通用图形处理器设计GPGPU基础与架构(一)
CSDN 2024-08-22 12:31:01 阅读 62
GPGPU背景
GPGPU(General Purpose Graphics Processing Unit,通用图形处理器)脱胎于GPU (Graphics Processing Unit,图形处理器)。GPGPU由于其强大的运算能力和高度灵活的可编程性,已经成为深度学习训练和推理任务最重要的计算平台。这主要得益于GPGPU的体系结构很好地适应了当今并行计算的需求。
传统的GPU处理图像的步骤如下图所示。
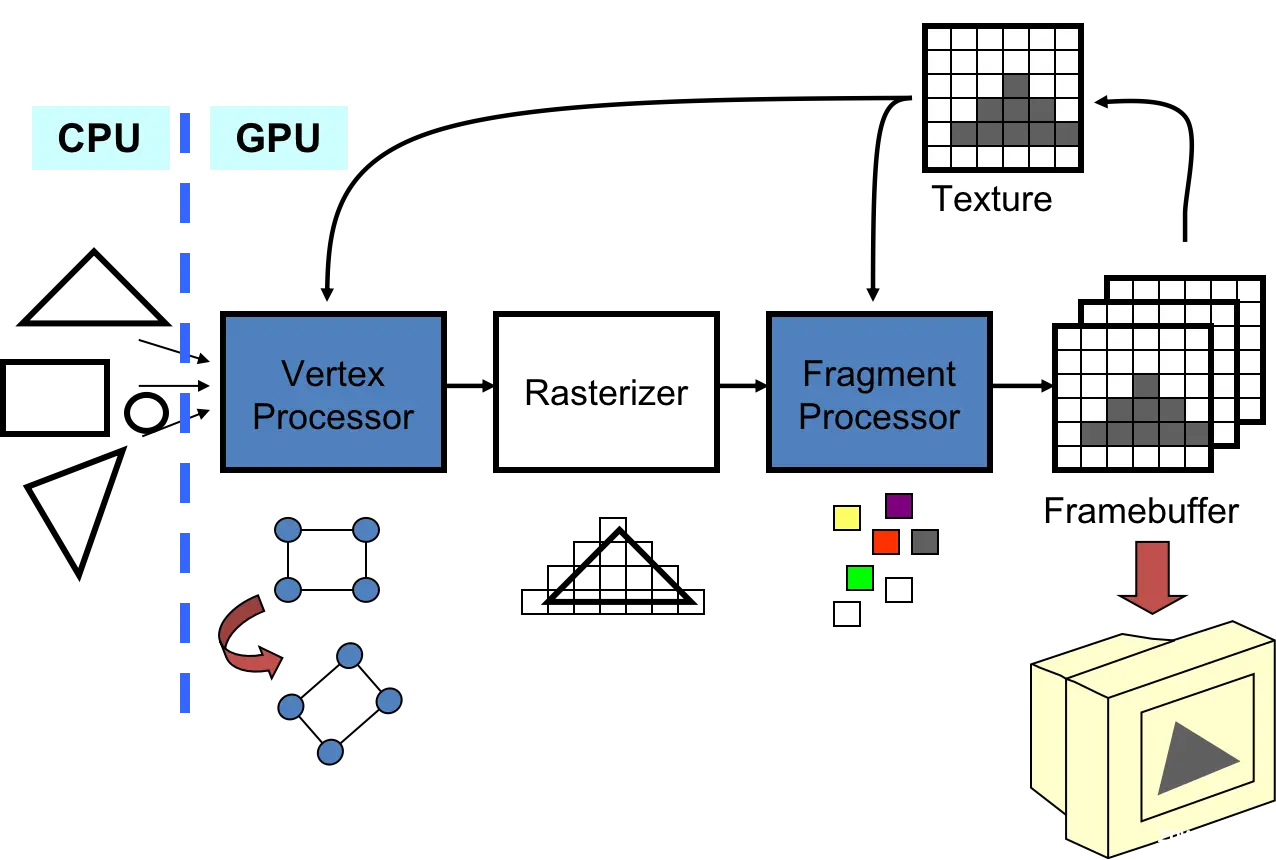
(1)顶点处理(Vertex Processor),图像是由很多几何图元组成的,例如众多顶点、线、三角形、四边形等,这些几何图元归根结底也是由若干顶点组成的。GPU拿到顶点信息后,顶点着色器(Vertex Shader)对每个顶点数据进行一系列的变换,包括几何变换、视图变换、投影变换等,实现顶点的三维坐标向屏幕二维坐标的转化。
(2)几何处理(Geometry Processor),几何着色器(Geometry Shader)对由多个顶点组成的几何图元进行操作,实现逐图元着色或产生额外的图元。各个图元的处理也是相互独立的。
(3)光栅化阶段(Rasterizer)。光栅化(rasterization)的过程,实际上就是通过采样和插值确定帧缓存上的像素该取什么样的值,最终建立由几何图元覆盖的片段。转换后所得到的模型投影平面是一个帧缓存,它是一个由像素定义的光栅化平面。
(4)像素处理。这些像素或由像素连成的片段还要通过像素着色器(pixel shader)或片段着色器添加纹理、颜色和参数等信息。
(5)输出合并。最后阶段执行 Z-buffer 深度测试和模板测试,丢弃隐藏片段或用段深度取代像素深度,并将段颜色和像素颜色进行合成,将合成后的颜色写入像素点。
可以发现处理图像的过程中有些步骤内的计算与处理是相互独立的,可以通过并行操作来实现加速,这也是为什么用GPU来处理图像的原因。
可明明这篇博客是介绍GPGPU(通用图形处理器)的,为什么突然扯到GPU处理图像的过程呢?是这样的,通用场景中会存在很多大量的简单计算(如矩阵乘加),每个矩阵元素之间的乘加是相互独立的,而CPU适用于处理少量计算复杂的运算不适用于处理大量的简单运算。
因此有人提出:用图形语言描述通用计算问题或把数据映射到vertex或者fragment处理器就可以将通用计算问题转换为图形问题用GPU进行处理。 根据这一思想,就逐渐演变出了面向通用计算的图形处理器,也即GPGPU这一全新形态。
并行计算机是一些处理单元的集合,它们通过通信和协作快速解决一个大的问题。
一个处理单元可以是一个算术逻辑功能单元,也可以是一个处理器核心或整个计算节点。“通信”是指处理单元彼此之间的数据交互。通信的机制则明确了两类重要的并行体系结构,即共享存储结构和消息传递结构。“协作”是指并行任务在执行过程中相对于其他任务的同步关系,约束了并行计算机进行多任务处理的顺序,保障其正确性。
指令流是由单个程序计数器产生的指令序列;数据流是指令所需数据及其访问地址的序列。根据指令流和数据流可以将并行计算机定义为以下四类:
(1)单指令流单数据流(Single Instruction Stream &.Single Data Stream,SISD)。SISD并不是并行体系结构。传统的单核CPU就是SISD的代表,它在程序计数器的控制下完成指令的顺序执行,处理一个数据。
(2)单指令流多数据流(Single Instruction Stream &.Multiple Data Stream,SIMD)。SIMD 是一种典型的并行体系结构,采用一条指令对多个数据进行操作,向量处理器就是SIMD的典型代表。
(3)多指令流单数据流(Multiple Instruction Stream &.Single Data Stream,MISD)。MISD是指采用多条指令(处理单元)来处理单条数据流,数据可以从一个处理单元传递到其他处理单元实现并行处理。通常认为脉动阵列(Systolic Array)结构是MISD的一种实例。
(4)多指令流多数据流(Multiple Instruction Stream &.Multiple Data Stream,MIMD)。MIMD是最为通用的并行体系结构模型。它对指令流和数据流之间的关系没有限制,通常包含多个控制单元和多个处理单元。各个处理单元既可以执行同一程序,也可以执行不同的程序。目前大多数多核处理器就属于MIMD的范畴。
指令级并行和数据级并行更适合在核内实现,因为它所需要的寄存器传输级(Register Transfer Level,RTL)通信和协作可以在核内以极低的延迟完成。因此,现代微处理器中每个核心都会综合运用流水化、超标量、超长指令字、分支预测、乱序执行等技术来充分挖掘指令级并行。相对来讲,MIMD的并行层次更高,会更多地利用多个处理单元、多个处理核心和多个处理器或更多的节点来实现。
和4核、8核CPU相比,GPU则由数以千计的更小、更高效的核心组成。这些核心专为同时处理多任务而设计,因此GPU也属于通常所说的众核处理器。
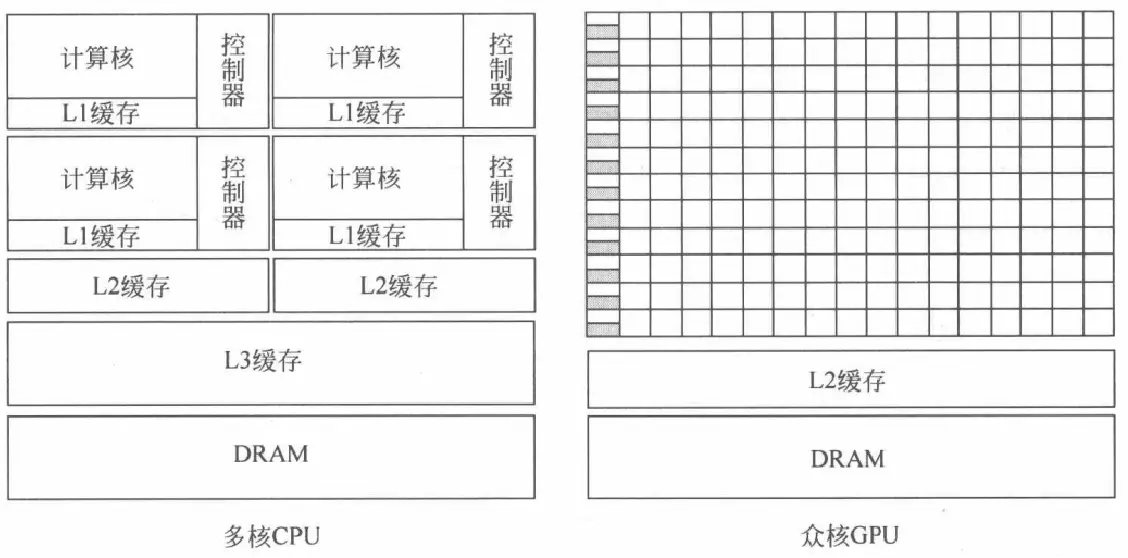
如图所示,CPU中大部分晶体管用于构建控制电路和存储单元,只有少部分的晶体管用来完成实际的运算工作,这使得CPU在大规模并行计算能力上极受限制,但更擅长逻辑控制,能够适应复杂的运算环境。GPU的控制则相对简单,对高速缓存的需求相对较小,所以大部分晶体管可以组成各类专用电路、多条流水线,提升了GPU的计算能力。同时,图形渲染的高度并行性也使得GPU可以通过简单增加并行处理单元和存储器控制单元的方式来提高处理能力和存储器带宽。
总结来说就是:
CPU:强控制弱计算,更多资源用于缓存;
GPU:强计算弱控制,更多资源用于计算。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。