热门AI通用大模型对比盘点(附论文)
CSDN 2024-06-28 09:31:01 阅读 85
今天我来和大家聊聊通用大模型,垂直领域大模型等整理完了再和大家分享。大家可以先关注一下我,有更新可以立马看见。
本文文末有整理好的通用大模型论文,都是各个大模型的原始论文,强烈建议大模型方向的同学,或者对大模型研究感兴趣的同学阅读。
另外也分享一下我之前盘点过的GPT4平替模型,大家感兴趣的可以点蓝字 看看。
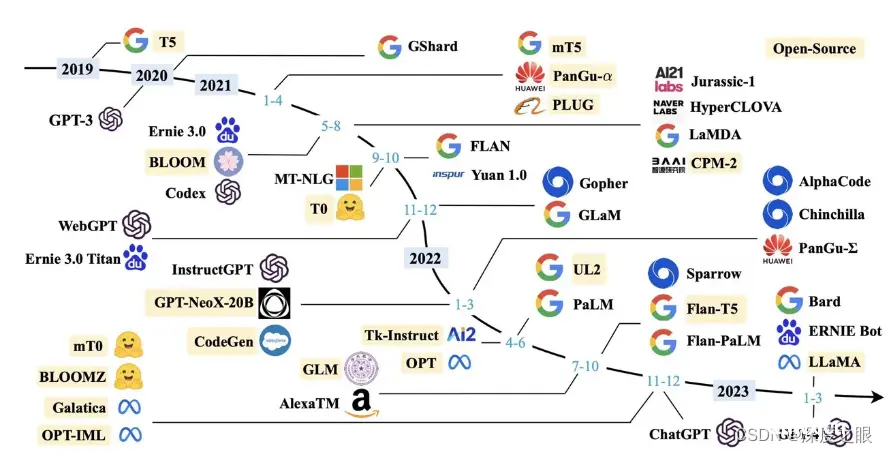
自ChatGPT发布以来,通用大模型就仿佛坐了火箭,短短几个月的时间,各大企业便争相发布自己的大模型,这其实也反应了目前人工智能发展的方向,所以,目前通用大模型的研发已经成为各国新一轮技术竞争的核心领域。
既然都这么火了,那让我们来看看到现在都有哪些通用大模型。
国内:
1.文心一言
网址:文心一言
使用评价:在文学创作上回答的挺全面,数学解答能力有点不太行,代码能力也是一般般。
2.通义千问
网址:通义千问
使用评价:文学创作也很不错,翻译和数学问题回答的也可以,代码能力有待提高。
3.讯飞星火
网址:讯飞星火认知大模型
使用评价:首先它这个审核速度我是满意的,两天就通过可以上手玩耍了,代码解释能力不错,但是写代码还是差点意思。
4.天工
网址:天工官网
使用评价:文学创作能力也在线,数理问题也能做,代码能力整体也是一般。
5.360智脑
网址:360智脑 - 体验平台
使用评价:这个也是申请了好久,刚刚才通过,我都快忘了...简单试用了一下,数理问题复杂点的不太行,代码编程能力还不错。
国外:
1.ChatGPT
网址:https://chat.openai.com/
使用评价:这还需要评价嘛(doge)
2.new bing
网址:必应
使用评价:这么说吧,我现在找论文基本都用它。
3.Claude
网址:Slack is your productivity platform | Slack
使用评价:用Claude需要先注册一个slack号,然后才能使用。流程还是比较简单的,有同学需要注册攻略吗?需要的话在评论区吱一声,我之后整理一下。
偏题了...Claude好处是登录之后就不用再用魔法了,而且用它来辅助阅读论文是真不错~
4.Bard
网址:https://bard.google.com/
使用评价:这个我用的少,用的时候还不支持中文,创造力不如GPT,其他能力还是可以的。
必读论文:
1.word2vec
论文标题:Efficient Estimation of Word Representations in Vector Space
这篇论文在词向量学习和大规模文本表示学习方面做出了以下贡献:
1) 提出两种词向量学习模型架构:word2vec模型
2) 这些模型可以在大规模数据集上快速学习高质量词向量
3) 学习到的词向量在词相似度任务上优于其他方法,达到当时的最先进水平
这篇论文为大规模词向量学习和文本表示学习提供了有价值的参考,为自然语言处理任务奠定了基础。
2.Seq2Seq
论文标题:Sequence to Sequence Learning with Neural Networks
这篇论文提出了一种基于LSTM的端到端序列学习方法:Seq2Seq,首次将编码器-解码器结构应用于自然语言处理任务。
该方法在英法机器翻译任务上取得了当时最先进的结果,可以学习词序敏感的短语和句子表示,并且可以通过引入更多短期依赖关系来提高性能,表现出较强的表达能力和学习能力。
这篇论文为序列学习和神经网络机器翻译研究提供了有价值的参考,为后续研究奠定了基础。
3.Transformer
论文标题:Attention is All You Need
这篇论文的主要贡献为:
1) 提出一种网络架构Transformer,引入了自注意力机制
2) Transformer在机器翻译质量和效率上优于其他序列转换模型
3) Transformer显示出很强的泛化能力,可以应用于其他自然语言处理任务
这篇论文为序列学习和神经网络机器翻译研究提供了新的思路和参考。该网络架构Transformer已成为机器翻译和其他序列学习任务的主流框架之一。
4.BERT
论文标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
这篇论文的主要贡献为:
1) 提出BERT模型,实现实现了多项自然语言处理任务的突破性进展。
2) BERT在11个NLP任务上取得SOTA,展示了其强大的适用性
3) BERT通过简单的微调即可迁移到不同任务,无需重大改变模型架构,这大大减轻了研发模型的工作量。
这篇论文在NLP的预训练模型和深度学习模型的研究与应用方面具有里程碑意义。
BERT模型的提出开启了NLP中大规模语言理解的新篇章。其强大的表征学习能力和任务迁移能力使其迅速应用于NLP的各个子领域,产生广泛影响,极大地推动了NLP技术的进步。
5.GPT
论文标题:Improving Language Understanding by Generative Pre-Training
这篇论文的主要贡献为:
1) 提出一种基于生成式预训练和歧视性微调的方法,实现NLP任务的迁移学习
2) 使用面向任务的输入变换实现迁移,仅需要少量改变模型架构
3) 实证该方法在12个任务上的有效性,实现SOTA
4) 提供一种通用的框架,解决NLP任务学习中的数据匮乏问题。
这篇论文在NLP中迁移学习和端到端学习的研究方面具有重要意义。作者提出的方法为解决不同任务的数据匮乏问题提供了一种有效和实用的框架。
6.GPT2
论文标题:Language Models are Unsupervised Multitask Learners
这篇论文的主要贡献为:
1) 提出了一个从大规模文本数据中自动发现任务的方法
2) 利用大规模网页数据集WebText预训练语言模型,使其可以零样本学习执行NLP任务
3) 证明语言模型的容量对迁移学习至关重要,更大的模型可以实现更好的性能
4) 模型GPT-2在7个语言建模数据集上达到SOTA,但仍然不足以拟合全部WebText
这篇论文在NLP中的迁移学习和无监督学习方面具有重要意义。作者证明了大规模语义模型在合适的数据集上的预训练可以实现对NLP任务的零样本学习和适配。这为解决数据匮乏问题,构建可以像人类一样从示例中学习任务的语言模型提供了参考。
7.T5
论文标题:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
这篇论文的主要贡献为:
1) 提出一个统一的框架T5,推动迁移学习的发展
2) 系统研究不同迁移学习方法,并在多个NLP下游任务上进行比较
3) 基于Colossal Clean crawled语料库和模型规模,在许多基准测试上达到SOTA
这篇论文在NLP中迁移学习的研究和应用方面具有重要意义。作者提出的框架和比较研究可以指导未来在不同任务和方法上的工作。
8.GPT3
论文标题:Language Models are Few-Shot Learners
这篇论文的主要贡献为:
1) 提出大规模语言模型GPT-3
2) 在少样本设置下,GPT-3在许多NLP任务上达到或超过先前SOTA,展示了规模化带来的性能提高
3) GPT-3在某些任务上表现人类水平,但也面临方法论方面的挑战
4) 讨论大规模语言模型可能带来的广泛社会影响。
GPT-3的强大能力预示着深度学习在NLP领域可能取得的显著进步,但也提示研究社区需要正视并处理人工智能带来的广泛影响。
9.LLaMA
论文标题:Open and Efficient Foundation Language Models
这篇论文的主要贡献为:
1) 开发并开源一组不同规模的语言模型LLaMA
2) 证明可以仅使用公开数据集训练最先进的语言模型
3) 这些模型在性能上匹配或超过专有模型,为语言模型的研究和应用带来更大选择
这篇论文在大规模语言模型和神经网络模型的研发和应用方面具有重要意义,减少了语言模型研究的门槛,使更多研究者可以接触并开发大规模神经网络模型,有助于推动该领域技术的发展。
10.GPT4
论文标题:GPT-4 Technical Report
这篇论文的主要贡献为:
1) 开发了大规模多模态语言模型GPT-4
2) GPT-4在人工智能基准测试中达到或超过人类水平
3) 模型研发采用可扩展的框架,可以在不同规模下保证性能,为后续更大规模模型提供经验
4) 该模型为多模态智能体研究和人工通用智能发展提供了有价值的参考
GPT-4的强大能力表明在人工智能的发展已进入新的阶段,为人工智能的未来发展指明了方向。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“通用”获取全部论文PDF
码字不易,欢迎大家点赞评论收藏!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。