineBackup | 是否开通在线备份服务 | Yes, No, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n| DeviceProtection | 是否开通设备保护服务 | No, Yes, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n| TechSupport | 是否开通技术支持业务 | No, Yes, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n| StreamingTV | 是否开通网络电视 | No, Yes, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n| StreamingMovies | 是否开通网络电影 | No, Yes, No internet service | Yes(有)、No(无) or No internetservice(没有网路服务) | VARCHAR(255) |\n\n## 3.user_payments数据表\n\n- 基本解释\n\n \u200b\t\tuser_payments数据表记录了每一位用户支付状况,既包括用户的支付方式和合同类型,同时也包含用户具体支付金额,包括月付金额和总金额等。\n\n- 数据来源\n\n \u200b\t\tuser_payments数据表由后台自动记录生成,并未经过校验。\n\n- 各字段说明\n\n| Column Name | Description | Value Range | Value Explanation | Type |\n|-------------|-------------|-------------|-------------------|------|\n| customerID | 客户ID,user_payments数据表主键 | | 由数字和字母组成的 | VARCHAR(255) |\n| Contract | 合同类型 | Month-to-month, One year, Two year | Month-to-month (月付), One year (一年付), Two year (两年付) | VARCHAR(255) |\n| PaperlessBilling | 是否无纸化账单 | Yes, No | Yes (是), No (否) | VARCHAR(255) |\n| PaymentMethod | 支付方式 | Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic) | Electronic check (电子检查), Mailed check (邮寄支票), Bank transfer (automatic) (银行转账), Credit card (automatic) (信用卡) | VARCHAR(255) |\n| MonthlyCharges | 月费用 | | 用户平均每月支付费用 | FLOAT |\n| TotalCharges | 总费用 | | 截至目前用户总消费金额 | VARCHAR(255) |\n\n## 4.user_churn\n\n- 基本解释\n\n \u200b\t\tuser_churn数据表记录了当前用户流失情况。\n\n- 数据来源\n\n \u200b\t\tuser_churn数据表由后台自动创建并记录,当合同截至后但用户未续费,则判断该用户目前处于流失状态。\n\n- 各字段说明\n\n| Column Name | Description | Value Range | Value Explanation | Type |\n|-------------|-------------|-------------|-------------------|------|\n| customerID | 客户ID,user_churn数据表主键 | | 由数字和字母组成的 | VARCHAR(255) |\n| Churn | 用户是否流失 | No, Yes | Yes (是), No (否) | VARCHAR(255) |\n\n'
8、第二次数据查询对话测试
将数据字典作为背景知识,再次使用自然语言对话的方式,进行数据查询分析
messages=[ { "role": "system", "content": md_content}, { "role": "user", "content": "请问user_demographics表中个人属性为老年男性的数据总共有多少条?"}]response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, tools=tools, tool_choice="auto", )response.choices[0].message
输出:
ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_e4LEDDcytWdGUx0m98plDpUa', function=Function(arguments='{"sql_query":"SELECT * FROM user_demographics WHERE SeniorCitizen = 1 AND gender = \'Male\'"}', name='get_user_demographics'), type='function')])
通过输出结果可以看到,这一次数据查询中使用了SeniorCitizen 字段,因为背景知识中,这个字段是用来标识老人的,不需要通过年龄判断。

9、数据库基本信息查询测试
调用大模型API查询数据库的基本情况信息
messages=[ { "role": "system", "content": md_content}, { "role": "user", "content": "请帮我介绍下iquery这个数据库的基本情况"}]response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, )response.choices[0].message.content
输出:
'iquery数据库是一个用于电信用户数据分析的数据库,主要包括了四张数据表:user_demographics、user_services、user_payments和user_churn。这些数据表记录了电信用户的个人基本情况、订购的电信服务情况、支付情况以及流失情况。用户可以通过iquery数据库中的数据来进行用户行为分析、用户流失预测、产品定价优化等工作。每张数据表都有各自的字段说明,方便用户了解和利用数据库中的数据。'
10、数据分析调用测试
让大模型帮忙分析user_demographics数据表和user_services数据表的数据可信度。
messages=[ { "role": "system", "content": md_content}, { "role": "user", "content": "user_demographics数据表和user_services数据表哪张表的数据可信度更高呢?"}]response = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, )print(response.choices[0].message.content)
输出:
根据描述,user_demographics数据表由一线业务人员人工采集记录,并通过回访确认相关信息,数据集的准确性和可信度都非常高。而user_services数据表由后台系统自动生成,并未经过人工校验。因此,user_demographics数据表的数据可信度更高。
三、实现交互确认
在数据查询分析前,让大模型输出将要执行的SQL,让用户确认检查;同时咨询是否需要执行
1、定义数据库基本信息获取函数
定义一个获取数据库基本信息的工具函数
def sql_inter(sql_query): """ 用于获取iquery数据库中各张表的有关相关信息,\ 核心功能是将输入的SQL代码传输至iquery数据库所在的MySQL环境中进行运行,\ 并最终返回SQL代码运行结果。需要注意的是,本函数是借助pymysql来连接MySQL数据库。 :param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中iquery数据库中各张表进行查询,并获得各表中的各类相关信息 :return:sql_query在MySQL中的运行结果。 """ mysql_pw = "iquery_agent" connection = pymysql.connect( host='localhost', # 数据库地址 user='iquery_agent', # 数据库用户名 passwd=mysql_pw, # 数据库密码 db='iquery', # 数据库名 charset='utf8' # 字符集选择utf8 ) try: with connection.cursor() as cursor: # SQL查询语句 sql = sql_query cursor.execute(sql) # 获取查询结果 results = cursor.fetchall() finally: connection.close() return json.dumps(results)
2、函数信息生成测试检查:
#定义工具函数列表functions_list = [sql_inter]#工具函数信息生成tools = auto_functions(functions_list)tools
输出:

检查生成的函数信息结构是否正确,是否有缺失的key、value
3、数据分析测试
messages = [ { "role": "system", "content": md_content}, { "role": "user", "content": "请问user_demographics数据表的主键和user_services数据表的主键是否完全一致?"}]run_conversation(messages, functions_list=functions_list, model="gpt-3.5-turbo")
输出:

4、定义SQL提取函数
def extract_sql(json_str): # 提取并返回'sql_query'的值 return json_str.get('sql_query', None)
5、两次次大模型API两次调用封装改造
改造二次大模型API两次调用的封装函数,引入用户确认的逻辑
def check_code_run(messages, functions_list=None, model="gpt-3.5-turbo",auto_run = True): """ 能够自动执行外部函数调用的对话模型 :param messages: 必要参数,字典类型,输入到Chat模型的messages参数对象 :param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象 :param model: Chat模型,可选参数,默认模型为gpt-3.5-turbo :return:Chat模型输出结果 """ # 如果没有外部函数库,则执行普通的对话任务 if functions_list == None: response = client.chat.completions.create( model=model, messages=messages, ) response_message = response.choices[0].message final_response = response_message.content # 若存在外部函数库,则需要灵活选取外部函数并进行回答 else: # 创建functions对象 tools = auto_functions(functions_list) # 创建外部函数库字典 available_functions = { func.__name__: func for func in functions_list} # 第一次调用大模型 response = client.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice="auto", ) response_message = response.choices[0].message tool_calls = response_message.tool_calls if tool_calls: messages.append(response_message) for tool_call in tool_calls: function_name = tool_call.function.name function_to_call = available_functions[function_name] function_args = json.loads(tool_call.function.arguments) if auto_run == False: sql_query = extract_sql(function_args) res = input('即将执行以下代码:%s。是否确认并继续执行(1),或者退出本次运行过程(2)' % sql_query) if res == '2': print("终止运行") return None else: print("正在执行代码,请稍后...") function_response = function_to_call(**function_args) messages.append( { "tool_call_id": tool_call.id, "role": "tool", "name": function_name, "content": function_response, } ) ## 第二次调用模型 second_response = client.chat.completions.create( model=model, messages=messages, ) # 获取最终结果 final_response = second_response.choices[0].message.content else: final_response = response_message.content del messages return final_response
6、定义消息列表
messages = [ { "role": "system", "content": md_content}, { "role": "user", "content": "请问iquery数据库下user_demographics表的第10条数据内容是?"}]#函数列表查看functions_list

7、数据查询分析测试1
check_code_run(messages, functions_list=functions_list, model="gpt-3.5-turbo", auto_run = False)
输出:

8、数据查询分析测试2
messages = [ { "role": "system", "content": md_content}, { "role": "user", "content": "请问iquery数据库下user_demographics表有多少条数据?"}]check_code_run(messages, functions_list=functions_list, model="gpt-3.5-turbo", auto_run = False)
输出:

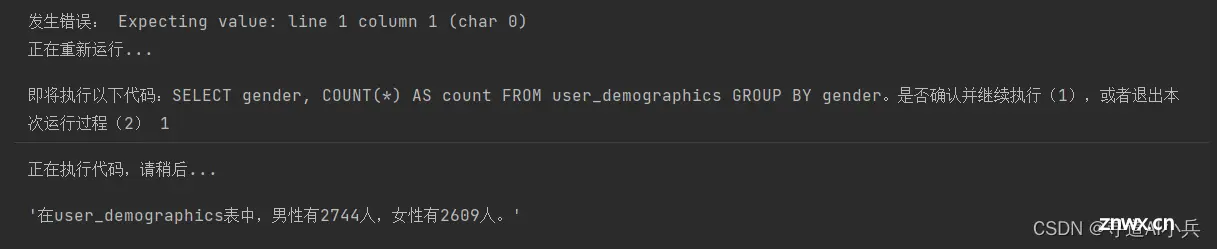
9、数据查询分析测试3
messages = [ { "role": "system", "content": md_content}, { "role": "user", "content": "请问iquery数据库下user_demographics表中,男性和女性的分别有多少人"}]check_code_run(messages, functions_list=functions_list, model="gpt-3.5-turbo", auto_run = False)
输出:
四、实现完整的多轮对话效果
经过上述步骤的不断优化和测试,我们最终实现了一个完整的多轮对话控制系统。该系统不仅能够理解用户的查询意图,还能够在需要时向用户确认信息,从而使得整个数据分析过程更加透明、可控。
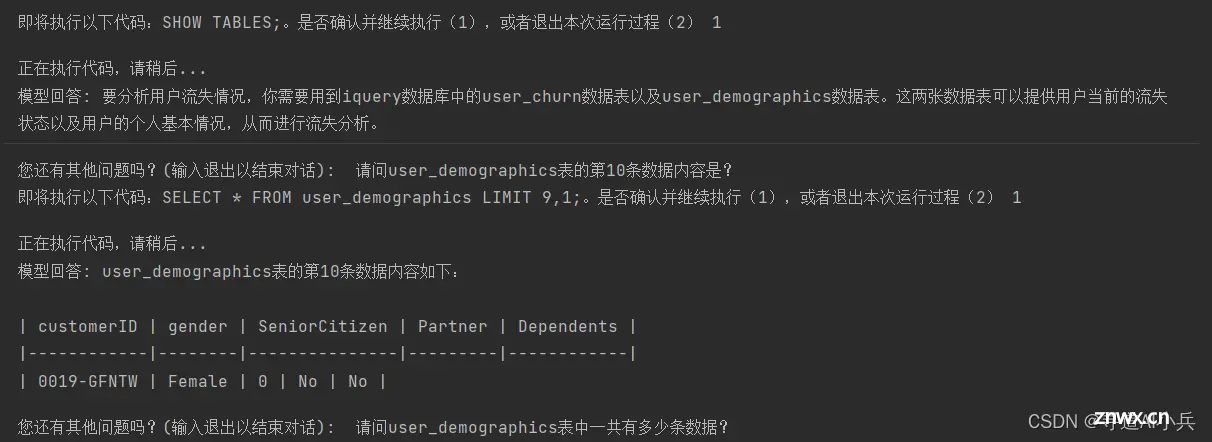
import tiktokendef chat_with_inter(functions_list=None, prompt="你好呀", model="gpt-3.5-turbo", system_message=[{ "role": "system", "content": "你是一个智能助手。"}], auto_run = True): # 创建函数列表对应的参数解释列表 functions = auto_functions(functions_list) # 多轮对话阈值 if 'gpt-4' in model: tokens_thr = 6000 elif '16k' in model: tokens_thr = 14000 else: tokens_thr = 3000 messages = system_message messages.append({ "role": "user", "content": prompt}) ## 计算token大小 embedding_model = "text-embedding-ada-002" # 模型对应的分词器(TOKENIZER) embedding_encoding = "cl100k_base" encoding = tiktoken.get_encoding(embedding_encoding) tokens_count = len(encoding.encode((prompt + system_message[0]["content"]))) while True: answer = check_code_run(messages, functions_list=functions_list, model=model, auto_run = auto_run) print(f"模型回答: { answer}") # 询问用户是否还有其他问题 user_input = input("您还有其他问题吗?(输入退出以结束对话): ") if user_input == "退出": del messages break # 记录新一轮问答 messages.append({ "role": "assistant", "content": answer}) messages.append({ "role": "user", "content": user_input}) # 计算当前总token数 tokens_count += len(encoding.encode((answer + user_input))) # 删除超出token阈值的对话内容 while tokens_count >= tokens_thr: tokens_count -= len(encoding.encode(messages.pop(1)["content"]))chat_with_inter(functions_list=functions_list, prompt="我想根据iquery数据库中数据分析用户流失情况,请问需要用到iquery数据库中的哪几张表呢?", model="gpt-3.5-turbo", system_message=[{ "role": "system", "content": md_content}], auto_run = False)
对话效果
五、结语
在本篇章中,我们进一步强化了Agent智能数据分析平台的功能,通过实现可控的多轮对话交互确认逻辑,极大地提升了用户体验和系统的安全性。这一进步将为未来更加复杂、更加智能化的数据分析平台的构建奠定坚实的基础。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。