电子科技大学人工智能期末复习笔记(二):MDP与强化学习
Vec_Kun 2024-07-10 14:31:09 阅读 85
目录
前言
期望最大搜索(Expectimax Search)
⭐马尔科夫决策(MDP)——offline(超重点)
先来看一个例子
基本概念
政策(Policy)
折扣(Discounting)
如何停止循环?
价值迭代(Value Iteration)
例题
固定策略(Fixed Policies)
策略提取(Policy Extraction)
策略迭代(Policy Iteration)
策略迭代和价值迭代的比较
强化学习(Reinforcement Learning, RL)——online
简介
基于模型的强化学习(Model-Based RL,MBRL)
无模型强化学习(Model-Free RL,MFRL)
直接评估(Direct Evaluation)
时间差分学习(Temporal Difference Learning)
主动强化学习(Active Reinforcement Learning)
Q-Learning
探索与利用
前言
本复习笔记基于李晶晶老师的课堂PPT与复习大纲,供自己期末复习与学弟学妹参考用。
在上一节中,我们提到了Minimax是一种悲观算法,即考虑最坏的情况(Worst Case)从而使损失最小化。然而在实际操作过程中,对手并不是始终能做到最优决策,会有一定概率的失误,因此我们应当计算平均能得到的分数。
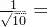
当不确定的结果会偶然出现时,也就是在不确定性搜索(Non-Deterministic Search)下,我们的算法就需要做出调整。
期望最大搜索(Expectimax Search)
在前言的条件下,对手不一定足够smart去得到最优解,因此,我们将对手节点视作chance nodes,它具有一定的概率去实行一定的策略,此时的策略是使得expected utility最大。值现在应该反映平均情况(预期)结果,而不是最坏情况(最小)结果。上一节提到的minimax实际上是expected max的一种概率为1或0的特例。
▪期望搜索:计算平均分数下最优玩法
▪最大节点和Minimax一致
▪机会节点类似Minimax的最小节点但结果不确定
▪计算他们的预期效用
▪即加权平均(期望)子节点
注意:在expectimax中最好不要进行剪枝操作,因为min层的计算需要依据下一层的每一个值(如果概率不是非0即1那种)
选择minimax策略的agent总是过于悲观,因此分数不会太高,但胜率会很高;而选择expectimax策略的agent过于乐观(比如万一有一种情况分数很高但概率相对不高,在计算的结果中,导致此算出来的期望值很高,agent会选择这种策略,但事实上,opponent很有可能选择其他路并且令agent分数减少)
⭐马尔科夫决策(MDP)——offline(超重点)
MDP是一个五元组<S,A,T,R,γ>——状态空间、行为、状态转移概率、奖励、折扣因子
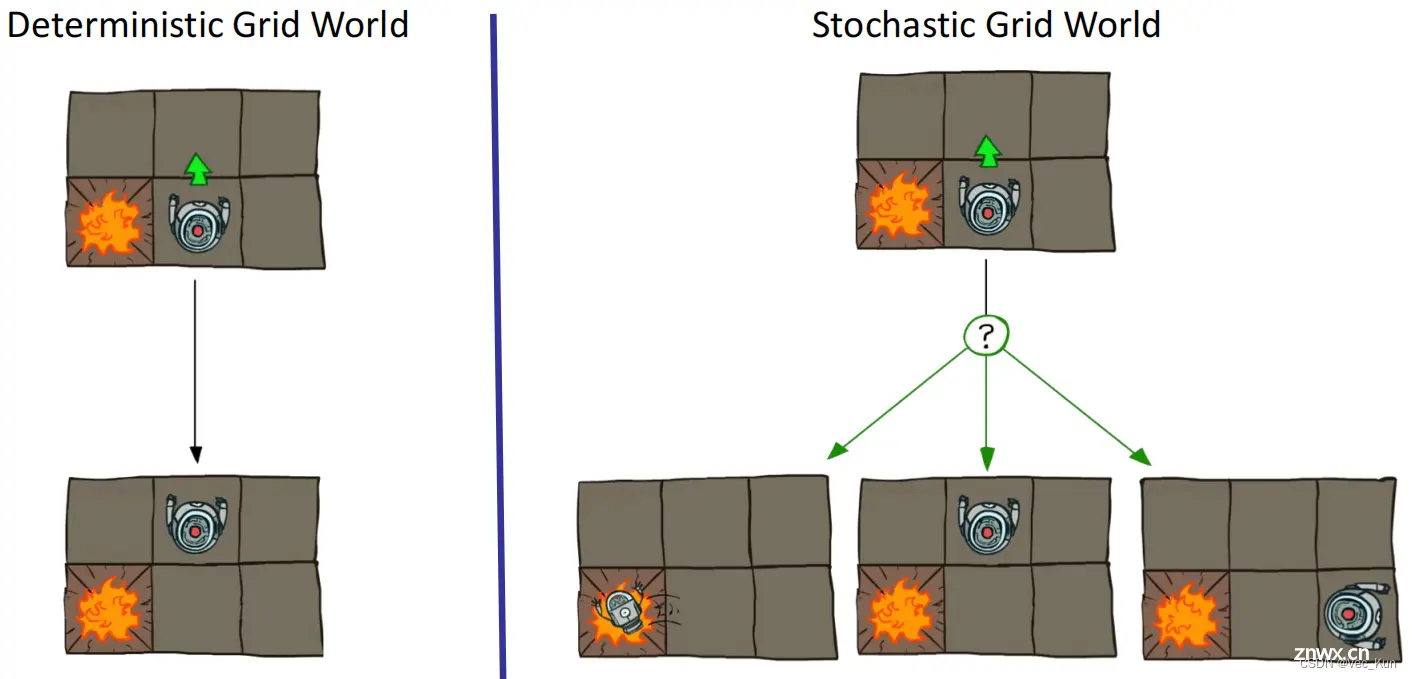
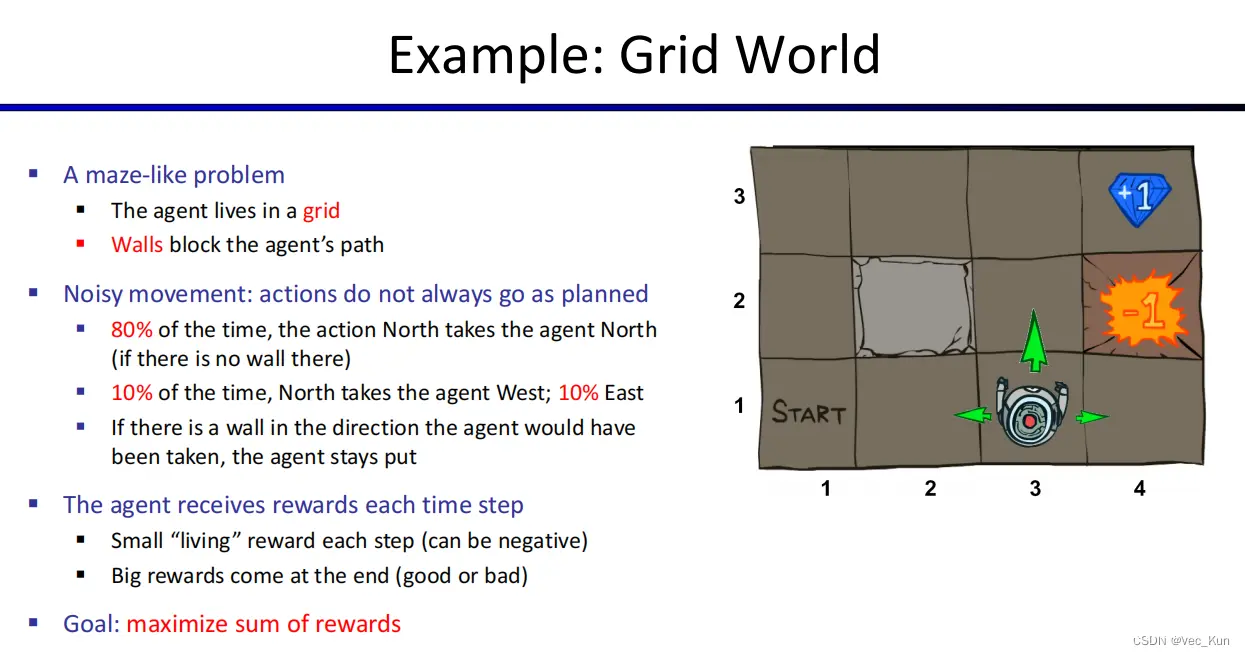
先来看一个例子
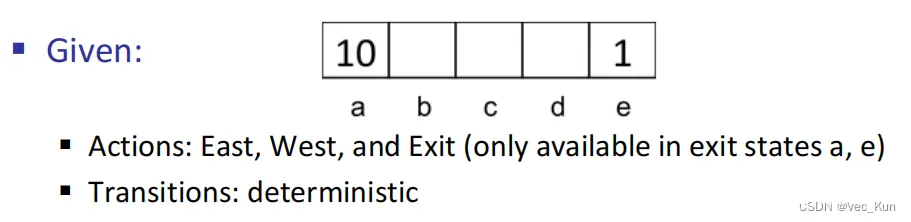
只有一个主体,存在障碍,惩罚出口和奖励出口,主体可以任意移动但是有概率出现偏差移动,如果移动碰到墙体则呆在原地,每行动一步会有小的存活奖励(正/负/0都可).。
我们的目标是使主体得到的分数最大化。
如下图,以前的决策是左边的情况,而现在要解决的是随机问题

基本概念
这就要用到马尔科夫决策过程(MDP):
▪MDP定义为:
▪一组状态集S
▪一组动作集A
▪一个过渡函数T(s,a,s')
▪从状态s到状态s'的概率,例如,P(s'|s, a)
▪也称为模型或动态
▪奖励函数R(s,a,s')
▪有时只是R (s)或R (s')
▪一个起始状态
▪也许存在结束状态
▪马尔科夫决策过程,“马尔科夫”意味着行动结果只取决于当前状态
▪这就类似搜索,后继函数只能取决于当前状态(而非历史状态)
▪MDPs是非确定性搜索问题
▪解决它们的一种方法是期望最大搜索
政策(Policy)
在确定性单代理搜索问题,我们想要一个从起始节点到目标节点的最优计划,或序列的行动。
在MDP中,我们需要一个最优政策
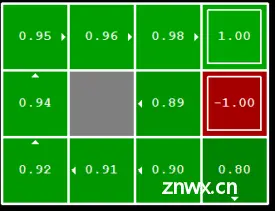
,它在每一个状态下都给出一个动作,并且尝试在最后得到最大的效益,显式的策略定义了主体的反应倾向,如下图:
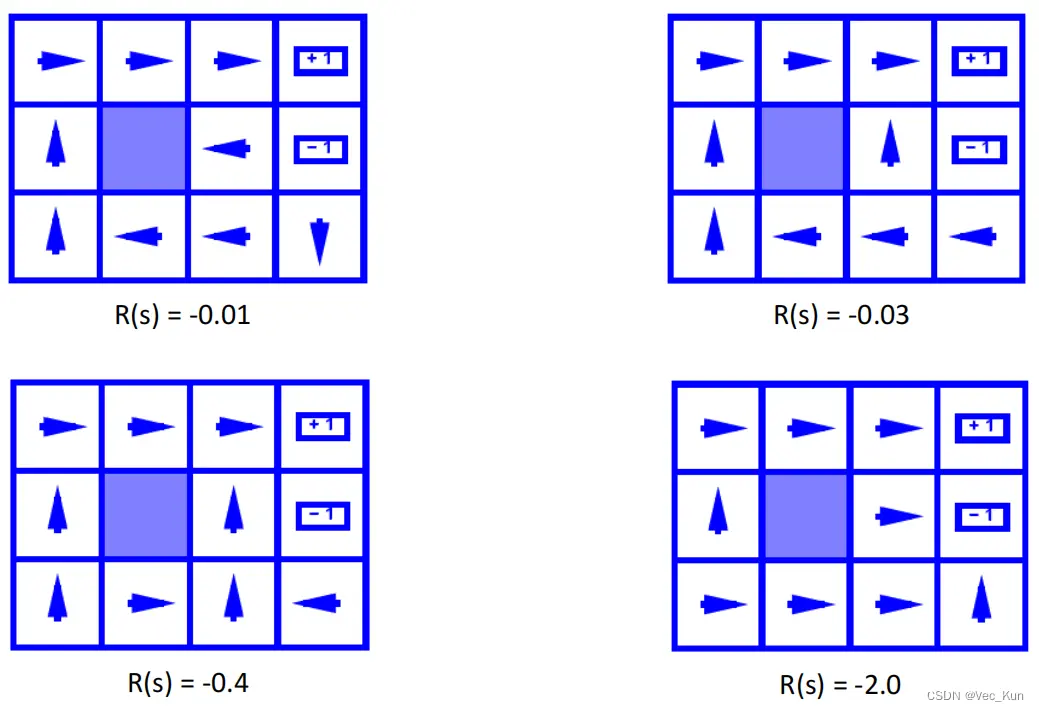
能观察到,在不同的生存奖励下,主体的行动倾向都有所不同。
折扣(Discounting)
如上图,当生存奖励的负分偏小时,在更为危险的地块中agent会宁愿选择一直对墙试错从而让自己滑行到两侧而非冒险按正确的朝向走,这可能会与我们的实际预期不符,因为它走做了太多无用的动作。这时我们就要给奖励添加折扣,让agent尽可能快的拿到最大的奖励:
▪最大化奖励的总和是合理的
▪更喜欢马上获得的奖励而非以后的奖励也是合理的
▪一个解决方案:奖励的值呈指数衰减
例如,折扣为0.5时,U([1,2,3]) < U([3,2,1])。
U([1,2,3]) = 1*1 + 0.5*2 + 0.25*3 ;U([3,2,1]) = 1*3 + 0.5*2 + 0.25*1
例如:
在状态d时,γ为多少时往左或右的收益一致?
解:
,解得γ=
。


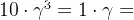
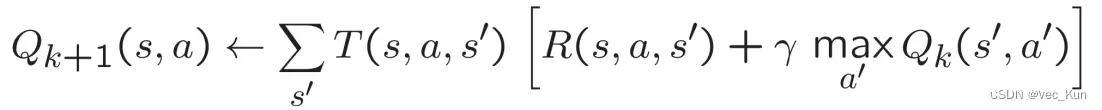
如何停止循环?
如果一个游戏可以一直进行,怎么让它停下来并呈现出我们的分数?
1. 可以设置在进行n步之后必须结束游戏(life/生命周期)
2. 可以设置动态变化的政策,例如随着可用步数的减少,政策随之变化
3. 可以设置折扣,到最后奖励值会趋于收敛,当分数变化小于某个临界时可以结束游戏
4. 可以设置一个“吸收节点”,当进入这个节点时必须退出游戏,这个节点在前面的阶段不会进入,但到后面终将有可能进入这个状态。
价值迭代(Value Iteration)
起始价值和为0,因为还没有开始迭代给定某一向量的价值,开始向后迭代
重复迭代直至收敛
值迭代缺点:
速度慢——每次迭代时间复杂度 O(S²A)每个状态的“最大值”很少改变policy通常早在values之前收敛
举例:汽车运行问题
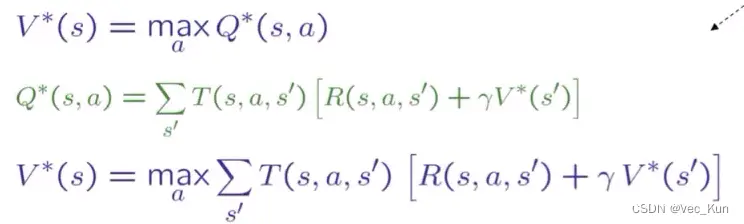

例题
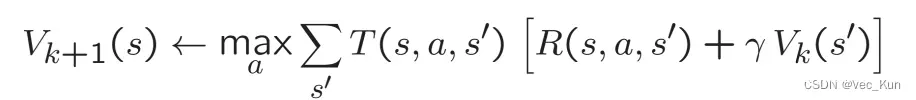
固定策略(Fixed Policies)
固定每一步的action由函数π(s)得到,那么V值计算如下,其实和价值迭代没太大区别
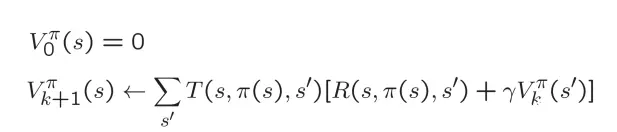
策略提取(Policy Extraction)
在知道每一步的最优价值V*(s)时,还需要进行一个arg max()操作来求得执行哪个action会得到此最优价值
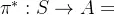
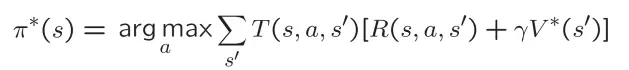
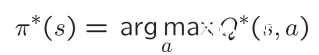
策略迭代(Policy Iteration)
包括两部分:
策略评估:对于固定策略π ,通过策略评估得到V值,迭代直至v值收敛
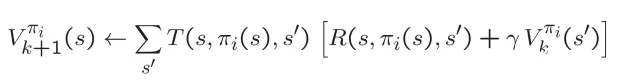
策略提升:对于固定策略的V值,使用策略提取获得更好的策略:
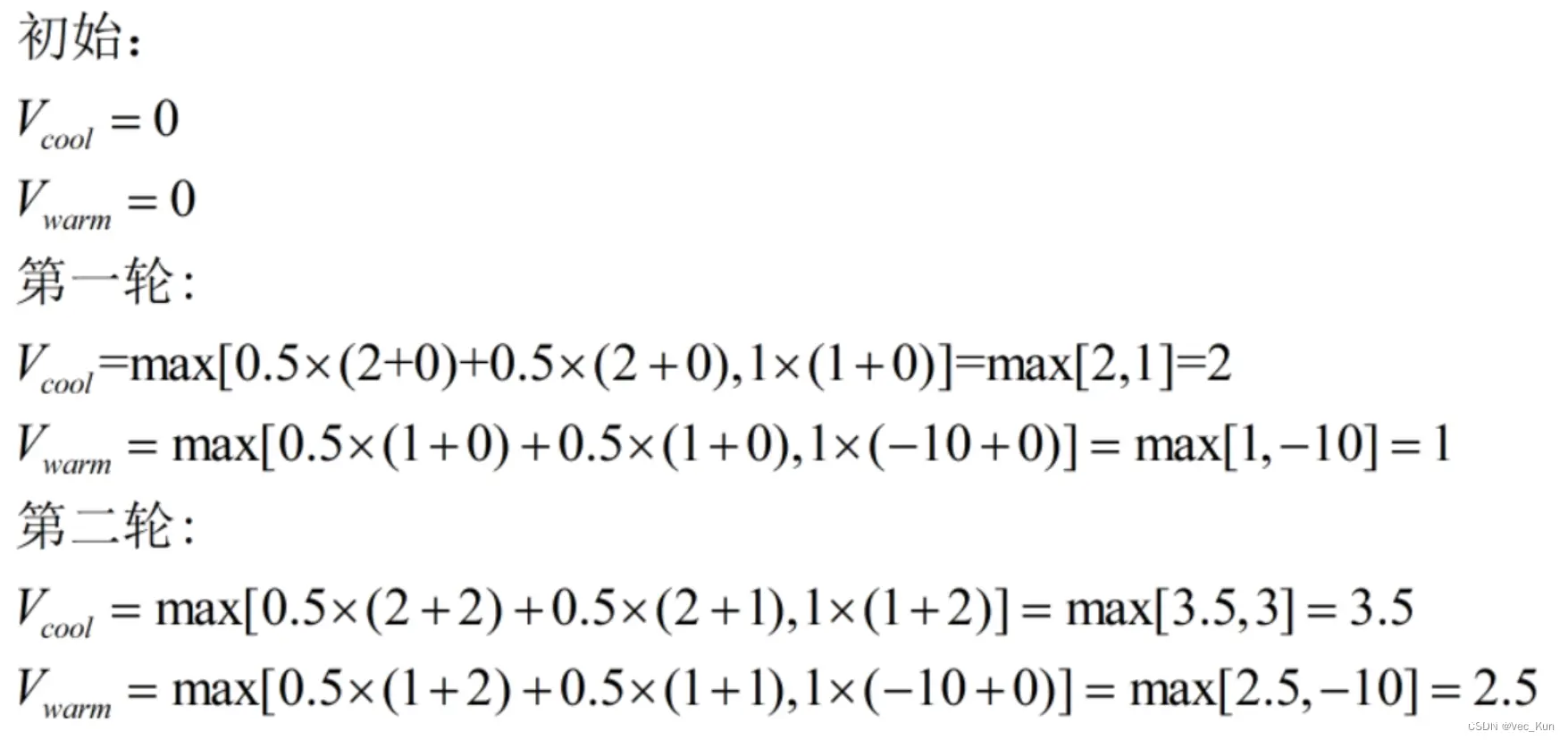
局限:在不知道T和R时无法更新V
idea:对结果 s'(通过做动作!)和平均值进行采样
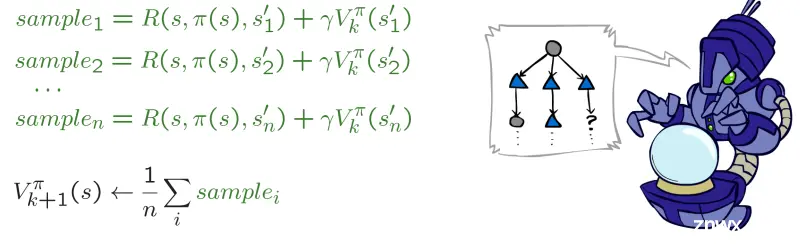
策略迭代和价值迭代的比较
两者本质上都是计算最优value,都是用于解决MDP的动态程序
价值迭代:
每次迭代都更新value和policy不跟踪policy,但在选择最大Q值时会隐式的重新计算他
策略迭代:
使用固定策略进行了几次更新实用程序的传递(每次传递都很快,因为我们只考虑一个动作,而不是所有动作)After the policy is evaluated, a new policy is chosen(慢如值迭代传递)新policy会更优
强化学习(Reinforcement Learning, RL)——online
简介
强化学习与MDP的区别就在于:我们不明确转化函数和奖励函数的具体内容,必须切实地去尝试以后才能得出结论!
所以说,强化学习是一种在线学习方式,只能靠自己试错来得出正确的决策。
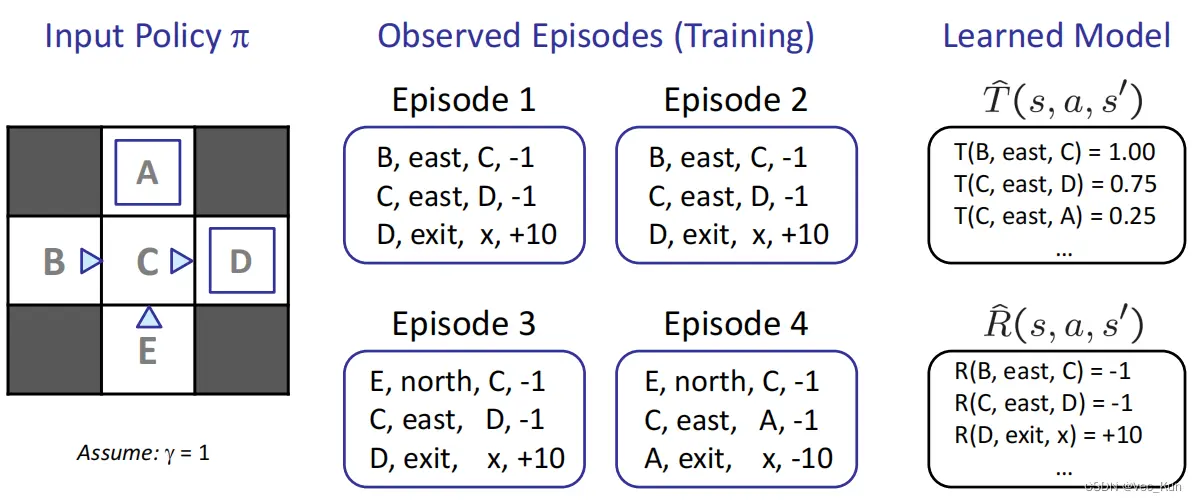
基于模型的强化学习(Model-Based RL,MBRL)
step1.通过training过程,计算状态转移矩阵T()和动作reward R(),通过学习得到经验MDP模型
step2. 使用价值迭代或策略迭代求解最优values
过程:
1. 选出所有状态
2. 用模型模拟转移函数
3. 模拟奖励函数并且得出价值
4. 用MDP完成剩余的价值迭代等工作
例题:
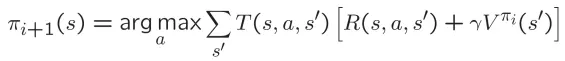
无模型强化学习(Model-Free RL,MFRL)
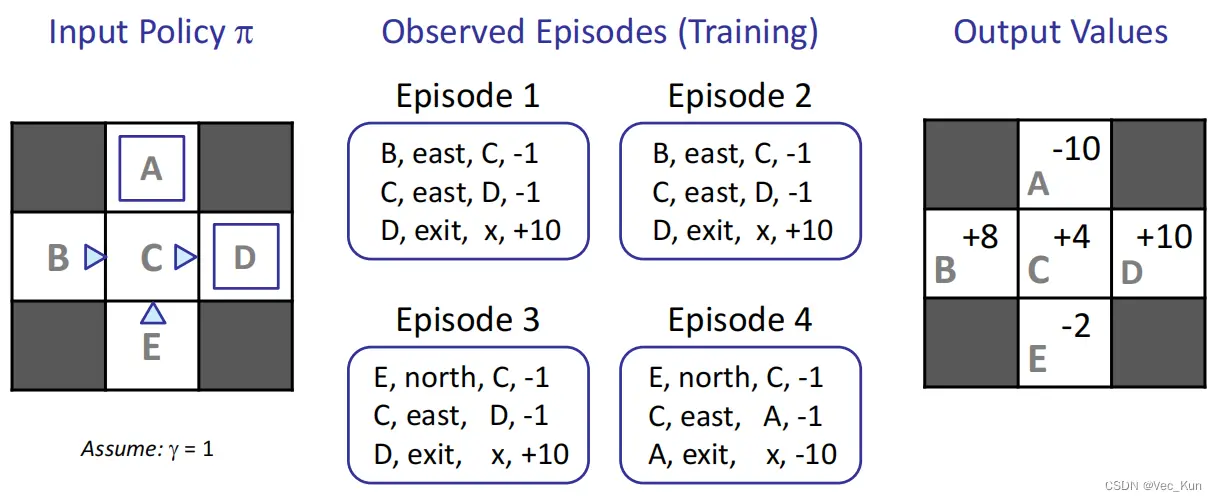
直接评估(Direct Evaluation)
计算当前政策下所有动作的价值, 将观察到的样本值作平均
根据政策做出动作每次遇到一种情形, 都把(折扣)奖励加起来平均这些样本, 得到直接评估结果
例题:
计算过程:
A = [-10] / 1 =10
B = [(-1-1+10)+(-1-1+10)]/2 = +8
C = [(-1+10)+(-1+10)+(-1+10)+(-1-10)]/4 = +4
D = [10+10+10]/3 = +10
E = [(-1-1+10)+(-1-1-10)]/2 = -2
优点:简单易理解;不需要计算T、R;最终你那个计算出正确的平均value
缺点:浪费了状态连接的信息,每个状态必须单独学习,会花费较长时间学习
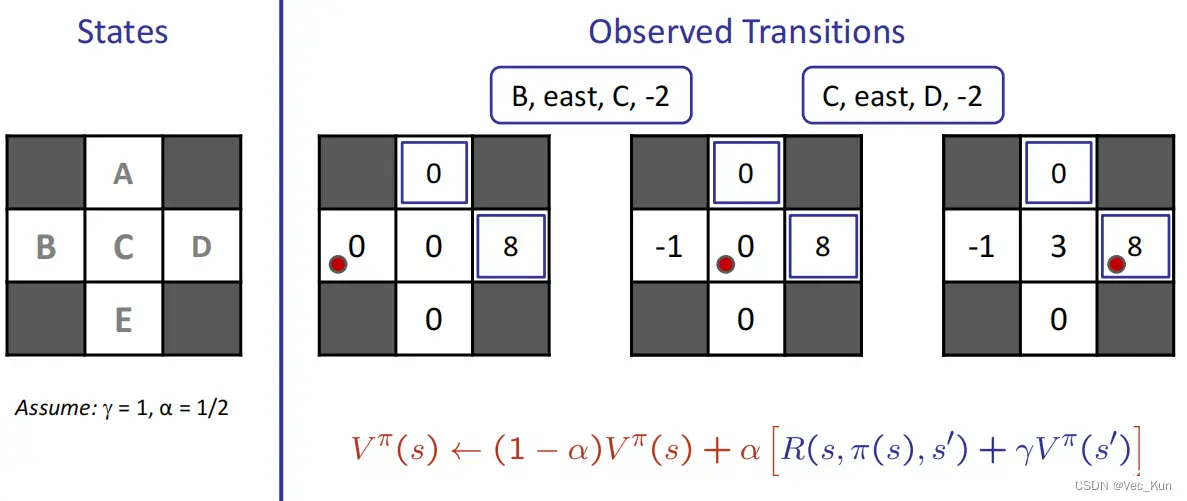
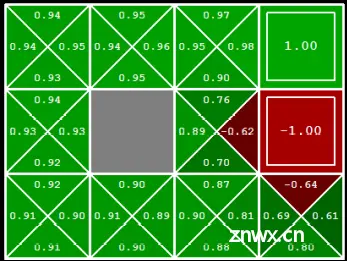
时间差分学习(Temporal Difference Learning)
从每段经验中学习
每次经过一个转移函数(动作)就更新V(s)以至于新的状态将会为更新策略作出更多贡献政策固定, 始终作评估将当前值提供给任何一个后继者并作平均
例题:
计算过程:

主动强化学习(Active Reinforcement Learning)
Q-Learning
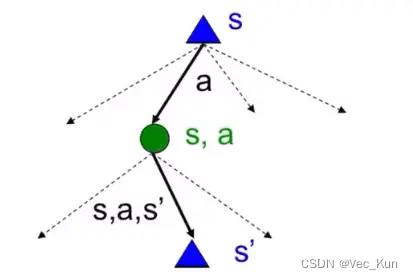
我们可以计算出下一个状态的价值并取最大值,但我们也可以计算Q-state(Q状态)的值, 在我理解, 它属于一个未决策的中间态(更关注当前状态和动作), 计算出它的值可以帮助我们决策, 并且更加有用。
如果知道转化函数和奖励函数:
如果不知道:
取一个实例,作为转化函数与奖励函数的值来迭代。


Q-Learning的属性
即使没有按最优方式迭代,Q-Learning也始终能够最终迭代为最优结果(非政策学习)
前提条件:
你必须探索足够的次数你必须最终使学习率足够小但不要太快减少它不管你如何选择行动,要求基本上在限制下内
探索与利用
我们通常利用各种函数来帮助我们得出价值等数值帮助决策行为,但这样也不一定是最优解,需要偶尔去进行探索,但在什么条件下进行探索呢?
有几种方案可以强迫探索最简单:随机行动(ε-贪婪)
每次行动,随机一次(使ε为0到1之间的任意数,每次随机出一个0到1的数与它比较)比ε小,行动随机比ε大,行动按当前策略随机行动的问题?
我们最终会探索其他可能性,但必须在学习完成后继续研究解决方案:随着时间的推移降低ε
总结
我们已经看到了人工智能方法如何解决以下问题:
▪搜索
▪约束满足问题
▪博弈
▪马尔可夫决策问题
▪强化学习
下一节:一阶逻辑
上一篇: raw数据噪声标定(AISP_NR: 2D AI-Noise Reduction for RAW Images)
下一篇: 【粉丝福利社】AI商业广告设计实战108招:ChatGPT+Photoshop+Firefly+Midjourney(文末送书-进行中)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。