AI生成漫画或者小说推文——自动根据角色画绘本如何保持角色生成一致性的问题
CSDN 2024-07-10 12:01:03 阅读 64
前言
生成与文本描述相匹配的一系列图像是一个复杂的任务,要求生成的图像在质量上要高,与文本描述保持对齐,并且保持角色身份的一致性。例如在使用Stable Diffusion生成人物中要实现不同的动作图像,但要求衣服、发型和相貌保持不变。或者,可以根据一个已有的角色生成各种不同风格的海报图,而无需对模型进行额外的训练。目前的方法通常通过限制考虑特定的少数角色和情境,或者要求用户提供每个图像的详细控制条件(如草图)来大大简化问题。然而,这些简化使得这些方法无法胜任实际应用的需求。
近期由浙大发表的论文AutoStory和谷歌论文The chosen one提到了一些可能的解决方案。
AutoStory
一、简介
本文提出了一种名为AutoStory的全自动、多样化、高质量的故事可视化方法。用户只需输入简单的故事描述,即可生成高质量的故事图像。与此同时,该方法还提供了灵活的用户界面,允许用户通过简单的交互来微调故事可视化的结果。这种方法具有广泛的应用前景,可以为艺术创作、儿童教育和文化传承等领域提供丰富的视觉表达。

本文提出了一种全自动的故事可视化流程,能够在最小的用户输入要求下生成多样化、高质量和一致的故事图像。为了处理故事可视化中的复杂情境,我们采用了稀疏控制信号进行布局生成,并利用密集控制信号进行高质量图像生成。同时,我们引入了一种简单而有效的密集条件生成模块,可以将稀疏控制信号自动转换为草图或关键点控制条件。为了保持身份一致性并消除用户为角色绘制或收集图像数据的需求,我们提出了一种简单的方法,从文本中生成多视角一致的图像。此外,我们利用3D先验来提高生成的角色图像的多样性,同时保持身份一致性。这是第一个能够在多样化的角色、场景和风格中生成高质量故事图像的方法,即使用户只输入文本,也能灵活适应各种用户输入。
二、故事可视化
故事可视化是一项任务,旨在从文本描述中生成一系列视觉一致的图像。现有方法主要基于GAN,但由于模型生成能力的限制,很多方法在特定数据集上简化任务,难以泛化到不同的角色和场景。一些新方法采用了VQ-VAE和基于transformer的语言模型,或者借助预训练的DALL-E进行改进。其中一些方法还提出了新的任务,如故事延续和自回归方法。
大规模预训练的文本到图像生成模型的发展为可推广的故事可视化开辟了新的机会。尽管已有多种尝试生成具有多样化角色的故事图像的方法,但存在一些限制。TaleCraft提出了一种系统化的故事可视化流程,但需要用户提供每个角色的草图。相比之下,我们的方法只需文本描述作为输入即可生成多样化且连贯的故事可视化结果。
三、可控图像生成
大规模预训练的文本到图像模型可以通过交叉注意力层将文本信息传递到图像的潜在表示中,从而生成图像。稳定扩散是一种大规模预训练的文本到图像模型,可以通过文本提示生成图像。
T2I模型在生成多个角色和复杂场景方面表现不佳,因为受到文本编码器语言理解能力的限制和文本到图像内容关联性差的影响。为了解决这个问题,一些方法引入了显式的空间引导,例如ControlNet、T2I-Adapter和GLIGEN。这些方法通过引入可靠的控制和注入指导特征,使得模型能够更好地利用输入信息。
最近的研究使用大型语言模型(LLMs)进行布局生成,其中LayoutGPT和LLM-grounded Diffusion都取得了不错的效果。然而,LLM-grounded Diffusion需要仔细的超参数调整,而且难以控制生成对象的详细结构。相比之下,本文使用直观的草图或关键点来指导最终图像生成,可以实现高质量的故事图像生成,并允许通过调整生成的草图或关键点条件来进行交互式故事可视化。
四、自定义图像生成
现有方法在一次性定制化方面表现不佳,需要多个用户提供的图像。为了解决这个问题,提出了一种无需训练的一致性建模方法,并利用3D感知生成模型中的3D先验知识,获得多视角一致的角色图像,从而消除了依赖人工收集或绘制角色图像的需求。同时介绍了多种不同的定制化方法,包括单个对象的定制化、多个对象的定制化、多个定制化权重的融合等。
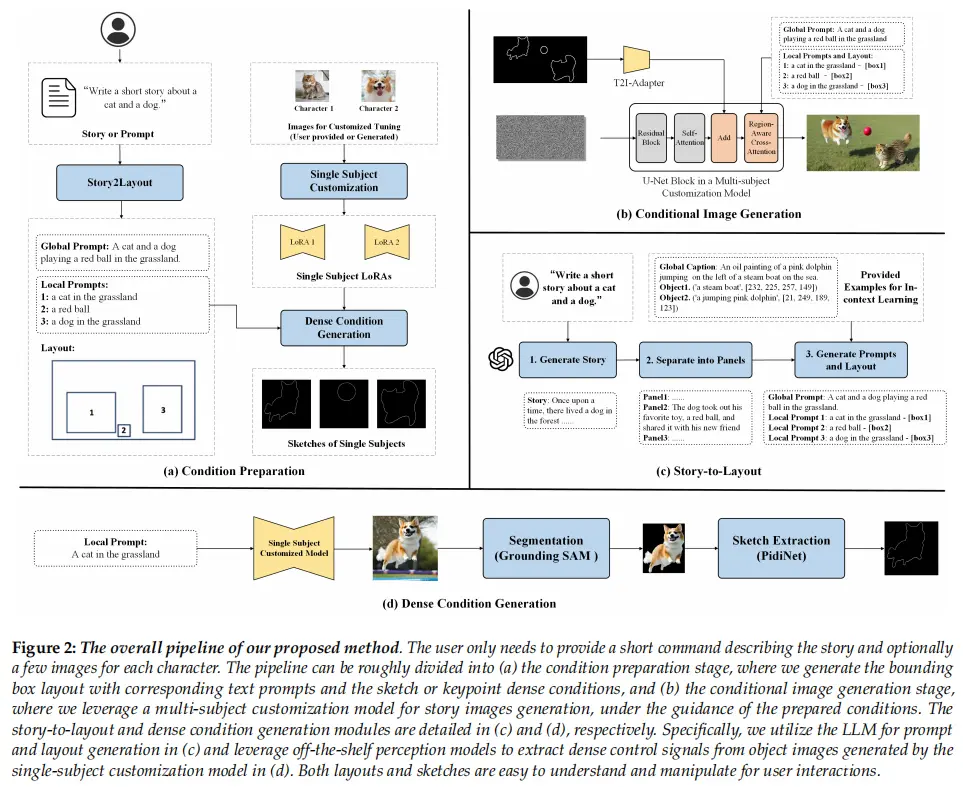
本文介绍了一种生成多样化故事图像的方法,结合了LLMs和大规模文本到图像模型的能力。该方法包括条件准备阶段和条件图像生成阶段,通过LLMs将文本描述转换为故事图像的布局,使用简单而有效的方法将稀疏边界框转换为密集控制信号,生成具有合理场景布局的故事图像,并提出一种方法,使用户无需收集每个角色的训练数据即可生成一致的故事图像。该方法只需要在少量图像上微调预训练的文本到图像扩散模型,可以轻松地在任意角色、场景甚至风格上利用现有模型进行故事叙述。
五、 从故事到布局的生成
1. 故事预处理
用户输入的文本可以是一个书面的故事𝑆或故事的简单描述𝐷。当只提供一个简单的描述𝐷作为输入时,我们利用LLM来生成特定的故事线,即𝑆= LLM(𝐹𝐷2𝑆,𝐷),如图2 ©所示。在这里,𝐹𝐷2𝑆是帮助语言模型生成故事的指令。在获得故事𝑆后,我们要求LLM将故事分割为𝐾面板,每个面板对应于一个讲故事的图像,如下所示:
[
P
1
,
P
2
,
⋅
⋅
⋅
,
P
K
]
=
L
L
M
(
F
S
2
P
,
S
,
K
)
,
(
2
)
[P_{1},P_{2},\cdot\cdot\cdot,P_{K}]=\mathrm{LLM}\left(F_{S2P},S,K\right),\qquad\qquad\qquad(2)
[P1,P2,⋅⋅⋅,PK]=LLM(FS2P,S,K),(2)
其中𝐹𝑆2𝑃是指导模型从故事生成面板的指令,𝑃𝑖是𝑖- th面板的文本描述。至此,我们已经完成了故事的预处理。
2. 布局生成
在将故事划分为面板描述之后,我们利用LLMs从每个面板描述中提取场景布局,如下面的等式所示:
其中𝐹𝑃2𝐿是指导模型从面板描述生成布局的指令。具体来说,我们在教学中提供了多个场景布局的例子,以通过上下文学习加强LLMs的理解和规划能力。在这个过程中,我们要求LLMs不要使用代词,如“他,她,他们,它”来指代字符,而是指定每个主题的名称。这样,字符引用的模糊性就大大减少了。
[
σ
1
,
σ
2
,
⋅
⋅
⋅
,
σ
K
]
=
L
L
M
(
F
P
2
L
,
[
P
1
,
P
2
,
⋅
⋅
,
P
K
]
)
,
(
3
)
[\sigma_{1},\sigma_{2},\cdot\cdot\cdot,\sigma_{K}]=\mathrm{LLM}\left(F_{P2L},\left[P_{1},P_{2},\cdot\cdot,P_{K}\right]\right),\qquad\quad(3)
[σ1,σ2,⋅⋅⋅,σK]=LLM(FP2L,[P1,P2,⋅⋅,PK]),(3)
在等式(3)中,𝜎𝑖是𝑖-th面板的场景布局,其中global由一个全局提示𝑝𝑖和几个具有相应局部边界框的局部提示组成,即:
σ
i
=
{
p
i
S
l
o
b
a
l
,
(
p
i
1
l
o
c
a
l
,
b
i
1
)
,
(
p
i
2
l
o
c
a
l
,
b
i
2
)
,
…
⋅
(
p
i
k
i
l
o
c
a
l
,
b
i
k
i
)
}
,
(
4
)
\sigma_{i}=\left\{p_{i}^{\mathrm{Slobal}},\left(p_{i1}^{\mathrm{local}},b_{i1}\right),\left(p_{i2}^{\mathrm{local}},b_{i2}\right),\ldots\cdot\left(p_{\it i k_{i}}^{\mathrm{local}},b_{i k_{i}}\right)\right\},\quad(4)
σi={ piSlobal,(pi1local,bi1),(pi2local,bi2),…⋅(pikilocal,biki)},(4)
其中𝑘𝑖是𝑖-th story图像中的本地提示数。𝑝𝑖local𝑗和𝑏𝑖local𝑗分别是𝑖-th story图像中的𝑗-th本地提示符和边界框。全局提示描述了整个故事图像的全局上下文,而局部提示则专注于单个对象的细节。这种设计通过将故事图像生成的复杂性解耦为多个简单任务,帮助我们极大地提高了图像生成的质量。
六、密集条件生成
1.动机。
尽管使用稀疏边界框作为控制信号可以改善主题的生成并获得更合理的场景布局,但不能始终产生高质量的生成结果。在某些情况下,图像与场景布局不完全匹配,或者生成的图像质量不高。
我们认为这主要是由于边界框提供的信息有限。模型面临着在指导有限的情况下一次性生成大量内容的困难。为此,本文建议通过引入密集的草图或关键点指导来改进最终的故事图像生成。基于上一节生成的布局,设计了一个密集条件生成模块,如图2(d)所示。
2.主题生成
为了在不引入人工干预的情况下,将布局的稀疏边界框表示转化为密集的草图控制条件,首先根据local prompts,逐个生成布局中的单个对象。由于单对象生成的提示很简单,生成过程相对容易。因此,我们能够获得高质量的单目标生成结果。
3.提取每个主题的密集条件
在获得单个物体的生成结果后,我们使用openvocabulary目标检测方法Grouning-DINO对本地提示描述的物体进行定位,并获得定位框𝑏𝑖𝑑𝑗𝑒𝑡。然后,我们使用SAM 获得对象的分割掩码𝑚𝑖𝑗,𝑏𝑖𝑑𝑗𝑒𝑡是SAM的提示。随后,在T2I-Adapter之后,我们使用PidiNet 来获得掩模的外部边缘,它可以用作可控图像生成的密集草图。对于人体角色,我们也可以使用HRNet来获得人体姿态关键点作为密集条件。值得注意的是,生成的密集控制信号易于理解和操纵。因此,如果需要,用户可以很容易地手动调整生成的草图或关键点,以更好地与他们的意图保持一致。
4.构成稠密条件
最后,将得到的单个物体的密集控制条件粘贴到布局中对应的边界框区域,从而得到整个图像的密集控制条件,记为𝐶𝑖。一个潜在的问题是,由LLM生成的定位框的大小𝑏𝑖𝑗与groundin - dino方法检测到的定位框的大小𝑏𝑖𝑑𝑗𝑒𝑡不完全相同。为了解决这个问题,我们将𝑏𝑖𝑑𝑗𝑒𝑡内的密集控制条件缩放到𝑏𝑖𝑗的大小,以保持场景的全局布局不变。这个过程可以写成:
C
i
=
C
o
m
p
o
s
e
(
l
i
,
[
C
i
1
,
C
i
2
,
…
,
C
i
k
i
]
)
.
(
S
‾
)
C_{i}=\mathrm{Compose}\left(l_{i},\left[C_{i1},C_{i2},\dots,C_{i k_{i}}\right]\right).\qquad\qquad(\overline{ { {\bf S}}})
Ci=Compose(li,[Ci1,Ci2,…,Ciki]).(S)
请注意,组合密集条件的过程是全自动的,不需要任何人工交互。
七、可控讲故事图像生成
受限于模型中文编码器的语言理解能力,以及生成过程中文和图像区域之间不正确的关联,直接生成的图像往往会出现对象缺失、归属混淆等一系列问题。为解决这个问题,引入了额外的控制信号,以提高图像生成的质量。
1. 稀疏布局控制
在上文中,我们使用LLMs来获得故事图像的整体布局。本文生成故事图像的详细内容,遵循场景布局的指导。我们选择使用简单有效的区域样本方法,我们强制每个框内的图像潜在特征聚焦于相应的局部目标。因此,生成的图像确认了布局,也避免了对象之间的属性混淆。
2.密度控制
为了进一步提高图像质量,我们引入了上文中生成的密集条件来指导图像生成过程。具体来说,我们使用轻量级的T2I-Adapter来注入密集的控制信号。条件生成过程可以表示为:
D
M
(
ρ
i
g
l
o
b
a
l
;
σ
i
,
{
A
,
C
i
}
)
,
(
6
)
{\mathsf{D M}}\left(\rho_{i}^{g l o b a l};\sigma_{i},\left\{ {A,C_{i}}\right\}\right),\qquad\qquad\qquad\qquad\qquad\qquad(6)
DM(ρiglobal;σi,{ A,Ci}),(6)
其中𝐶𝑖是𝑖-th故事图像的密集条件,𝐴是用于密集控制的T2I-Adapter模型。我们的密集条件是自动生成的,从而消除了手工绘制草图的繁琐过程。
3.身份保护
角色身份的保留对于获得视觉上愉悦的故事可视化效果起着重要的作用。我们通过借鉴Mix-of-Show的思想来实现这一点,给定一个受试者的几张图像,对每个受试者的轻量级ED-LoRA权重进行微调,以捕捉详细的受试者特征。然后,应用梯度融合为单个角色合并多个ed - lora,以保证故事中所有角色的身份。融合后的LoRA权重记为Δ𝑊,最终的生成过程为:
D
M
(
p
i
g
l
o
b
a
l
;
σ
i
,
{
A
,
C
i
}
,
Δ
W
)
.
(
7
)
\mathrm{DM}\left(p_{i}^{g l o b a l};\;\sigma_{i},\{A,C_{i}\},\Delta W\right).\qquad\qquad\qquad\qquad(7)
DM(piglobal;σi,{ A,Ci},ΔW).(7)
八、消除按字符收集的数据
1.字符数据的要求
为了训练一个故事中角色的定制模型,我们需要几个角色的图像来进行模型微调。现有的故事可视化方法依赖于用户捕获的图像甚至数据集来训练定制的角色模型。为了消除繁琐的数据收集和自动化故事可视化,提出一种简单有效的方法来自动生成所需的训练数据。为了获得有效的单个字符定制模型,训练数据需要满足:(1)身份一致性,训练图像中字符的结构和纹理应该是一致的;(2)多样性,训练数据应该有所不同,例如视角不同,以避免模型过拟合。
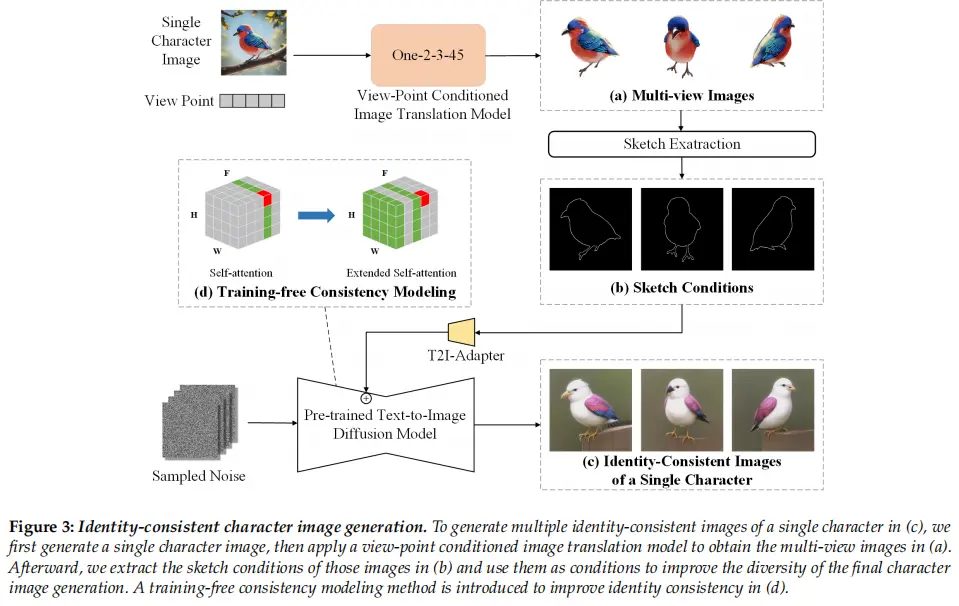
2. 标识的一致性
本文提出一种无需训练的一致性建模方法,以满足身份一致性的要求,如图3 (d)所示。将单个字符的多个图像视为视频中的不同帧,并使用预训练的扩散模型同时生成它们。在此过程中,生成模型中的自注意力被扩展到其他“视频帧”来加强图像之间的依赖关系,从而获得身份一致的生成结果。具体来说,在自注意力机制中,我们让每一帧中的潜在特征关注第一帧和前一帧的特征,以建立依赖关系。这个过程表示为:
Attn
(
W
Q
z
i
,
W
K
[
z
0
,
z
i
−
1
]
,
W
V
[
z
0
,
z
i
−
1
]
)
,
(
8
)
\operatorname{Attn}(W^{Q}z_{i},W^{K}[z_{0},z_{i-1}],W^{V}[z_{0},z_{i-1}]),~~~~~~~~~~~~(8)
Attn(WQzi,WK[z0,zi−1],WV[z0,zi−1]), (8)
其中𝑧𝑖是当前帧的潜在特征,𝑧0和𝑧𝑖−1分别是第一帧和前一帧的潜在特征。这里,[·,·]是拼接操作。
3.多样性
虽然上述方法可以保证所获得图像的身份一致性,但对于训练自定义模型而言,多样性还不够。为此,在不同的帧中注入不同的条件来增强生成的字符图像的多样性。为了获得这些不同但身份一致的条件,我们首先通过𝐼𝑖𝑐𝑜𝑛𝑑= DM(𝑝𝑖𝑠𝑢𝑏)生成单个图像,其中𝑝𝑖𝑠𝑢𝑏是由LLM生成的字符的描述。然后,我们使用预训练的视点条件图像平移模型来获取不同视点下的字符图像,如图3 (a)所示。最后,我们提取这些图像的草图或关键点作为控制条件。
l
i
j
c
o
n
d
=
f
(
I
i
c
o
n
d
,
R
i
j
,
T
i
j
)
,
j
=
1
,
2
,
⋅
⋅
⋅
,
n
.
(
9
)
\begin{array}{l l}{ {l_{i j}^{c o n d}=f\left(I_{i}^{c o n d},R_{i j},T_{i j}\right),j=1,2,\cdot\cdot\cdot,n.}}&{ {\qquad\qquad(9)}}\end{array}
lijcond=f(Iicond,Rij,Tij),j=1,2,⋅⋅⋅,n.(9)
然后,从这些图像中提取非人类角色的草图和人类角色的关键点。最后,在生成过程中使用T2I-Adapter将控制引导注入到对应帧的潜在特征中。
此外,为了进一步保证生成数据的质量,我们使用CLIP score对生成数据进行筛选,选择与文本描述一致的图像作为训练数据进行定制生成。
4.讨论
我们将提出的免训练身份一致性建模方法与视点条件图像翻译模型相结合,以实现角色生成中的身份一致性和多样性。一种更简单的方法是直接使用视点条件图像平移模型中的多视点图像作为自定义训练数据。然而,我们发现,直接生成的结果往往会产生失真,或者从不同的视角来看,图像的颜色和纹理有很大的差异。因此,我们需要利用上述一致性建模方法为每个字符获取纹理和结构一致的图像。
九 、实验
1.实现细节
使用了GPT-4作为LLM,Stable Diffusion进行文本到图像生成,T2I-Adapter进行密集控制。其中,只有多主题定制过程需要训练,其他部分都是无需训练的。多主题定制模型的训练需要20分钟的ED-LoRA训练和1小时的梯度融合。整个流程可以在几分钟内生成大量结果。
2.结果
AutoStory可以根据用户输入的文本和图像生成高质量、一致性强的故事图像。该方法可以根据用户输入的文本和图像生成灵活多样的角色姿势和场景,同时还能有效地生成故事中提到的小物品。即使只有文本输入,该方法仍然可以生成高质量的故事可视化结果,而且角色身份高度一致。
3. 与现有方法比较
比较方法
现有的故事可视化方法大多是针对数据集上的特定角色、场景和风格而设计的,无法应用于一般的故事可视化。为此,我们在这里主要比较可以归纳的方法,包括:TaleCraft、Custom Diffusion、paint-by-example、Make-A-Story。

质量比较
为了与现有的故事可视化方法进行正面对比,我们采用TaleCraft和Make-A-Story中的故事,如图5和图6所示。如图5所示,paint-by-example努力保持角色的身份。生成的图像中的女孩与用户提供的女孩图像有很大的不同。尽管Custom Diffusion在身份保持方面的表现稍好,但它有时会生成具有明显伪影的图像,例如第二张和第三张图像中扭曲的猫。TaleCraft取得了更好的图像质量,但仍然存在某些伪影,例如,第三张图像中的猫是扭曲的,第四张图像中女孩的一条腿缺失。AutoStory能够在身份保持、文本对齐和生成质量方面实现优越的性能。
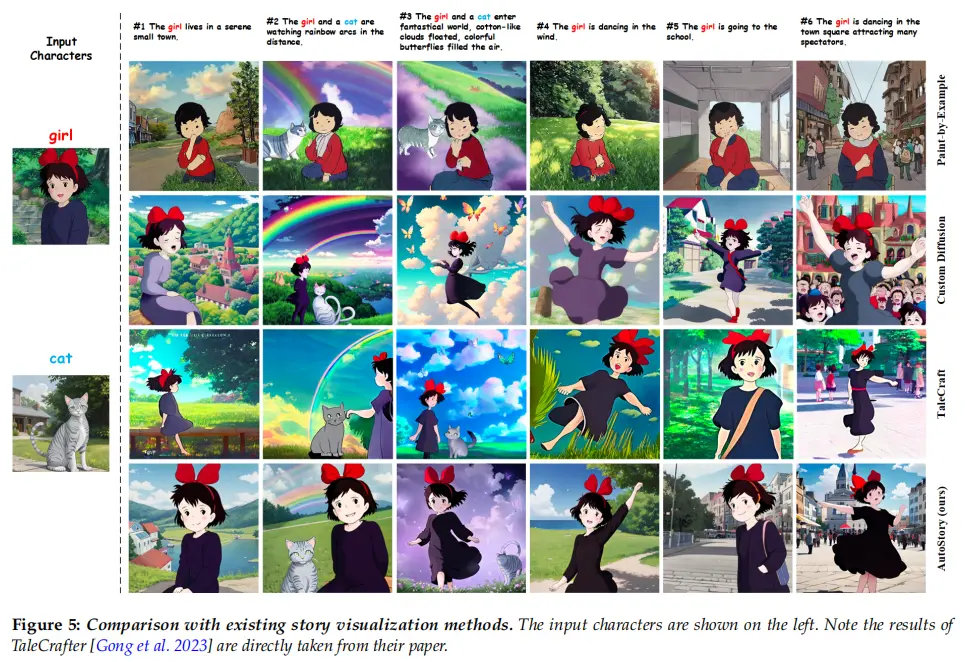

同样,在图6中可以看到,Make-A-Story生成的故事图像质量较低,这主要是因为它是为FlintstonesSV数据集量身定制的,因此内在地受到生成能力的限制。TaleCraft在生成质量方面有显著提高,但与文本的对齐程度有限,例如,第一张图像中丢失的手提箱。由于LLM强大的文本理解和布局规划能力,所提出方法能够得到文本对齐的结果。有趣的是,我们的AutoStory和TaleCraft在图像风格上存在显著差异。我们假设这主要是由用于训练的字符数据的差异引起的。
定量比较
我们考虑两个指标来评估生成的结果:1、文本到图像的相似性,由文本和图像嵌入在CLIP特征空间中的余弦相似性度量;2、图像到图像的相似性,由用于训练的字符图像的平均嵌入与生成的故事图像在CLIP图像空间中的嵌入之间的余弦相似性度量。结果如表1所示。AutoStory在文本到图像的相似性和图像到图像的相似性方面都明显优于现有方法,证明了所提出方法的优越性。

用户研究
对10个故事进行了用户研究,每个故事平均有7个提示。在研究过程中,32名参与者被要求从三个维度对故事可视化结果进行评价:1、文本和图像之间的对齐;2、图像中人物的身份保持;3、生成图像的质量。我们让用户给每组故事图片打分。每种方法的结果如表2所示。可以看出,AutoStory在所有三个指标上都明显优于竞争方法,这表明所提出方法更受用户的青睐。
4.消融分析
控制信号
实验结果表明,没有控制条件时,模型会生成缺失对象和混合不同对象属性的图像。添加布局控制可以显著减轻概念冲突,但仍存在缺失主体的问题。只添加密集控制条件可以有效地生成所有提到的实体,但角色之间的概念冲突仍然存在。最后,结合布局和密集条件控制可以避免对象遗漏和角色之间的概念冲突,生成高质量的故事图像。

多视角角色生成中的设计问题
通过对比基准方法,发现纯sd无法获得一致性的图像,而temporal-sd可以保持一致性但缺乏多样性,One-2-3-45虽然具有多样性但存在一些缺陷。而我们的方法能够在保持一致性的同时增强多样性,并且通过稳定扩散的图像先验来减轻One-2-3-45生成的图像的缺陷。

九、总结
AutoStory的主要目标是通过最小的人力投入来创建满足特定用户需求的多样化故事可视化。通过结合LLMs和扩散模型的能力,我们成功获得了文本对齐、身份一致和高质量的故事图像。此外,通过我们精心设计的故事可视化流程和提出的角色数据生成模块,我们的方法简化了生成过程,减轻了用户的负担,有效消除了用户进行繁重数据收集的需求。充分的实验证明,我们的方法在生成故事的质量和保留主题特征方面优于现有方法。此外,我们的优秀结果是在不需要耗时和计算昂贵的大规模训练的情况下实现的,易于推广到不同的角色、场景和风格。在未来的工作中,我们计划加快多概念定制过程,并使我们的AutoStory实时运行。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。